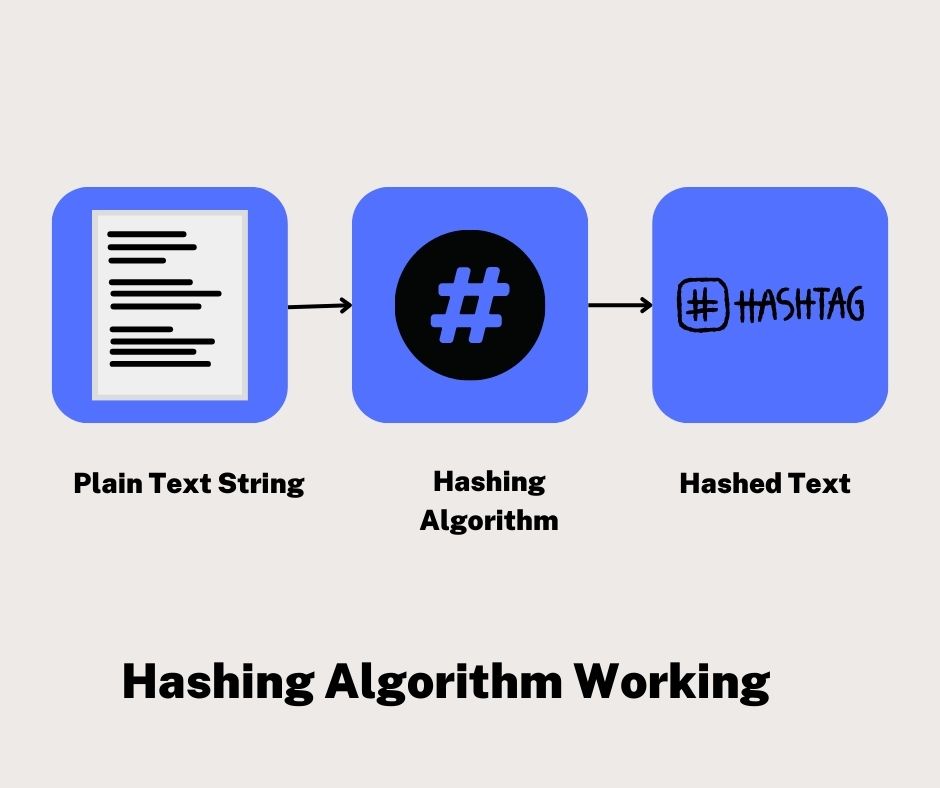
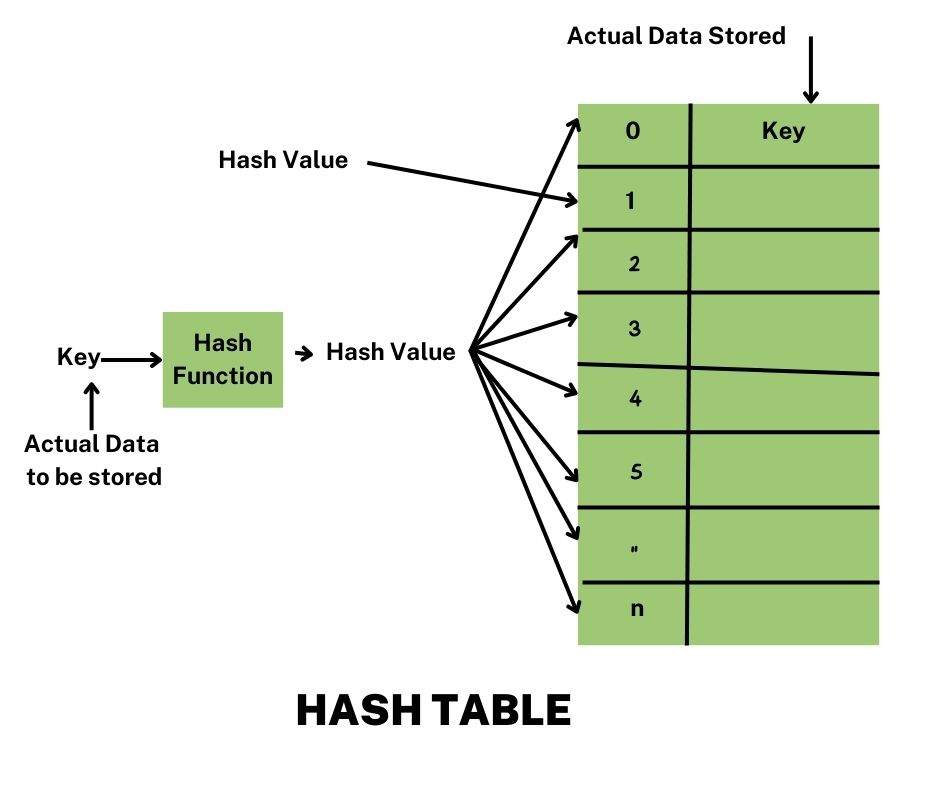
Hashing in data structures is the technique or practise of employing a hash function to map keys and values into a hash table.
It is done so that elements can be accessed more quickly.
The efficiency of mapping is determined by the effectiveness of the hash function used.
Let's say a hash function H(x) converts the value x in an Array to the index x percent 10.
For example, if the list of values is [11,12,13,14,15], it will be put in the array or Hash table at locations 1,2,3,4,5.
A hash table is a data structure that holds information in an associative manner.
Data access becomes very speedy if we know the index of the needed data.
As a result, regardless of data size, it becomes a data structure with incredibly fast insertion and search operations.
Hash Tables are arrays that use the hash technique to generate an index from which an element can be entered or located.
Hashing is the process of converting a given key into a smaller value that can be retrieved in O(1) time.
This is accomplished by using a function or technique known as a hash function to translate data to an encrypted or simplified representative value known as a "hash code" or "hash."
This hash is then used as an index to narrow down search criteria and swiftly retrieve data.
Hashing is a big improvement over DAT in terms of reducing space complexity.
We can simply feed the employee ID to our hash function, receive the hash code, and use it as a key to query through entries in our employee system example from the Introduction section.
Let's look at another example to show how hashing works.
Let's pretend we wish to map a list of string keys to string values solely as an example to help us understand the notion (for example, map a list of countries to their capital cities).
Assume we want to save the data in Table 1 of the map.
Assume that our hash function is just to take the length of the string.
-->
Key
Value
Cuba
Havana
England
London
France
Paris
Spain
Madrid
Switzerland
Berne
Assume that our hash function is just to take the length of the string.
We'll use two arrays to keep things simple: one for our keys and another for our data.
To add an item to the hash table, we first compute its hash code (in this case, simply count the amount of characters), then insert the key and value into the arrays at the appropriate index.
Cuba, for instance, has a hash code (length) of 4.
As a result, we place Cuba in the fourth position in the keys array, and Havana in the fourth index of the values array, and so on.
As a result, we arrive to the following:
-->
Position (hash=key length)
Key
Value
1
2
3
4
Cuba
Havana
5
Spain
Madrid
6
France
Paris
7
England
London
8
9
10
11
Switzerland
Berne
Now, in this specific case, everything works out rather nicely.
Our array must be large enough to hold the longest string, which is just 11 slots in our case.
And we do waste some space because our data contains no 1-letter keys or keys between 8 and 10 letters, for example.
However, in this scenario, the waste isn't as bad.
And just as getting the length of a string is quick, getting the value associated with a particular key is as well (definitely faster than conducting up to five string comparisons)1.
