Java Collections are one-stop shops for all data manipulation tasks such data storage, searching, sorting, insertion, deletion, and updating. A Java collection replies
as a single object, and a Java Collection Framework offers a variety of Interfaces and Classes.
So there you have it: everything you need to know about Java Collections. Java Collections come in handy when working with real-time data. Following a solid comprehension
of Java Collections, having a basic understanding of how to become a Software Developer is critical.
So, let’s dive deep into the surplus of useful Java Collections questions.
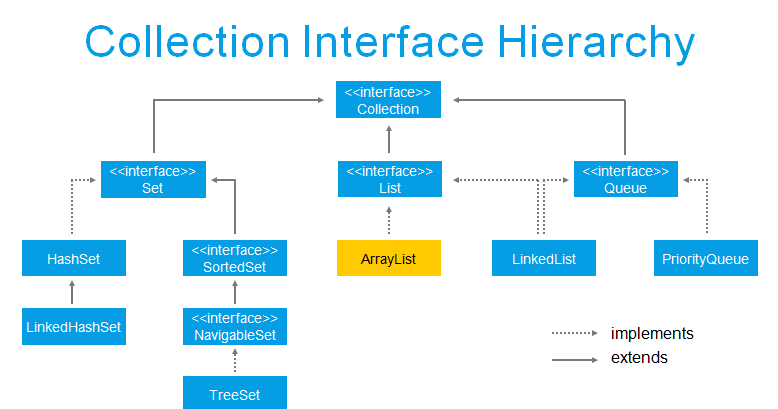
The Collection Framework is a set of classes and an interface
for storing and manipulating data in the form of objects. It does so by providing classes like ArrayList, Vector, Stack, and HashSet, as well as interfaces like List, Queue, and Set.
What's the need?
Arrays, Vectors, and Hash Tables were the usual approaches for aggregating Java objects (or collections) prior to the advent of Collection Framework (or JDK 1.2). For all
of these collections, there was no common interface. As a result, while all of the collections have the same basic aim, their implementation differs and there is no correlation
between them. Furthermore, users find it difficult to remember all of the different methods, syntax, and constructors that each collection class contains.
⌚ What are the primary differences between an array and a collection?
Array and Collection are comparable in terms of storing object references and manipulating data, but they differ in a number of ways. The key differences between
an array and a Collection are as follows:
• Arrays have a fixed size, which means that a user cannot modify the length of the array according to their needs or during runtime, however with Collections,
the size can be modified dynamically as needed.
• Collections can hold heterogeneous things, whereas Arrays can only store homogenous or similar type objects.
• Arrays are unable to provide ready-made solutions for user needs such as sorting, searching, and so on, but Collections do.
• Arrays are not preferred over Collections when it comes to memory.
⌚ What are the various interfaces that the Collection framework employs?
The Java Collection Framework implements a number of interfaces,
the most commonly used of which are the Collection and Map interfaces (java.util.Map). The following is a list of Collection Framework interfaces:
🚀 Iterable interface: This is the main interface for the collection framework. The collection interface extends the iterable interface. As a result, this interface is implemented by
default in all interfaces and classes. The primary goal of this interface is to provide an iterator for the collections. As a result, there is just one abstract method in this
interface.
🚀 Collection Interface: This interface, which extends the iterable interface, is implemented by the collection framework's classes. This interface includes all of the basic collecting
methods, such as adding data, removing data, clearing data, and so on. This interface includes all of these methods since they are utilised by all classes, regardless of how they are
implemented. Including these methods in this interface also ensures that method names are uniform across all collections. In conclusion, we can say that this interface
forms the foundation for collection class implementation.
🚀 List interface: The list interface is a child interface of the collection interface. This interface is dedicated to list data, in which all of the objects in an ordered collection
can be stored. This also allows for duplicated data to exist. A number of classes, such as ArrayList, Vector, Stack, and others, implement this list interface. We can build a list
object using any of these classes because they all implement the list.
