
What is GROUP BY statement in SQL?
The GROUP BY statement, for example, "identify the number of consumers in each country," i.e, it groups rows with the same values into summary rows. To group the result set by one or more columns, the GROUP BY statement is frequently used with aggregate functions (COUNT(), MAX(), MIN(), SUM(), AVG()).
GROUP BY Syntax
SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s) ORDER BY column_name(s);
Example Query to understand GROUP BY
Let's understand GROUP BY by taking one example,
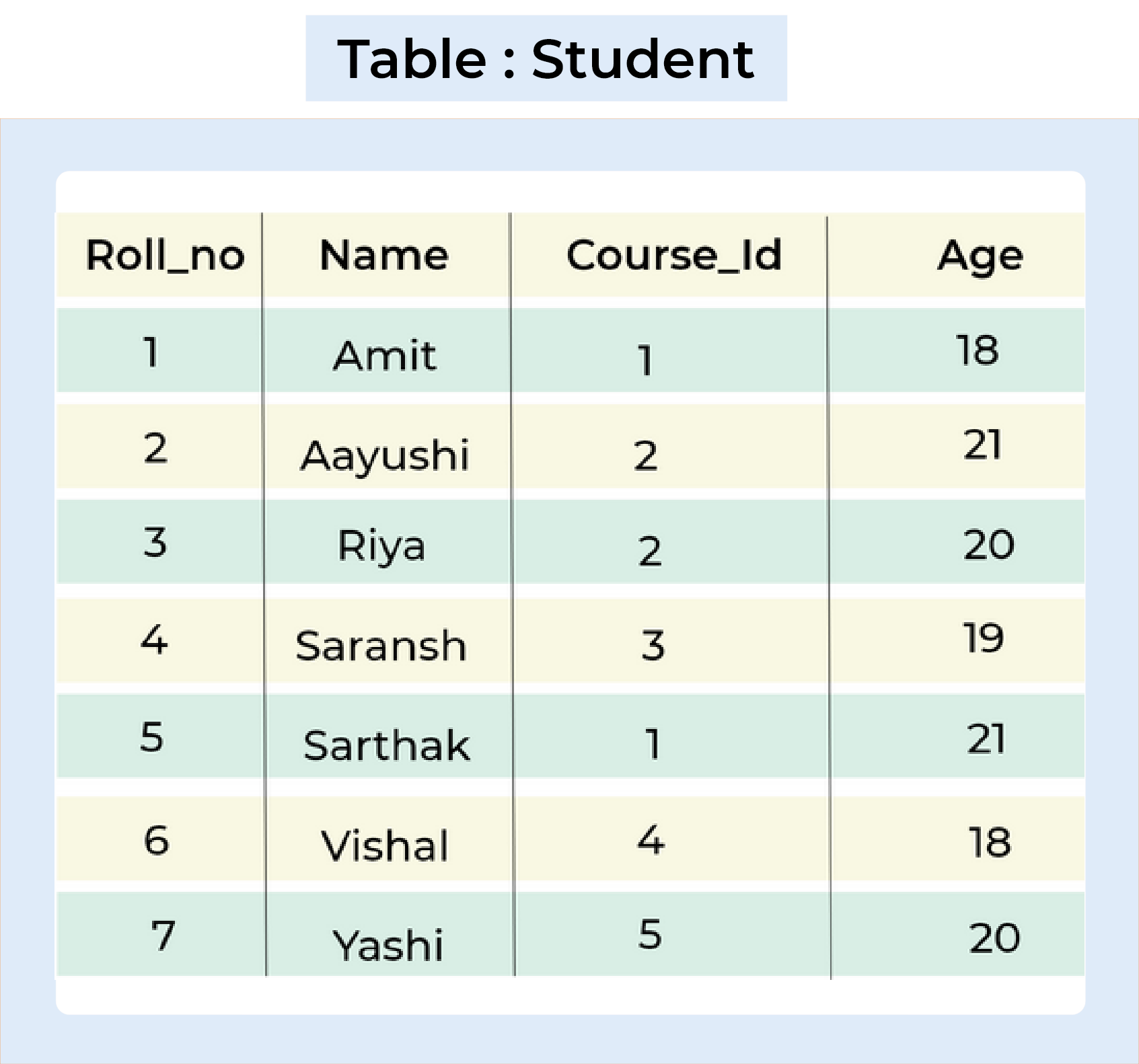
Query :
SELECT COUNT(Roll_no), Course_ID FROM Student GROUP BY Course_ID
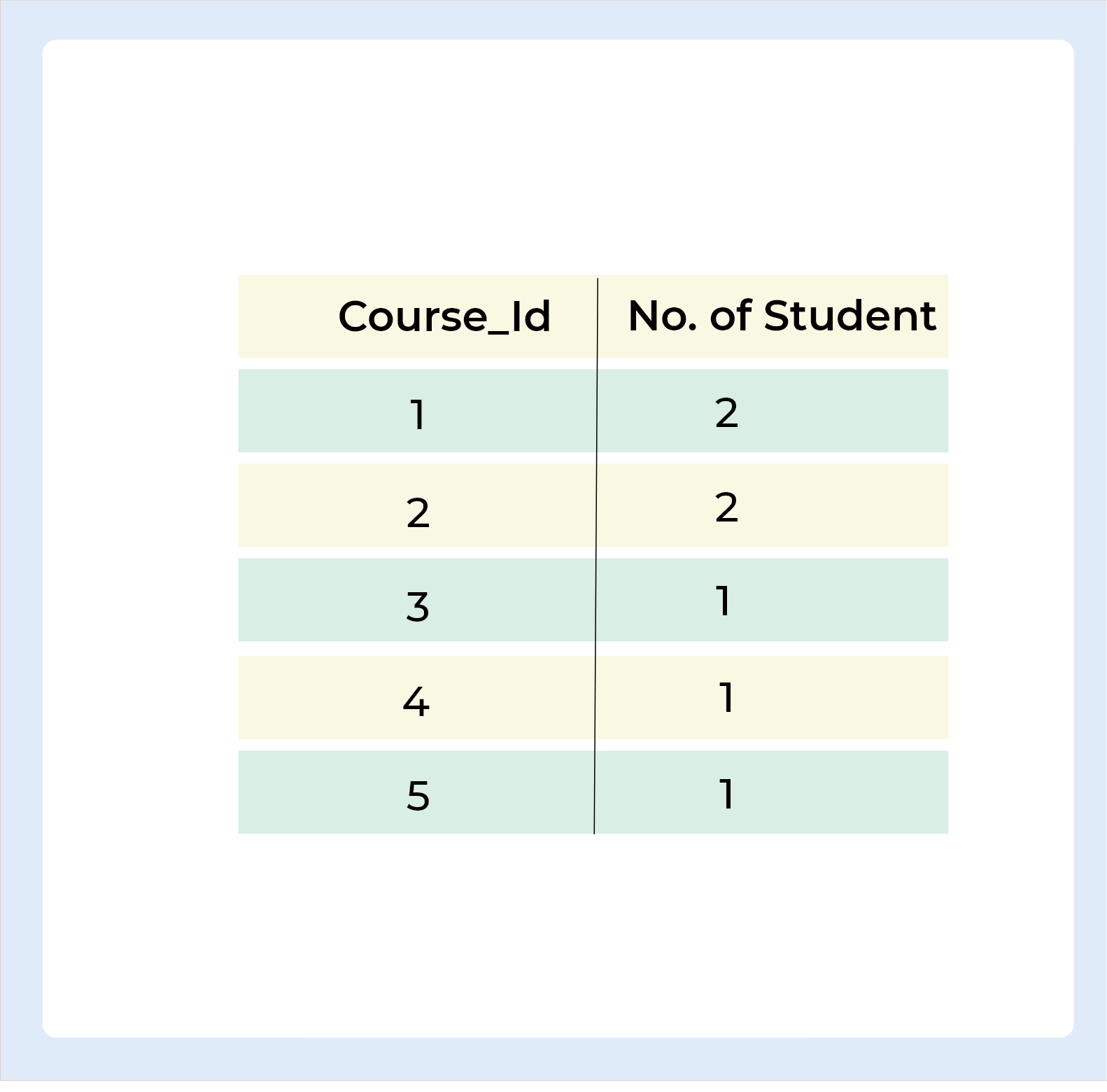
Output
The following SQL Query lists the number of students in each course
With this article at Logicmojo, you must have the complete idea of GROUP BY in SQL.