It's also clear that this strategy wouldn't work for storing random strings.
We would squander the majority of the space in the arrays if one of our string keys was a thousand characters long but the others were short.
More importantly, this model is incapable of dealing with collisions, i.e., what to do when more than one key has the same hash code (in this case, more than one string of a given length).
Taking the string length, for example, would be fairly meaningless if our keys were random English words.
Granted, the term "psuedoantidisestablishmentarianistically" would almost certainly be given its own category.
⌚ Are Hashing algorithms secure?
Secure Hashing Algorithms are a subset of hashing algorithms that provide security (SHAs).
These are also known as cryptographic hashing algorithms, and they're commonly employed in computer and cloud systems to secure any resource.
SHA256 is the most secure hashing algorithm available.
⌚ Who invented Hashing?
Hans Peter Luhn was the first to invent hashing in the 1940s.
In November 1958, he presented his work on hashing at a six-day international conference dedicated to scientific information.
⌚ How does Hashing work?
Hashing primarily works by using a function called "hash function" to convert data of any arbitrary size to a fixed-size value and storing it in a data structure called "hash table" at the value produced by hash functions.
Hash codes, digests, hash values, and hashes are all terms for the values returned by this function.
⌚Why the results of hashing cannot be reverted back to original input?
Hashing was developed with the security of any system in mind.
As a result, it is necessary for a decent hash function to be "one-way" so that hackers do not have easy access to sensitive information.
⌚ When is it not advisable to use Hashing/ Hash Tables?
🚀In general, hashing provides great time complexity for operations like as Insert, Search, and Delete.
🚀
Because hash tables take up more memory, it's better to use arrays for smaller applications.
🚀
Some operations, such as iterating through entries when the keys are inside a defined range, identifying the entry with the largest/smallest key, and so on, are not supported by hash tables.
Arrays are preferable in certain situations.
⌚ Where is Hashing used?
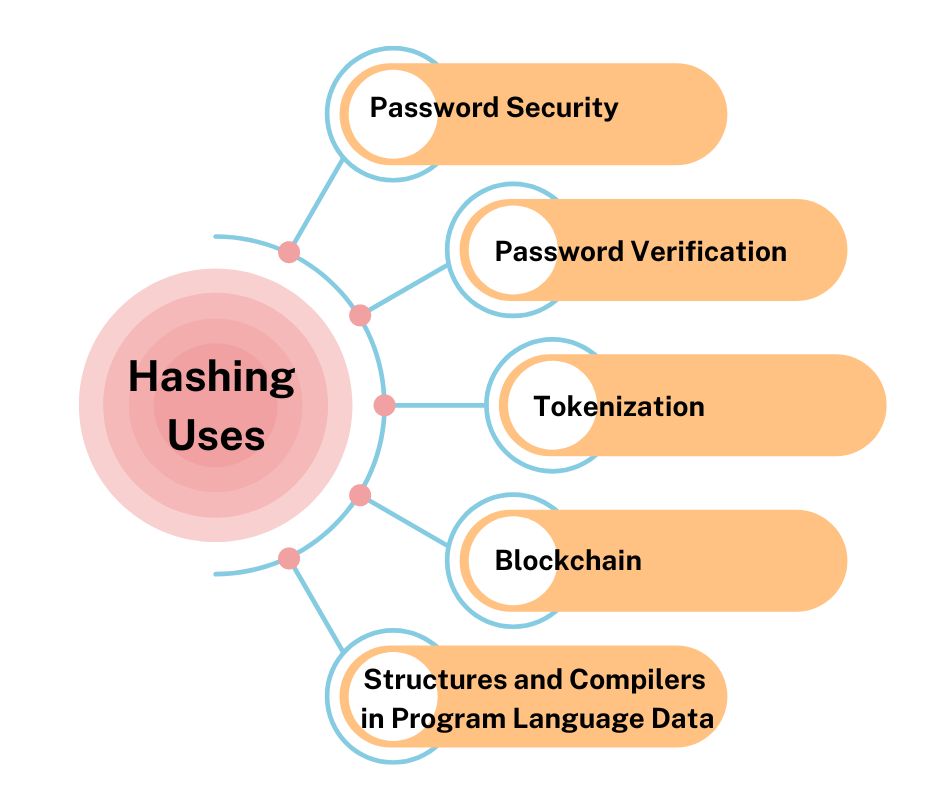
Hashing is widely utilised in a variety of applications, including password security, password verification, tokenization, programming language data structures and compilers, blockchain, machine learning feature hashing, and many others!
⌚ What is Load Factor?
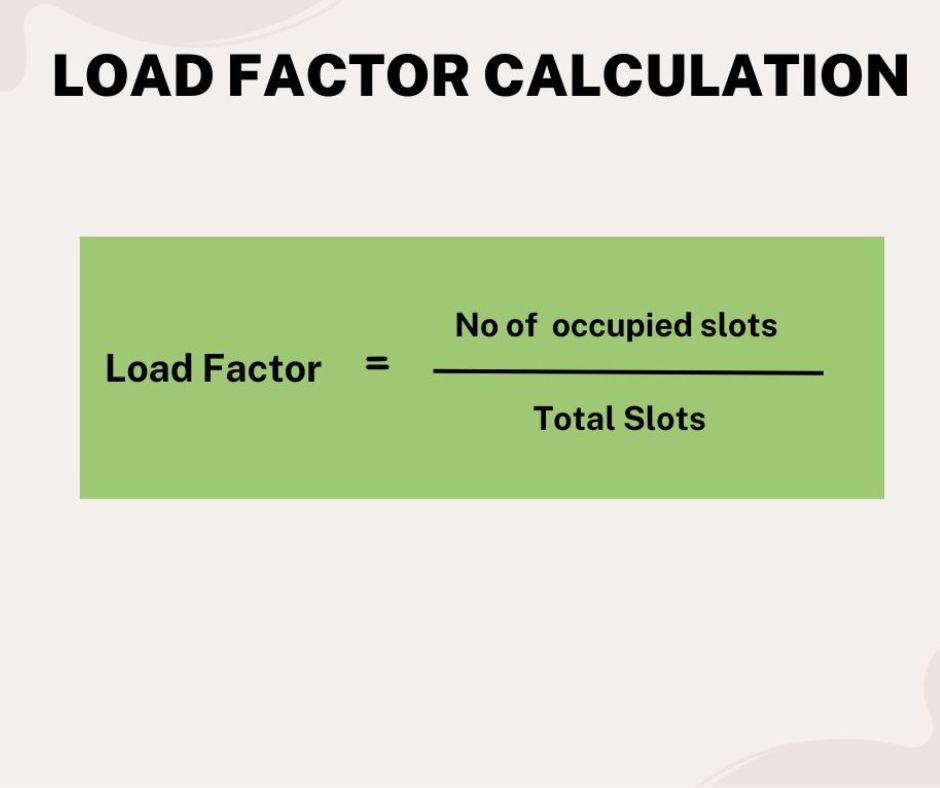
The load factor is essentially a measurement of how full (occupied) the hash table is, and is defined as: = number of occupied slots/total slots.
In basic terms, if we have a hash table with a capacity of 1000 slots and 500 slots occupied, the load factor is = 500/1000 = 0.5.
The higher the load factor value, the more space is conserved, but at the cost of chaining more items into a slot (We will learn about chaining in the below sections).
This would increase the time it takes for items to be accessed.
In general, when faced with the choice of whether time or space is more essential, humans prefer to optimise time (raising speed) over memory space.