🚀 Queue Interface: The FIFO (First In First Out) order of a real-world queue line is followed by a queue interface. This interface is used to store all elements where the
order of the elements matters. When we go shopping, for example, we are given bills on a first-come, first-served basis. As a result, the person who makes the initial request
receives the bill first. There are classes like PriorityQueue, Deque, ArrayDeque, and others. We can use any of these subclasses to generate a queue object because they all
implement the queue.
🚀 Deque Interface: Its data structure differs slightly from that of the queue. A deque, also known as a double-ended queue, is a data structure that allows components to be
added and deleted from both ends. This interface adds to the queue interface. This interface is implemented by the class ArrayDeque. We can use this class to generate a deque object
because it implements the deque.
🚀 Set Interface: A set is an unsorted collection of objects in which no duplicate values can be stored. This collection is used when we want to avoid duplication of
items and only keep the ones that are unique. A number of classes implement this set interface, including HashSet, TreeSet, LinkedHashSet, and others. Because they all
implement the set, we can make a set object using any of these classes.
🚀 Map Interface: A Map (java.util.Map) is a type of element storage that stores key-value pairs. The Collection interface is not implemented by the Map interface. It
can only have one unique key, but duplicate elements are allowed. Map interface and Sorted Map are the two interfaces that implement Map in Java.
⌚ What are some of the benefits of using the Collection framework?
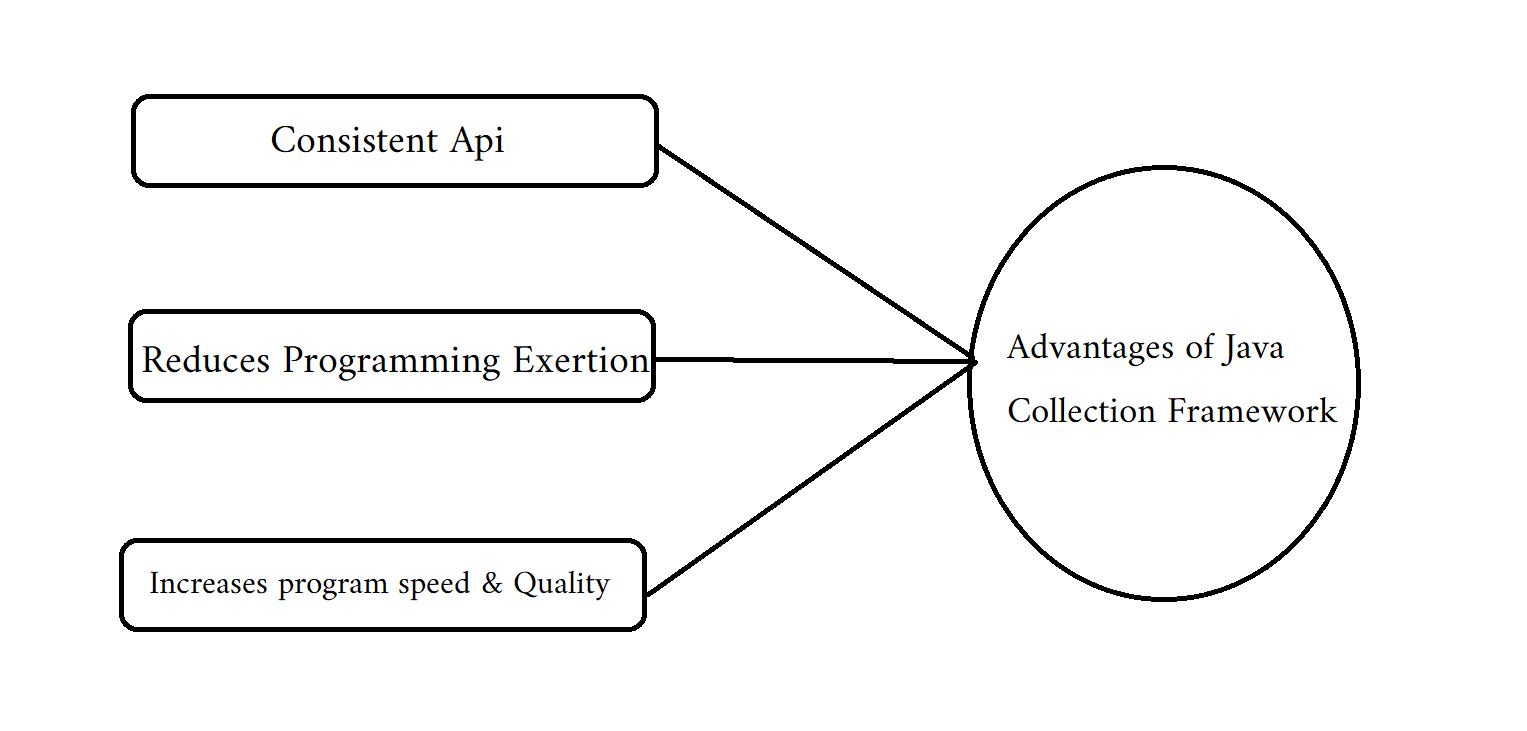
Consistent API: The API has a core set of interfaces, such as Collection, Set, List, or Map, and all of the classes that implement these interfaces (ArrayList, LinkedList, Vector, and so on)
share a common set of methods.
Cuts programming effort: A programmer can focus on how to use the Collection in his programme rather than worrying about its design. As a result, the fundamental Object-oriented programming idea
(i.e. abstraction) has been successfully utilised.
Improves programme speed and quality by providing high-performance implementations of useful data structures and algorithms. In this case, the programmer does not have to worry about
the best way to implement a data structure. They can simply use the best implementation to dramatically increase their program's performance.
⌚ Difference between ArrayList and Vector?
ArrayList
Vector
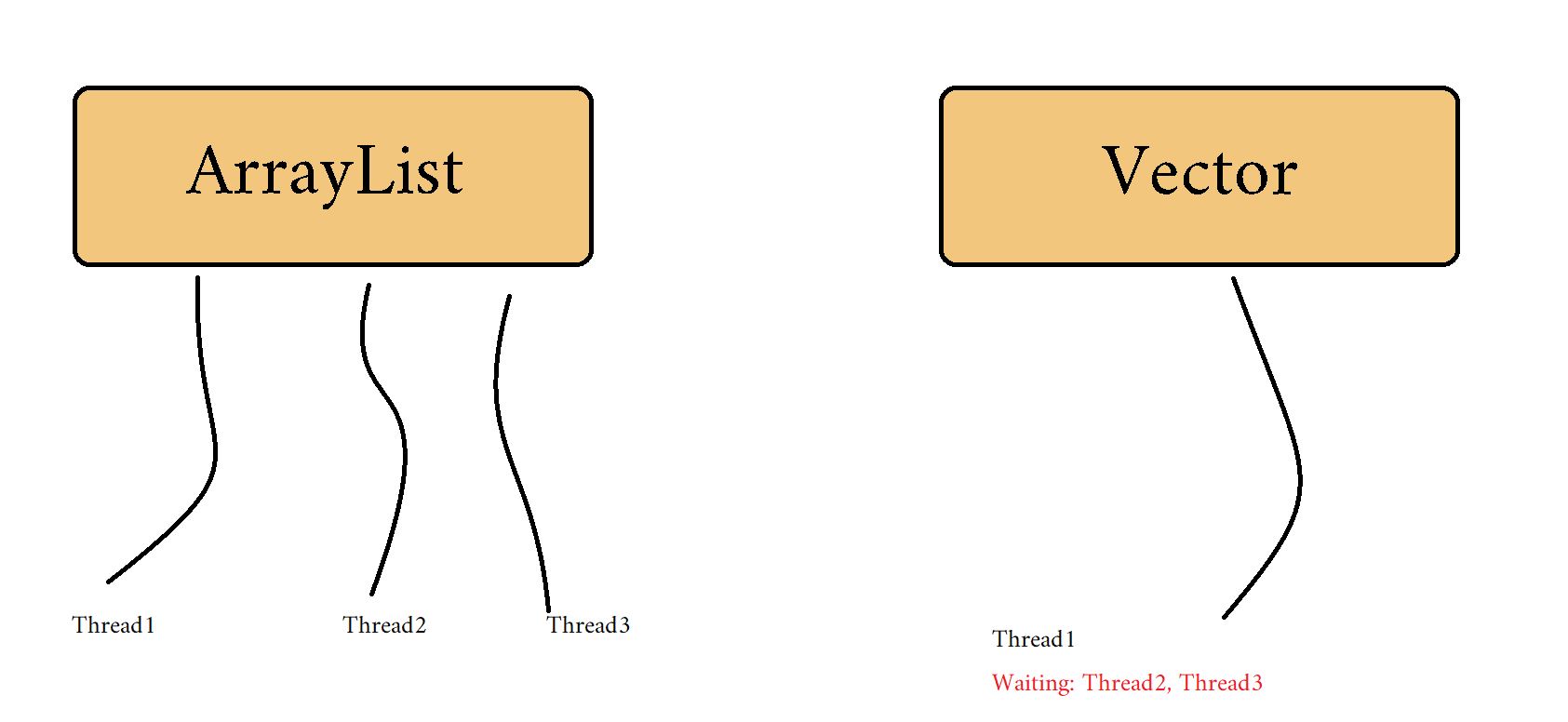
There is no synchronisation in the ArrayList.
Vector is synchronized.
The size of the array is increased by 50% when using ArrayList.
The array size is doubled, which doubles the size of the vector.
Because it is not synchronised, ArrayList is not thread-safe.
Because every procedure in a vector list is synchronised, it is thread-safe.
⌚ Differentiate between ArrayList and LinkedList.
ArrayList
LinkedList
This class's elements are stored in a dynamic array. Thanks to the advent of generics, this class now supports the storage of any types of objects.
This class's elements are stored in a doubly-linked list. This class, like the ArrayList, allows any type of object to be stored.
Manipulation of an ArrayList takes longer due to the internal implementation. When an element is removed, the array is scanned internally, and the memory bits are shifted.
Because a doubly-linked list has no idea of shifting memory bits, manipulating it takes less time than manipulating an ArrayList. After traversing the list, the reference link is updated.
When the programme requires data storage and access, this class is more useful.
When the application involves data manipulation, this class is more useful.
⌚ In Java, distinguish between List and Set.
The collection interface is extended by the List and Set. There are, however, certain distinctions between the two, which are noted below.