The tradeoff between time and space is known as the time-space tradeoff.
-->
⌚ What are the Basic Operations that can be performed on hash map?
The main primary operations of a hash table are listed below.
🚀 Search :
Searches a hash table for a specific element.
🚀 Insert :
Insert is a function that adds a new element to a hash table.
🚀 Delete :
Removes an element from a hash table with the delete command.
⌚ What is Hash Method?
Hash Method define a hashing mechanism for calculating the data item's key hash code.
int hash_code(int k){
return k % size;
}
⌚ Applications of Hashing
Hashing's irreversibility and constant time access properties have found applications in a variety of domains.
The following are some examples of hashing applications:
🚀
Security and Verification of Passwords:
The advent of cryptographic hash functions, which deliver the hash value in encrypted format, is due to the property of "one-way" or "irreversible" hash functions.
🚀
Security:
When we use any website for the first time that requires our authentication via "Sign Up," we need to be certain that our account does not fall into the wrong hands, where we enter our credentials to access the accounts that belong to us.
As a result, the password entered is stored in the database as a hash.
🚀 Verification: The next time we try to log in to the website, the password hash is computed and submitted to the server, which verifies whether the password belongs to us.
The hash value is sent so that there is no possibility of sniffing when data is sent from client to server.
🚀Data Structures: Hashing is extensively used in programming languages to define and develop data structures.
HashMap in Java, unordered map in C++, and so on.
🚀 Development of Compilers:
Compilers for programming languages save all of the keywords (such as if, else, for, while, return, and so on) that are used by that language in the form of a hash table so that the compiler can quickly determine which keywords need to be compiled during the compilation process.
🚀
Digests of Messages:
This is yet another use of cryptographic hashes.
Consider the case when you save your files and data on cloud services.
Now you must ensure that your files are not tampered with by third-party cloud service providers.
We do it by employing cryptographic hashing algorithms to compute the hash of the file/data.
For reference, we keep these computed hashes on our local workstations.
We can compute the hash of the files immediately the next time we download files from cloud storages.
We compare it to the previously computed locally stored hash.
If the service providers tampered with the file, the hash value of the file would undoubtedly alter.
The hash values of the downloaded file and the locally saved value should be identical if it hasn't been tampered with.
SHA256 is the most widely used cryptographic algorithm.
These algorithms are also known as digest algorithms.
The files in the preceding example are regarded as a message.
🚀
Other applications include the Rabin Karp algorithm, calculating the frequency of characters in a word, generating git commit codes with the git tool, and caching.
Hashing is extensively used in Blockchain, Machine learning for feature hashing, storing objects or files in AWS S3 Buckets, indexing on databases for faster retrieval, and many other applications!
⌚ What is DataItem?
DataItem Define a data item with some data and a key that will be used to do a hash table search.
struct Data_Item {
int data;
int key;
};
⌚Search Operation
Calculate the hash code of the key supplied and use that hash code as an index in the array to discover it whenever an element has to be found.
If the element isn't at the computed hash code, apply linear probing to move it forward.
struct Data_Item *search(int key) {
//get the hash
int hash_Index = hash_Code(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hash_Index]->key == key)
return hashArray[hash_Index];
++hash_Index;
hash_Index %= SIZE;
}
return NULL;
}
⌚Insertion Opeartion
-->
Whenever an element needs to be inserted, calculate the hash code of the key supplied, then use that hash code as an index in the array to retrieve the index.
Use linear probing for empty places if an element is located at the computed hash code.
void insert(int key,int data) {
struct Data_Item *item = (struct Data_Item*) malloc(sizeof(struct Data_Item));
item->data = data;
item->key = key;
//get the hash
int hash_Index = hash_Code(key);
//move in array until an empty or deleted cell
while(hash_Array[hash_Index] != NULL && hash_Array[hash_Index]->key != -1) {
//go to next cell
++hash_Index;
//wrap around the table
hash_Index %= SIZE;
}
hash_Array[hash_Index] = item;
}
⌚ Deleteion Operation
Calculate the hash code of the passed key and use it as an index into the array whenever an element needs to be removed.
Use linear probing to get an element ahead if it is not found at the computed hash code.
When you find it, replace it with a dummy item to maintain the hash table's performance.
struct Data_Item* delete(struct Data_Item* item) {
int key = item->key;
//get the hash int hash_Index = hash_Code(key);
//move in array until an empty
while(hash_Array[hash_Index] !=NULL) {
if(hash_Array[hash_Index]->key == key) {
struct Data_Item* temp = hash_Array[hash_Index];
//assign a dummy item at deleted position
hash_Array[hash_Index] = dummyItem;
return temp;
}
//go to next cell
++hash_Index;
//wrap around the table
hash_Index %= SIZE;
}
return NULL;
}
⌚What is Hash Function?
A Hash Function is a fixed process that turns a key to a hash key.
This function maps a key to a value of a specific length, which is referred to as a Hash value or Hash.
The hash value is a representation of the original string of characters, however it is usually smaller.
It sends both the hash value and the signature to the recipient after transferring the digital signature.
The same hash function is used by the receiver to compute the hash value, which is then compared to the value received with the message.
The message is sent without errors if the hash values are the same.
The properties of a good hash function are as follows:
1) Computable in a cost-effective manner.
2) The keys should be distributed evenly (Each table position equally likely for each key)
⌚ What is Hash table?
A hash table, sometimes known as a hash map, is a data structure for storing key-value pairs.
It's a grouping of goods kept together to make it easier to locate them later.
It computes an index into an array of buckets or slots from which the requested value can be located using a hash function.
It's a collection of lists, each of which is referred to as a bucket.
It has a value that is based on the key.
The map interface is implemented using a hash table, which extends the Dictionary class.
Only unique elements are stored in the hash table, which is synchronised.
⌚ Collision Handling
Because a hash function returns a small number for a large key, it's possible that two keys will return the same value.
Collision occurs when a newly inserted key maps to an existing occupied space in a hash table and must be dealt with using a collision handling mechanism.
The following are some options for dealing with collisions:
Chaining: The goal is to have each hash table cell point to a linked list of records with the same hash function value.
Chaining is straightforward, but it necessitates additional memory outside of the table.
Open Addressing: All items are kept in the hash table itself with open addressing.
Either a record or NIL can be found in each table item.
When looking for an element, we go through the table slots one by one until we find the necessary element or it's obvious that the element isn't in the table.
⌚ Linear Probing
One type of open addressing is linear probing.
Because each cell in the hash table comprises a key-value pair, when a new key is mapped to a cell already filled by another key, the linear probing technique searches for the closest unoccupied places and adds a new key to that empty cell.
In this situation, searching is done in a sequential manner, beginning at the point where the collision occurs and continuing until the vacant cell is not discovered.
Let's have a look at an example of linear probing.
Consider the following linear probing example:
Where m = 10 and h(k) = 2k+3 and A = 3, 2, 9, 6, 11, 13, 7, 12
The indexes 9, 7, 1, 5 are used to store the key values 3, 2, 9, 6.
The estimated index value for 11 is 5, which is already used by another key value, 6.
Because the nearest empty cell to the index 5 is 6 when linear probing is used, the value 11 will be added to the index 6.
The number 13 is the next crucial value.
When the hash function is used, the index value associated with this key value is 9.
At index 9, the cell is already filled.
Because the nearest empty cell to the index 9 is 0 when linear probing is used, the value 13 will be added to the index 0.
The following key value is 7.
When the hash function is used, the index value associated with the key value is 7.