• Lists might have duplicate elements, but Sets have unique things.
• The List is an ordered collection that keeps its insertion order, whereas the Set is an unordered collection that loses its insertion order.
• The List interface has only one legacy class, which is the Vector class, but the Set interface has none.
• The List interface allows for an unlimited amount of null values, whereas the Set interface only allows for one.
⌚ In Java, distinguish between Iterator and ListIterator.
Iterators are used in Java's Collection framework to get elements one by one. It can be think as any Collection object. Iterator can do both read and delete operations.
Iterator must be used to iterate elements in all Collection foundation interfaces, such as Set, List, Queue, and Deque, as well as all Map interface implemented classes. The
iterator is the only cursor available throughout the collection framework.
Only classes that implement List collections, such as array lists and linked lists, can utilise ListIterator. It is capable of iterating in both directions. ListIterator must
be used while enumerating List entries. In comparison to the iterator, this cursor has more methods and capabilities.
Iterator
ListIterator
Has just the ability to move ahead through components in a Collection.
Can explore components in a Collection in both forward and backward directions.
Indexes cannot be obtained using iterators.
It has methods like next Index() and previous Index() that may be used to get element indexes at any point when traversing a List ().
It makes traversing Maps, Lists, and Sets easier.
Only List, not the other two, can be traversed.
⌚ Is it possible to include a null element in a TreeSet or HashSet?
In a HashSet, we can add null elements, but we can't do so in a TreeSet. The reason for this is that TreeSet compares using the compareTo() function, which produces a NullPointerException
when it comes across a null element.