At index 7, the cell is already filled.
Because the nearest empty cell to the index 7 is 8 when linear probing is used, the value 7 will be added to the index 8.
The number 12 is the next key value.
When the hash function is used, the index value associated with the key value is 7.
At index 7, the cell is already filled.
Because the nearest empty cell to the index 7 is 2 when linear probing is used, the value 12 will be added to the index 2.
⌚ Double Hashing
Double hashing is a collision-avoidance approach that uses open addressing.
When a collision occurs, this approach uses the key's secondary hash.
It moves ahead using one hash value as an index until the empty spot is discovered.
Two hash functions are employed in double hashing.
Assume that one of the hash algorithms used to generate the locations is h1(k), and that another hash function is h2(k).
"Insert ki at first free spot from (u+v*i) percent m where i=(0 to m-1)," it says.
In this scenario, u is the hash function-calculated position, and v is equal to (h2(k) percent m).
⌚ Quadratic Probing
In the case of linear probing, the search is carried out in a linear manner.
Quadratic probing, on the other hand, is an open addressing technique that searches for an empty slot using a quadratic polynomial.
It can also be described as allowing the insertion of ki from (u+i2) percent m to m-1 at the first free place.
⌚ How hashing works
Two steps are necessary to enter a key(K) - value(V) pair into a hash map:
A hash function is used to turn K into a tiny integer (its hash code).
The hash code is used to find an index (hashCode percent arrSize), and the complete linked list at that index is first inspected for the presence of the K already (Separate chaining).
If it is discovered, its value is updated, and if it is not, the K-V pair is added to the list as a new node.
⌚ Complexity and Load Factor
The time it takes to complete the first step is determined by the K and the hash function.
If the key is a string like "abcd," the hash function may be affected by the length of the string.
However, for very large values of n, the number of entries in the map, the length of the keys is virtually small in comparison to n, hence hash computation can be assumed to run in constant time, i.e. O. (1).
The second step entails traversing the list of K-V pairs that exist at that index.
The worst-case scenario is that all n entries are at the same index.
As a result, the temporal complexity would be O. (n).
However, enough study has been done to ensure that hash functions distribute the keys in the array uniformly, so this nearly never occurs.
So, on average, if there are n entries and b is the array size, each index will have n/b entries.
This n/b figure is known as the load factor, and it represents the load on our map.
This Load Factor must be kept low in order to reduce the amount of entries in each index.
⌚Rephrasing
As the name implies, rehashing means hashing once more.
The complexity of a system grows as the load factor exceeds its pre-defined value (the default load factor is 0.75).
To avoid this, the array is twice in size, and all of the values are hashed and saved in the new double-sized array to keep the load factor and complexity low.
⌚ Why Rephrasing?
The rationale for rehashing is because the load factor rises when key value pairs are inserted into the map, meaning that the time complexity climbs as well, as noted previously.
This may not provide the time complexity that O requires (1).
As a result, rehash is required, with the bucketArray's size increased to lower the load factor and temporal complexity.
⌚ How Rehashing is done?
The following is an example of rehashing:
After adding a new entry to the map, check the load factor.
Rehash if it's bigger than the pre-defined value (or the default value of 0.75 if none is specified).
Make a new bucketarray that is double the size of the previous one for Rehash.
Then go through each element in the old bucketArray, calling insert() on each to add it to the new larger bucket array.
⌚Advantages of Double hashing
Double hashing has the advantage of being one of the better forms of probing, resulting in a consistent distribution of records across a hash table.
This method does not produce any clusters.
It is one of the most effective collision-resolution methods.
⌚ Index Mapping Method
"Index Mapping (or Trivial Hashing)" is the simplest form of hashing technology.
Here:
Consider an array in which the value of each array location corresponds to a key from a provided set of keys.
When the number of keys is modest, this strategy is quite successful.
It assures that assigning one array slot for each conceivable key is cost-effective.
The hash function just accepts the input and returns the same value as the output in this case.
This works because it assumes that any retrieval will take only O(1) time.
However, because it assumes that the values are integers, this strategy is very simple and inefficient to employ in real-world settings.
⌚Division method
For hash functions, we map each key into a hash table slot by dividing the remainder of the key by the total table size available, i.e. h(key) = key percent table length => h(key) = key MODULO table length.
This approach is the most widely used and is relatively quick because it uses a single division step.
Things to remember while utilising the division method:
For optimal performance, certain table sizes are avoided.
For instance, the table's size should not be a power of a specific number, say r, so that if table length = rp, h(key) can accommodate p lowest-order bits of key.
Unless we are certain that all low-order p-bit patterns are equally likely, we must ensure that the hash function we construct is dependent on all bits of the key.
According to research, the hash function derived from the division approach produces the best results when the table size is prime.
h(key) = sum of binary representation of characters in key percent table length if table length is prime and r is the number of potential character codes on a system such that r percent table length = 1.
⌚ Min Square Method
Let's say we need to store a record with the key 3101 and the hash table's size is 2000.
The key is squared first, and the middle half of the resultant number is used as the hash table index.
So, key = 3101 => (3101)2 = 3101*3101 = 9616201 in our case.
h(key) = h(3101) = 162 h(key) = h(3101) = 162 h(key) = h(3101) = 162 h( (by taking middle 3 digit from 9616201).
Place the entry in the hash table's 162nd index.
⌚ Multiplication method?
The implementation of the hash function in this method is as follows:
We multiply key key by a real number c in the range 0 c 1 and retrieve the fractional component of their product.
The size of the hash table table size is then multiplied by this fractional component.
The final hash is determined by the result's floor.
The key benefit of this strategy is that the table size (table size) variable is irrelevant.
This figure is usually chosen as a power of two since it is simple to implement on most computing systems.
⌚Load factor
The load factor is essentially a measurement of how full (occupied) the hash table is, and is defined as: = number of occupied slots/total slots.
In basic terms, if we have a hash table with a capacity of 1000 slots and 500 slots occupied, the load factor is = 500/1000 = 0.5.
The higher the load factor value, the more space is conserved, but at the cost of chaining more items into a slot (We will learn about chaining in the below sections).
This would increase the time it takes for items to be accessed.
In general, when faced with the choice of whether time or space is more essential, humans prefer to optimise time (raising speed) over memory space.
This is referred to as the time-space tradeoff.
⌚ Advantages of Separate Chaining:
In terms of implementation, this strategy is fairly straightforward.
Because linked lists allow insertion in constant time, we can guarantee that the insert operation will always take O(1) time.
We don't have to be concerned about the hash table filling up.
Any number of elements can be added to the chain at any time.
This approach is less sensitive to the hash function or load factors, or is not as reliant on them.
When we don't know how many or how often the keys will be inserted or deleted, we usually utilise this strategy.
⌚ Disadvantages of Separate Chaining:
Chaining requires more memory to create and maintain linkages.
It's possible that certain elements of the hash table will never be used.
This, in theory, contributes to space waste.
In the worst-case situation, all of the keys to be inserted could be from the same bucket.
This would produce a linked list structure, with a search time of O. (n).
Because we're storing keys in the form of a linked list, the chaining cache's performance isn't fantastic.
Because all keys are guaranteed to be stored in the same table, open addressing strategies provide greater cache performance.
⌚Open Adressing
We ensure that all records are kept in the hash table itself using this strategy.
The table's size must be equal to or greater than the total number of keys available.
If the array becomes too small, we extend the table's size by transferring old data as needed.
In this technique, how do we handle the following operations?
Take a look at the following:
When we try to insert a key into a bucket that is already full, we keep probing the hash table until we find an empty slot.
We slide the key into the empty slot once we've found it.
Search(key): We keep probing until the slot's value doesn't equal key or an empty slot is found while looking for key in the hash table.
Delete(key): If we just delete a key when conducting a delete action, the search operation for that key may fail.
As a result, deleted key slots are marked as "deleted" so that the status of the key may be determined when it is searched.
The term "open addressing" refers to the fact that the hash value of a key does not indicate its address or location.
⌚ Implementation of Hashing in C++
DECLARATION :
unordered_map<int, int>mp; //declares an empty map
if (mp.find(Key) != mp.end()) mp.erase(mp.find(Key));
OR mp.erase(Key);
⌚ Implementation of Hashing in Java
DECLARATION :
HashMap<Integer, Integer> mp = new HashMap<Integer, Integer>(); / //declares an empty map
INSERTING kEY - VALUE :
mp.put(key, value);
SEARCHING KEY
mp.get(Key) // null if the key K is not present
mp.containsKey(Key) tells if the key K is present.
FINDING SIZE
mp.size();
ERASE FROM THE MAP
mp.remove(Key);
⌚ Implementation of Hashing in Python
DECLARATION :
mp={} //declares an empty map
INSERTING kEY - VALUE :
mp[key]= value;
SEARCHING KEY
mp[key] tells if the key K is present.
FINDING SIZE
len(mp);
ERASE FROM THE MAP
del mp[key];
🚀Conclusion
Hashing was created to address the challenge of quickly locating or storing an item in a collection.
For example, if we have a list of 10,000 English words and want to see if a specific term is on the list, it would be inefficient to compare the word to each of the 10,000 items until we discover a match.
Hashing is a strategy for increasing efficiency by efficiently restricting the search at the start.
Good luck and happy learning!
Frequently Asked Questions (FAQs)
• Hashing is a technique used in data structures to efficiently store and retrieve data. It involves using a hash function to map data elements to unique indices in an
array, which is typically called a hash table or hash map. The hash function takes the data element as input and produces a hash value or hash code, which is an integer.
• The hash code is then used as an index to store the data element in the hash table. Ideally, the hash function should distribute the data elements uniformly across the array, minimizing
collisions (i.e., cases where two or more elements map to the same index).
• When storing a data element, the hash function is applied to calculate the hash code. If there is no collision, meaning the calculated index is not already occupied, the data element is
stored at that index in the hash table. If a collision occurs, different techniques can be used to handle it, such as chaining or open addressing.
• Chaining involves maintaining a linked list at each index of the hash table. If multiple elements map to the same index, they are appended to the linked list at that index. When
retrieving a data element, the hash function is applied again, and the linked list is traversed to find the desired element.
• Open addressing, on the other hand, involves finding an alternative index for the colliding element within the hash table itself. Various methods, like linear probing or quadratic
probing, can be used to locate the next available index. If the calculated index is occupied, the probing technique iterates until an empty slot is found.
• Hashing provides constant-time average-case complexity for insertion, deletion, and retrieval operations, assuming a good hash function and a properly sized hash table. It is commonly
used in many applications, including databases, caches, symbol tables, and language dictionaries, to provide fast access to data based on a key or identifier.
Hashing is a concept in computer science that involves transforming data into a fixed-size value, called a hash code or hash value, using a hash function. This hash
code acts as a unique identifier for the data and is used to efficiently store, retrieve, and search for data in various applications. Here's an explanation of the concept
of hashing with an example:
Consider a scenario where you need to store a collection of employee records, each containing the employee's name, ID, and salary. Instead of storing the records in a linear data
structure like an array or a linked list, you can use hashing to create a more efficient storage and retrieval mechanism.
1. Hash Function Selection:
- The first step is to choose an appropriate hash function. The hash function should convert the employee ID into a unique hash code that maps to a specific location in memory or an
array (hash table).
- For example, let's consider a simple hash function that takes the employee ID and calculates the remainder when divided by the size of the hash table. The hash function could be
defined as `hash_code = employee_ID % table_size`.
2. Creating the Hash Table:
- Based on the number of employee records you expect to store, you create a hash table of appropriate size. The size of the hash table is typically chosen to balance memory utilization
and collision avoidance.
- For instance, let's assume a hash table size of 100, meaning it has 100 slots or buckets to store the employee records.
3. Inserting Employee Records:
- To insert an employee record into the hash table, you apply the hash function to the employee's ID to obtain the corresponding hash code.
- Using the hash code as an index, you store the employee record at the appropriate slot in the hash table.
- For example, if the employee ID is 12345 and the hash code is calculated as `12345 % 100 = 45`, you store the record at slot 45 of the hash table.
4. Retrieving Employee Records:
- When you want to retrieve an employee record based on their ID, you apply the hash function to the ID to obtain the hash code.
- Using the hash code as an index, you access the corresponding slot in the hash table to retrieve the employee record.
- Continuing the example, if you want to retrieve the employee with ID 12345, you calculate the hash code as `12345 % 100 = 45` and access slot 45 in the hash table to retrieve the
record.
5. Handling Collisions:
- Collisions occur when two or more employee records have the same hash code, resulting in the need to store multiple records in the same slot of the hash table.
- To handle collisions, different collision resolution techniques can be used, such as separate chaining or open addressing.
- In separate chaining, each slot of the hash table contains a linked list or another data structure to store multiple records with the same hash code.
- In open addressing, if a collision occurs, the algorithm probes for the next available slot using a predefined sequence until an empty slot is found.
In summary, hashing allows for efficient storage and retrieval of data by mapping it to unique hash codes using a hash function. This concept reduces the search space, enabling fast
access to desired data elements. Hashing is widely used in various applications such as databases, caches, password storage, compiler symbol tables, and cryptography to improve
performance and optimize memory utilization.
There are several types of hashing techniques used in computer science, each with its own characteristics and suitability for different scenarios. Here are some
commonly used types of hashing:
1. Division Hashing:
- Division hashing is a basic hashing technique that uses the modulo operator (%) to compute the hash code. It calculates the remainder when the key is divided by the size of the hash
table.
- The hash function for division hashing can be defined as `hash_code = key % table_size`.
- Division hashing is simple and easy to implement. However, it may lead to poor distribution of hash codes if the table size is not carefully chosen.
2. Multiplication Hashing:
- Multiplication hashing is a more advanced technique that uses multiplication and bit manipulation to generate the hash code.
- The hash function for multiplication hashing can be defined as `hash_code = (a * key) >> (w - k)`, where 'a' is a constant, 'w' is the number of bits in the key, and 'k' is the
number of bits used for the hash code.
- Multiplication hashing provides better distribution of hash codes compared to division hashing and is less sensitive to table size.
3. Folding Hashing:
- Folding hashing involves breaking the key into smaller parts and combining them using a specific folding technique.
- The key is divided into equal-sized sections, and these sections are combined using techniques like bit-wise XOR or addition to generate the hash code.
- Folding hashing helps distribute the hash codes more evenly, especially when the keys have a pattern or structure.
4. Polynomial Rolling Hashing:
- Polynomial rolling hashing is commonly used in string matching algorithms, such as the Rabin-Karp algorithm.
- It treats the key as a polynomial with each character's ASCII value as the coefficient.
- The hash code is computed by evaluating the polynomial using a rolling technique, where the contribution of the first character is subtracted, and the contribution of the new
character is added.