⌚ Why does the Collection Interface not extend the Serializable and Cloneable Interfaces?
The Collection Interface's job is to specify a group of things known as elements. The way the elements are preserved is determined on how the Collections are implemented. List
implementations, for example, accept duplicate elements, whereas Set implementations do not.
A technique for public cloning is available in several implementations. However, because the Collection is abstract and implementation is all that matters, it isn't practicable to
include it in all implementations.
While working with the substantive implementations, the significance and repercussions of both serialisation and cloning become clear. As a result, it is up to
the implementation to determine whether or not it can be serialised or cloned, and if so, how.
⌚ Distinguish between a HashSet and a TreeSet. When should you use TreeSet instead of HashSet?
• HashSet: It takes the same amount of time to search, insert, and remove items. HashSet is faster than TreeSet. A hash table is used to implement HashSet.
• TreeSet takes O(Log n) for search, insert, and delete, which is higher than HashSet. TreeSet, on the other hand, keeps data in order. Other procedures such as higher()
(returns the least higher element), floor(), and ceiling() are also supported. These operations are also O(Log n) in TreeSet, and HashSet does not implement them. TreeSet is
implemented using a Self-Balancing Binary Search Tree (Red Black Tree). TreeSet is powered by TreeMap in Java.
• A HashSet's elements are not in any particular sequence. The TreeSet class in Java maintains objects in a Sorted order determined by the Comparable or Comparator methods.
TreeSet components are arranged in ascending order by default. It offers methods for dealing with ordered sets, such as first(), last(), headSet(), tailSet(), and so on.
• In HashSet, null objects are permitted. Null objects are not permitted in TreeSet, and a NullPointerException is thrown if one is encountered. This is because TreeSet uses the
compareTo() function to compare keys, which throws java.lang. NullPointerException.
• HashSet uses the equals() method to compare two objects in a Set and find duplication. TreeSet uses the compareTo() function for the same purpose. The contract of the Set
interface will be broken if equals() and compareTo() are not consistent, that is, if equals() returns true for two equal objects but compareTo() returns zero, permitting duplication
in Set implementations like TreeSet.
Which one prefer:
• Instead of unique elements, sorted unique elements are required. TreeSet returns an always ascending-ordered sorted list.
• TreeSet has a better level of locality than HashSet. TreeSet stores two items in the same data structure and thus in memory if they are in the same sequence, whereas HashSet
scatters the entries over memory independent of the keys to which they are linked.
• TreeSet uses the Red-Black tree approach to sort the components. If you need to do read/write operations frequently, TreeSet is an excellent choice.
⌚ What are the benefits of using a Properties file?
You don't have to recompile the java class if you modify the value in the properties file. As a result, the programme is simple to manage. It's used to keep track of information
that needs to be updated frequently. Consider the following illustration.
⌚ What does it mean to override the equals() method?
The equals method is used to determine if two objects are identical. If we want to verify the objects based on the property, we must override it.
Employee, for example, is a class with three data members: id, name, and salary. However, we want to make sure that the employee object is equivalent in terms of salary.
The equals() method must then be overridden.
⌚ In Java, distinguish between Collection and Collections.
Below are the distinctions between Collection and Collections.
• Collections is a class, whereas Collection is an interface.
• The Collection interface gives List, Set, and Queue the basic data structure capability. The Collections class, on the other hand, is responsible for sorting and
synchronising the collection components.
• The Collection interface exposes data structure methods, whereas the Collections class exposes static methods that can be used to perform various operations on a collection.
⌚ In Java, distinguish between Set and Map.
The Java.util package provides the Set interface. By extending the collection interface, the set interface is created. We won't be able to add the same element since
it won't let us. It does not retain the insertion order because it contains elements in a sorted order. The mathematical Set is constructed using Java's Set interface.
In the same way that Set is used to store a collection of things as a single entity, Map is used to store a collection of objects as a single entity. Each object is stored as
a key-value pair. We can rapidly acquire the value using only the key because each value is connected with a unique key.
Set
map
It can't have values that are the same every time. Adding the same components to a set is not possible. Each class that implements the Set interface saves only the one-of-a-kind value.
It's possible that many keys have the same value. The map has a one-of-a-kind key as well as values that are repeated.
We may easily iterate the Set items using the keyset() and entryset() methods.
It isn't feasible to iterate over different map items. We must convert Map to Set in order to iterate the elements.
The Set interface does not maintain track of the order in which items are inserted. However, some of its classes, like LinkedHashSet, preserve the insertion order.
The insertion sequence is not tracked by the Map. TreeMap and LinkedHashMap are two Map classes that do the same thing.
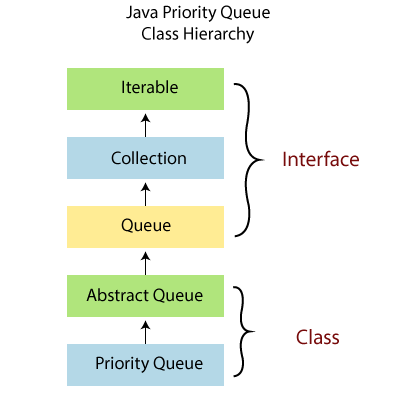
⌚ In Java, what is a priority queue?
A PriorityQueue is utilised when the objects are to be handled in order of priority. Although a queue is understood to follow the First-In-First-Out procedure, there are times
when the queue's components must be handled in order of priority, which is where the PriorityQueue comes in. The PriorityQueue's base is a priority heap. The members of the priority
queue are ranked either by natural ordering or by a Comparator that is provided at the time of queue building.
The PriorityQueque class in Java implements the Serializable, IterableE>, CollectionE>, and QueueE> interfaces.
⌚ What is the purpose of the hashCode() method?
The hashCode() method returns the value of a hash code (an integer number).
If two keys (as determined by the equals() function) are identical, the hashCode() method returns the same integer value.
It is feasible, however, for two hash code numbers to have different or identical keys. If the equals() function does not yield an equal result for two objects, the
hashcode() method will return a different integer result for both objects.
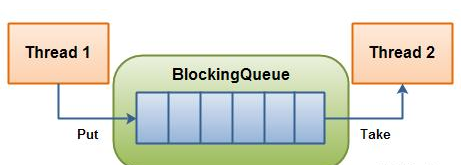
⌚ What do you know about Java's BlockingQueue?
ConcurrentHashMap, Counting Semaphore, CopyOnWriteArrayList, and other concurrent Utility classes have been included with BlockingQueue. The BlockingQueue interface allows
flow control in addition to queueing by adding blocking if either BlockingQueue is full or empty.
A thread attempting to enqueue an element in a full queue will be halted until another thread dequeues one or more elements or clears the queue entirely. It also prohibits a
thread from deleting something from an empty queue until another thread enters something. BlockingQueue does not allow null values. Thread-safe implementations of the Java BlockingQueue
interface exist. The methods in BlockingQueue are all atomic and employ internal locks or other concurrency management techniques.
Unbounded Queue: The capacity of the blocked queue will be set to Integer. MAXIMUM VALUE Because it has the potential to grow to a very large size, an unbounded blocking queue
will never block. The line grows in size as you add more pieces.
BlockingQueue unbounded_queue = new LinkedBlockingDeque();
Bounded Queue: The second form of queue is the bounded queue. When creating a blocking queue from a bounded queue, the capacity of the queue can be provided to the constructor
BlockingQueue bounded_queue = new LinkedBlockingDeque(10);
⌚ In java, differentiate between HashSet and HashMap.
HashSet is a Set Interface implementation that prevents values from being duplicated. The key point is that objects in HashSet must override equals() and hashCode() methods
to ensure that our set does not contain duplicate data.
HashMap is an implementation of the Map Interface that maps a key to a value. A map cannot include duplicate keys.
HashSet
Hashmap
The Set Interface is implemented.
It is responsible for implementing the Map Interface.
It does not allow duplicate values.
The key must be distinct, and no two keys can have the same value.