- Polynomial rolling hashing allows efficient matching of substrings by comparing the hash codes instead of the actual string content.
5. Cryptographic Hashing:
- Cryptographic hashing algorithms, such as MD5, SHA-1, SHA-256, etc., are designed for data integrity and security.
- These hash functions produce fixed-length hash codes, often with a larger bit size.
- Cryptographic hashing ensures properties like collision resistance, where it is computationally infeasible to find two different inputs that produce the same hash code.
- These hash functions are widely used in applications like data verification, password storage, digital signatures, and secure communication.
6. Perfect Hashing:
- Perfect hashing aims to eliminate collisions entirely by generating a hash function that guarantees unique hash codes for every key in the data set.
- It involves a two-level hash table structure, where the first level determines a primary hash function, and each bucket in the first level contains a separate secondary hash table.
- Perfect hashing is suitable for scenarios where the set of keys is known in advance and remains static.
It's important to select a hashing technique based on the specific requirements of the application, such as the distribution of keys, expected size of the data set, collision avoidance,
and performance considerations. The choice of a hashing technique can significantly impact the efficiency and effectiveness of data storage and retrieval operations.
Hashing is used in various areas of computer science and software engineering due to its ability to provide efficient storage, retrieval, and search operations. Here
are some key applications of hashing:
1. Data Retrieval:
- Hashing is commonly used in data structures like hash tables, hash maps, and dictionaries to store and retrieve data efficiently.
- In these data structures, data elements are mapped to unique hash codes using a hash function, allowing for constant-time average retrieval and storage operations.
- Hashing is ideal for scenarios where fast access to data based on a key is required, such as in databases, caches, and symbol tables.
2. Data Integrity and Verification:
- Cryptographic hashing algorithms, such as MD5, SHA-1, and SHA-256, are used to ensure data integrity and verify the authenticity of data.
- Hash functions generate fixed-length hash codes that uniquely represent the data, allowing for efficient verification of data integrity.
- These hash codes are widely used in applications like checksumming, file integrity checks, digital signatures, and secure communication protocols.
3. Password Storage:
- Hashing is crucial for secure password storage. Instead of storing passwords in plaintext, they are hashed and stored in databases.
- When a user logs in, their entered password is hashed and compared to the stored hash code.
- This ensures that even if the database is compromised, the passwords remain protected since it is computationally infeasible to reverse-engineer the original password from its hash
code.
4. Caching:
- Hashing is utilized in caching mechanisms to store frequently accessed data.
- Cache memory uses hash tables to store key-value pairs, allowing for efficient lookup and retrieval of data.
- By caching data using a hash-based structure, redundant computations or expensive disk/database accesses can be avoided, leading to improved performance.
5. String Matching:
- Hashing plays a crucial role in string matching algorithms like Rabin-Karp and KMP (Knuth-Morris-Pratt).
- These algorithms use rolling hash techniques, where hash codes of substrings are calculated incrementally to efficiently compare strings and search for occurrences.
- Hashing allows for efficient substring matching by comparing the hash codes, eliminating the need for comparing entire string contents.
6. Indexing and Searching:
- Hashing is used in search engines, databases, and information retrieval systems to create indexes for efficient searching.
- By using hash functions to generate hash codes for documents, keywords, or other identifiers, these systems can quickly locate relevant data based on user queries.
7. Network Routing:
- Hashing techniques are employed in network routing algorithms to distribute network traffic across multiple paths or servers.
- Hash codes derived from source or destination IP addresses, port numbers, or other packet attributes help determine the routing path and ensure even distribution of network traffic.
In summary, hashing finds wide application in various domains, including data retrieval, data integrity, password storage, caching, string matching, indexing, searching, and network
routing. Its ability to provide efficient storage, retrieval, and search operations makes it a valuable technique in managing and manipulating data in computer systems.
Hashing serves two primary functions: data retrieval and data integrity. Let's explore each function in detail:
1. Data Retrieval:
- One of the main functions of hashing is to enable efficient data retrieval. Hashing provides a mapping between data elements and their corresponding storage locations, allowing for
quick access and retrieval of data based on a key.
- To achieve data retrieval, a hash function is used to generate a unique identifier or hash code for each data element. This hash code is used as an index to determine the storage
location or bucket where the data element should be stored or retrieved.
- The hash function aims to distribute the data elements uniformly across the available storage locations to minimize collisions and ensure efficient retrieval.
- With a well-implemented hashing mechanism, data retrieval can be achieved in constant time on average, regardless of the size of the data set. This makes hashing an efficient
solution for scenarios that require fast access to data, such as in databases, caches, and symbol tables.
2. Data Integrity:
- Hashing also plays a crucial role in ensuring data integrity. Hash functions are used to generate fixed-length hash codes or hash values that uniquely represent the data being hashed.
- When data is hashed, even a small change in the input data results in a significantly different hash code.
- By comparing the hash codes of two sets of data, it is possible to verify if they are identical or different. This property is utilized for data integrity checks, verification, and
authentication purposes.
- Hash codes can be used to detect changes or tampering in data during transmission or storage. If the hash code of the received data matches the computed hash code, it can be
concluded that the data has not been altered.
- Hashing is widely used in applications such as checksumming, file integrity checks, digital signatures, and secure communication protocols to ensure data integrity and verify the
authenticity of the data.
By serving these two functions, hashing provides efficient data retrieval and helps ensure data integrity, making it a fundamental concept in various areas of computer science and
software engineering.
The term "hashing" in computer science is derived from the concept of a hash function, which is the fundamental component of hashing techniques. The term "hash" itself
refers to a jumbled mix or mishmash. Let's explore why it is called hashing in more detail:
1. Origin of the Term:
- The term "hashing" has its origins in mathematics and cryptography.
- In mathematics, "hash" originally referred to a specific type of function called a hash function, which is used to transform or map data from one domain to another, often resulting
in a jumbled output.
- Cryptography adopted the term "hash" to describe the output of hash functions, which are used to ensure data integrity and provide secure message digests.
2. Hash Functions:
- Hash functions are at the core of hashing techniques. They take an input, such as data or a key, and generate a fixed-size output called a hash code or hash value.
- Hash functions typically produce an output that appears random and disordered, even though it is deterministically derived from the input.
- The output of a hash function is often considered a "hashed" or "hashed value" due to its jumbled nature.
3. Hash Codes and Storage:
- In the context of data storage and retrieval, hashing involves using hash codes or hash values as unique identifiers to map data elements to specific locations in memory or a data
structure (e.g., a hash table).
- The hash codes act as "keys" or "addresses" to quickly locate and access the associated data.
- The process of calculating a hash code and using it for storage and retrieval operations is referred to as hashing.
4. Analogy with Physical Hashing:
- An analogy can be drawn between the concept of hashing in computer science and the physical act of hashing, such as chopping or grinding ingredients in cooking.
- When ingredients are hashed or chopped, they are broken down into smaller pieces, resulting in a mixture of fragments.
- Similarly, in hashing, data elements are transformed into hash codes, representing a jumbled mix or mishmash of data.
- The analogy highlights the notion of breaking down or transforming data into a unique representation through a hash function.
In summary, the term "hashing" in computer science is derived from the concept of a hash function, which produces a jumbled output from an input. It is associated with the generation of
hash codes or hash values used for data storage and retrieval. The term "hashing" captures the idea of transforming data into a disordered mix, reflecting the essence of hash functions
and their applications in computer science.