HashSet adds entries using HashMap internally. The argument supplied in the add(Object) method is the HashSet's key K. Java assigns a dummy value to each value passed to the add(Object) method.
Duplicate values aren't even considered.
⌚ In Java, distinguish between Array and ArrayList.
Arrays are a key feature of the Java programming language. ArrayList is a collection system component in Java. As a result, It is used to access array members, whereas
ArrayList provides a collection of methods for altering and accessing components.
The data structure ArrayList is not a fixed-size data structure, while the data structure Array is. There is no need to provide the size of an ArrayList object when constructing it.
We can add more pieces later even if we specify a maximum capacity.
Depending on the array's definition, it can contain both primitive data types and class objects. In contrast, ArrayList only allows object entries, not primitive data types.
The primitive int data type is transformed to an Integer object when we call arraylist.add(1);.
Java ArrayList also supports a variety of other actions, such as indexOf() and delete(). These functions are not supported by arrays.
⌚ Why does HashMap allow null values when HashTable does not?
To correctly save and retrieve objects from a HashTable, the objects used as keys must implement the hashCode and equals functions. Because null is not an object, it cannot
implement these methods. HashMap is an enhanced and more advanced version of Hashtable. HashMap was created after HashTable to address HashTable's inadequacies.
⌚ In Java, how do you make an ArrayList read-only?
We can easily make an ArrayList read-only by using the Collections.unmodifiableList() function. This function takes a changing ArrayList as an argument and produces a
read-only, unchanged representation of the ArrayList.
import java.util.*;
public class Logicmojo {
public static void main(String[] args)
throws Exception
{
try {
// creating object of ArrayList<String>
List<String> sample_list = new ArrayList<String>();
sample_list.add(“practice”);
sample_list.add(“solve”);
sample_list.add(“interview”);
// displaying the initial list
System.out.println("The initial list is : "+ sample_list);
// using unmodifiableList() method
List<String>
read_only_list = Collections
.unmodifiableList(sample_list);
// displaying the read-only list
System.out.println("The ReadOnly ArrayList is : "+ read_only_list);
// Trying to add an element to the read-only list
System.out.println("Trying to modify the ReadOnly ArrayList.");
read_only_list.add(“job”);
}
catch (UnsupportedOperationException e) {
System.out.println("The exception thrown is : "+e);
}
}
}
Output:
The initial list is : [practice, solve, interview]
The ReadOnly ArrayList is : [practice, solve, interview]
Trying to modify th eReadOnly ArrayList.
Exception thrown : java.lang.UnsupportedOperationException
⌚ In a hashing-based collection, what is the default size of the load factor?
The load factor is set at 0.75 by default. The load factor is multiplied by the initial capacity to get the default capacity.
⌚ Describe Enums' Special Collections. What Are the Advantages of Using Them Instead of Regular Collections?
EnumSet and EnumMap, respectively, are unique implementations of the Set and Map interfaces. When working with enums, you should always use these implementations because
they are very efficient.
An EnumSet is nothing more than a bit vector with "ones" in the positions that correspond to the ordinal values of the enums in the set. To determine whether an enum value is in the set,
the implementation must simply check whether the matching bit in the vector is a "one," which is a simple process. An EnumMap, on the other hand, is an array accessible using the enum's
ordinal value as an index. There is no need to calculate hash codes or resolve clashes with EnumMap.
⌚ What's the Difference Between Fail-Safe Iterators and Fail-Fast Iterators?
Depending on how they react to concurrent updates, iterators for distinct collections are either fail-fast or fail-safe. Concurrent modification includes not only collection
modification from another thread, but also collection modification from the same thread using a different iterator or directly altering the collection.
Fail-fast iterators (those returned by HashMap, ArrayList, and other non-thread-safe collections) loop across the collection's internal data structure, and
when they detect a concurrent modification, they throw ConcurrentModificationException.
Fail-safe iterators (returned by thread-safe collections like ConcurrentHashMap and CopyOnWriteArrayList) duplicate the structure they iterate through. They ensure that changes
are not made at the same time. Their disadvantages include high memory usage and iteration over potentially out-of-date data if the collection is changed.