Hashing provides several advantages in computer science and software engineering. Here are the key advantages of hashing:
1. Efficient Data Retrieval:
- Hashing enables efficient data retrieval by mapping data elements to specific storage locations based on their unique identifiers (hash codes).
- With a well-implemented hash function and hash table structure, data retrieval can be achieved in constant time on average, regardless of the size of the data set.
- This makes hashing ideal for scenarios that require fast access to data, such as in databases, caches, and symbol tables.
2. Fast Search and Lookup Operations:
- Hashing enables fast search and lookup operations by reducing the search space.
- The use of hash codes as unique identifiers allows for direct access to the location where the desired data is stored, eliminating the need for sequential searching.
- This results in significant time savings, especially when dealing with large datasets or when searching for specific data based on a key.
3. Memory Efficiency:
- Hashing can be memory-efficient since it only requires memory allocation for the actual data elements and not a fixed-size array.
- Hash tables dynamically allocate memory for data elements, adapting to the size of the data set, and avoiding the need to allocate a large contiguous memory block.
- This flexibility in memory allocation reduces memory wastage and allows for optimal memory utilization.
4. Collisions Handling:
- Hashing provides collision resolution techniques to handle cases where multiple data elements produce the same hash code.
- Techniques like separate chaining or open addressing allow for the efficient storage and retrieval of colliding data elements within the same storage location.
- With effective collision resolution, the impact of collisions on retrieval performance is minimized, maintaining the efficiency of hash-based data structures.
5. Data Integrity:
- Hashing ensures data integrity by providing a mechanism to verify the integrity and authenticity of data.
- Hash codes generated by hash functions serve as unique identifiers for data elements, and any change in the data results in a different hash code.
- By comparing the hash codes of original and received data, it is possible to detect any alteration or tampering in the data, ensuring the integrity and authenticity of the
information.
6. Flexibility in Key Types:
- Hashing techniques can be applied to a wide range of data types as long as a suitable hash function is available.
- Hash functions can be designed to accommodate different key types, including strings, integers, objects, or complex data structures.
- This flexibility allows for efficient storage and retrieval of various types of data in a uniform manner.
In summary, hashing provides advantages such as efficient data retrieval, fast search and lookup operations, memory efficiency, collision handling, data integrity verification, and
flexibility in handling different key types. These advantages make hashing a valuable technique for optimizing data storage, retrieval, and manipulation in a wide range of applications,
improving performance and memory utilization.
Hashing and encryption are two distinct concepts used in computer science and information security. While they both involve transforming data, they serve different
purposes and have different characteristics. Let's explore the difference between hashing and encryption:
1. Purpose:
- Hashing: The primary purpose of hashing is data integrity and verification. Hashing transforms data into a fixed-size hash code or hash value using a hash function. It ensures that
even a small change in the input data will result in a significantly different hash code. Hashing is used to verify the integrity of data, detect tampering or changes, and provide
assurance that the data has not been altered.
- Encryption: The primary purpose of encryption is to protect the confidentiality of data. Encryption transforms data into ciphertext using an encryption algorithm and a key. It
ensures that the original data is concealed and can only be accessed or deciphered by authorized parties who possess the corresponding decryption key. Encryption is used to secure
sensitive data during transmission or storage.
2. Reversibility:
- Hashing: Hashing is a one-way process. Once data is hashed and transformed into a hash code, it cannot be reversed or decrypted to obtain the original data. Hash functions are
designed to be computationally irreversible, meaning it is practically infeasible to retrieve the original data from the hash code. The focus is on generating a unique identifier for
the data rather than preserving its original form.
- Encryption: Encryption is a reversible process. The original data can be recovered by applying the decryption algorithm with the correct decryption key. Encryption ensures that the
data remains confidential and can be securely transmitted or stored while allowing authorized parties to access the original data.
3. Use of Keys:
- Hashing: Hashing does not involve the use of keys. The hash function operates on the input data directly, generating a hash code that represents the data. The same input will always
produce the same hash code.
- Encryption: Encryption relies on the use of keys. An encryption algorithm operates on the data and a specific encryption key to generate ciphertext. The same data will produce
different ciphertexts with different keys. Decryption requires using the corresponding decryption key to revert the ciphertext back to the original data.
4. Data Recovery:
- Hashing: As hashing is a one-way process, it does not support data recovery or retrieval. Hash codes cannot be reversed to obtain the original data. Hashing is primarily used for
data integrity checks and verification rather than data storage or transmission.
- Encryption: Encryption supports data recovery by applying the decryption process using the correct decryption key. Authorized parties can retrieve the original data from the
ciphertext.
5. Focus on Data:
- Hashing: Hashing focuses on generating unique identifiers for data and verifying data integrity. The emphasis is on detecting any changes or tampering in the data.
- Encryption: Encryption focuses on securing the confidentiality of data during transmission or storage. The emphasis is on preventing unauthorized access and ensuring only authorized
parties can decipher the data.
In summary, hashing and encryption serve different purposes and have distinct characteristics. Hashing focuses on data integrity and verification, using one-way hash functions to generate
hash codes. Encryption focuses on data confidentiality, using encryption algorithms and keys to transform data into ciphertext that can be reversed back to the original data with the
correct decryption key.
There are numerous hash functions available, each with its own characteristics and suitability for different applications. However, let's discuss three commonly used
hash functions:
1. MD5 (Message Digest Algorithm 5):
- MD5 is a widely used hash function that produces a 128-bit hash value.
- It takes an input message and applies a series of bitwise operations and transformations to generate the hash code.
- MD5 was originally designed for cryptographic applications but is now primarily used for non-cryptographic purposes like checksumming and data integrity checks.
- One limitation of MD5 is its vulnerability to collision attacks, where different inputs produce the same hash code. As a result, it is not recommended for security-sensitive
applications.
2. SHA (Secure Hash Algorithm) Family:
- The SHA family includes several hash functions, such as SHA-1, SHA-256, SHA-384, and SHA-512.
- SHA-1 produces a 160-bit hash value, while SHA-256, SHA-384, and SHA-512 generate hash values of 256, 384, and 512 bits, respectively.
- The SHA algorithms apply a series of logical and bitwise operations to the input message, resulting in the hash code.
- SHA-1 was widely used in the past but is now considered weak and prone to collision attacks. The SHA-2 family (including SHA-256, SHA-384, and SHA-512) is more secure and commonly
used in various applications.
- SHA-3 is another hash function family that is newer and not as widely adopted as SHA-2. It includes hash functions like SHA3-224, SHA3-256, SHA3-384, and SHA3-512.
3. CRC (Cyclic Redundancy Check):
- CRC is a hash function commonly used for error detection in data transmission.
- It operates by treating the data as a binary polynomial and performing polynomial division.
- The resulting remainder (checksum) is the CRC value appended to the data. The receiver can calculate the CRC value of the received data and compare it with the transmitted CRC value
to detect errors.
- CRC is fast and efficient for error detection but is not suitable for cryptographic or security-related applications.
It's important to note that the selection of a hash function depends on the specific requirements of the application, such as the desired hash length, collision resistance, computational
efficiency, and security considerations. When designing or implementing a system that uses hash functions, it is crucial to select a suitable algorithm based on the specific needs and
potential threats in the given context.
Hashing is not a form of encryption. While both hashing and encryption involve the transformation of data, they serve different purposes and have distinct
characteristics. Let's explore the differences between hashing and encryption in detail:
1. Purpose:
- Hashing: The primary purpose of hashing is data integrity and verification. Hashing transforms data into a fixed-size hash code or hash value using a hash function. It ensures that
even a small change in the input data will result in a significantly different hash code. Hashing is used to verify the integrity of data, detect tampering or changes, and provide
assurance that the data has not been altered.
- Encryption: The primary purpose of encryption is to protect the confidentiality of data. Encryption transforms data into ciphertext using an encryption algorithm and a key. It
ensures that the original data is concealed and can only be accessed or deciphered by authorized parties who possess the corresponding decryption key. Encryption is used to secure
sensitive data during transmission or storage.
2. Reversibility:
- Hashing: Hashing is a one-way process. Once data is hashed and transformed into a hash code, it cannot be reversed or decrypted to obtain the original data. Hash functions are
designed to be computationally irreversible, meaning it is practically infeasible to retrieve the original data from the hash code. The focus is on generating a unique identifier for
the data rather than preserving its original form.
- Encryption: Encryption is a reversible process. The original data can be recovered by applying the decryption algorithm with the correct decryption key. Encryption ensures that the
data remains confidential and can be securely transmitted or stored while allowing authorized parties to access the original data.
3. Use of Keys:
- Hashing: Hashing does not involve the use of keys. The hash function operates on the input data directly, generating a hash code that represents the data. The same input will always
produce the same hash code.
- Encryption: Encryption relies on the use of keys. An encryption algorithm operates on the data and a specific encryption key to generate ciphertext. The same data will produce
different ciphertexts with different keys. Decryption requires using the corresponding decryption key to revert the ciphertext back to the original data.
4. Data Recovery:
- Hashing: As hashing is a one-way process, it does not support data recovery or retrieval. Hash codes cannot be reversed to obtain the original data. Hashing is primarily used for
data integrity checks and verification rather than data storage or transmission.
- Encryption: Encryption supports data recovery by applying the decryption process using the correct decryption key. Authorized parties can retrieve the original data from the
ciphertext.
In summary, while both hashing and encryption involve transforming data, they serve different purposes. Hashing focuses on data integrity and verification, generating hash codes that
uniquely identify data and ensuring data has not been tampered with. Encryption focuses on data confidentiality, transforming data into ciphertext to protect its secrecy and ensuring only
authorized parties can access the original data.
Hashing has various applications across different domains due to its ability to provide data integrity, efficient data storage, and fast retrieval. Here are some
common applications where hashing is used:
1. Data Integrity and Verification:
- Hashing is widely used to ensure data integrity and verify the authenticity of data.
- Cryptographic hash functions like SHA-256, SHA-3, and MD5 are employed to generate hash codes that uniquely represent data.
- Hash codes are used to verify that data has not been altered or tampered with during transmission or storage.
- Applications include checksumming, file integrity checks, digital signatures, and secure communication protocols.
2. Password Storage:
- Hashing plays a crucial role in securely storing passwords.
- Instead of storing passwords in plaintext, they are hashed using strong hash functions like bcrypt, Argon2, or PBKDF2.
- When a user logs in, their entered password is hashed and compared to the stored hash code to authenticate the user.
- Hashing ensures that even if the password database is compromised, the original passwords remain protected.
3. Data Structures:
- Hashing is widely used in various data structures to provide efficient storage and retrieval of data.
- Hash tables, hash maps, and dictionaries use hash codes to map keys to specific locations for quick access and retrieval.
- These data structures are commonly used in databases, caches, symbol tables, and indexing structures.
4. Caching:
- Hashing is employed in caching mechanisms to store frequently accessed data.
- Cache memory uses hash tables to store key-value pairs, allowing for efficient lookup and retrieval of data.
- By caching data using a hash-based structure, redundant computations or expensive disk/database accesses can be avoided, leading to improved performance.
5. String Matching and Searching:
- Hashing techniques like Rabin-Karp and KMP (Knuth-Morris-Pratt) use rolling hash functions to efficiently search for patterns or substrings within text.
- By calculating hash codes incrementally, these algorithms compare hash values to quickly identify potential matches, reducing the need for comparing entire string contents.
6. Content Addressing:
- Content-addressable storage (CAS) systems use hashing to uniquely identify and retrieve data based on its content.
- Hash codes are used as addresses or keys to locate and retrieve specific content, regardless of its location or filename.
- CAS systems are used in distributed file systems, version control systems, and content delivery networks (CDNs).
7. Network Routing:
- Hashing techniques are employed in network routing algorithms to distribute network traffic across multiple paths or servers.
- Hash codes derived from source or destination IP addresses, port numbers, or other packet attributes help determine the routing path and ensure even distribution of network traffic.
These are just a few examples of how hashing is utilized in various applications. The versatility of hashing makes it a valuable tool in ensuring data integrity, optimizing data storage
and retrieval, securing passwords, efficient searching, content addressing, and load balancing in network systems.
While hashing has numerous advantages, it also has some limitations and potential disadvantages. Let's explore them in detail:
1. Collision Possibility:
- One of the main challenges in hashing is the potential for collisions, where different inputs produce the same hash code.
- Due to the finite number of possible hash codes and the infinite number of potential inputs, collisions are inevitable.
- Collisions can impact the efficiency and performance of hash-based data structures, as it requires additional handling and resolution techniques.
- A poor hash function or an uneven distribution of inputs can increase the likelihood of collisions.
2. Irreversibility:
- Hashing is a one-way process, meaning it is computationally infeasible to reverse the hash code and retrieve the original data.
- While this property ensures data integrity, it also limits the ability to recover the original data from the hash code.
- This can be a disadvantage in certain scenarios where data recovery is necessary, such as when using irreversible hash functions for storing passwords.
3. Lack of Data Ordering:
- Hashing does not provide inherent data ordering. The hash function distributes data elements across the available storage locations randomly or based on the hash code.
- As a result, there is no natural ordering or sequencing of the data elements within the hash-based data structure.
- If the order of data elements is important for a particular application, additional mechanisms need to be implemented to maintain ordering.
4. Memory Overhead:
- Hashing can incur memory overhead, particularly in hash-based data structures like hash tables.
- Hash tables require additional memory to store the hash codes, pointers or references to data elements, and collision resolution structures.
- The memory usage can increase further when dealing with a large number of elements or when handling collisions.
5. Limited Key Types:
- Hashing requires a suitable hash function that can handle the specific key type being hashed.
- Some hash functions are designed for specific data types, such as strings or integers, while others can handle a wider range of data types.
- The availability of hash functions for different key types can vary, limiting the flexibility of hashing for certain types of data.
6. Security Considerations:
- While hashing is valuable for data integrity checks and checksumming, it is not designed for cryptographic purposes.
- Hash functions like MD5 and SHA-1 have known vulnerabilities to collision attacks, making them unsuitable for security-sensitive applications.
- For cryptographic purposes, specialized hash functions like SHA-256, SHA-3, or HMAC should be used instead.
It's important to consider these disadvantages and limitations when applying hashing techniques. Understanding the characteristics and potential challenges associated with hashing helps
in making informed decisions regarding the choice of hash functions, collision resolution strategies, and suitability for specific applications.
TEST YOUR KNOWLEDGE!
1. What is the definition of a hash table?
2. What is it called when numerous elements compete for the same bucket in a hash table?
3. What is the definition of direct addressing?
4. How difficult is it to find something in direct addressing?
5. What is a hash function, and how does it work?
6. Which of the following is not a collision avoidance technique?
7. What is the load factor, and what does it mean?
8. What is the definition of simple uniform hashing?
9. What is the search complexity in simple uniform hashing?
10. What data structure is best for simple chaining?