⌚ What are the techniques for thread-safe collection?
The following are some approaches for keeping collecting thread safe:
• Collections.synchronizedList(list);
• Collections.synchronizedMap(map);
• Collections.synchronizedSet(set);
⌚ What is UnsupportedOperationException?
UnsupportedOperationException is an exception that is thrown when a method is called that the real collection type does not support.
Developer, for example, creates a read-only list using "Collections.unmodifiableList(list)" and uses the call(), add(), and delete() methods. UnsupportedOperationException should be clearly thrown.
⌚ In Java, how do you synchronise an ArrayList?
The following two methods can be used to synchronise an ArrayList:
Collections.synchronizedList() method:
Making Use of Collections synchronizedList() method: In order to perform serial access, all access to the backup list must be done through the returned list. It is crucial
that the user manually synchronises when iterating through the returned list.
Using CopyOnWriteArrayList:
A thread-safe variation of ArrayList is constructed in this example. T stands for generic.
In this thread-safe form of ArrayList, all mutative actions (e.g. add, set, remove, etc.) are implemented by creating a separate copy of the underlying array. Thread safety is achieved
by creating a second copy of List, which is different from how vectors and other collections achieve thread safety.
Because the iterator is iterating over a distinct copy of ArrayList while a write operation is occuring on another copy of ArrayList, even if copyOnWriteArrayList is modified after
an iterator is generated, the iterator does not trigger ConcurrentModificationException.
⌚ Why do we need a synchronised ArrayList in Java when we already have Vectors (which are already synchronised)?
• Because Vector is synchronised and thread-safe, it is slightly slower than ArrayList.
• Vector's main feature is that it synchronises all of your actions. The preference of a programmer is to synchronise a complete chain of events. Individual activities are less secure, and synchronisation takes longer.
• In Java, vectors are considered obsolete and have been deprecated informally. Vector also performs per-operation synchronisation, which is almost never done. Most Java programmers prefer to use ArrayList since they will almost probably need to synchronise the arrayList explicitly.
⌚ Create a Java application that combines two arraylists into a single arraylist.
We utilise the ArrayList class's addAll() method to combine the contents of both arraylists into a single new arraylist.
//importing the required header filesimportjava.util.ArrayList;importjava.util.Collections;publicclassJoin_Lists{publicstaticvoidmain(String[] args){//creating the first array list
ArrayList<String> list_1 =new ArrayList<String>();
list_1.add("Monday");
list_1.add("Tuesday");
list_1.add("Wednesday");
list_1.add("Thursday");//printing the first array list
System.out.println("The elements of the first array list is as follows : "+ list_1);//creating the second array list
ArrayList<String> list_2 =new ArrayList<String>();
list_2.add("Friday");
list_2.add("Saturday");
list_2.add("Sunday");//printing the second array list
System.out.println("The elements of the second array list is as follows : "+ list_2);//creating the third array list
ArrayList<String> joined_list =new ArrayList<String>();
joined_list.addAll(list_1);//adding the elements of the first array list
joined_list.addAll(list_2);//adding the elements of the second array list
System.out.println("The elements of the joined array list is as follows : "+ joined_list);}}
🚀Conclusion
This page has finally come to an end. With the information on this page and a little practise, you should be able to create your own programmes, and modest projects are really
encouraged for increasing your programming skills. It's impossible to learn everything you need to know about programming in only one lesson. Whether you're a seasoned professional
developer or a complete novice, programming is a never-ending learning process.
TEST YOUR KNOWLEDGE!
1. Which of these packages contain all the collection classes?
2. Which of these classes is not part of Java’s collection framework?
3. Which of this interface is not a part of Java’s collection framework?
4. What is Collection in Java?
5. Which of these interface must contain a unique element?
6. Which of these methods can convert an object into a List?
7. Which of these is static variable defined in Collections?
8. After resizing, size of ArrayList is increased by :
9. Deque and Queue are derived from?
10. Which provides better performance for the insertion and removal from the middle of the list?