Interview Questions
- What are data structures
- What are types of Data structures
- What are the applications of Data structures
- List the data structures which are used in RDBMS
- Name various operations that can be performed in data structures
- Benefits of Learning Data Structures
- Which data structure is used to perform recursion
- Data structures in C/C++, Java, Python
- What are the types of searching used in Data Structures
- When is a binary search best applied
- What is an array
- What is linked list
- What is a Stack
- Name some characteristics of Array Data Structure
- It’s ok not to know everything
- Previous workplaces culture
- Progressively optimize your solution
- Don't code silently
- Test Your Solution
- How to write test cases
What are data structures?
A data structure is a method for storing and arranging data values so that they can be used later in an application. Graphs, Trees, Arrays, and Linked Lists are just a few examples.
It is used to arrange and modify data in an effective manner.
DS is a representation of data and the relationships between distinct data that aids in the efficiency with which various functions, processes, and algorithms can be implemented.
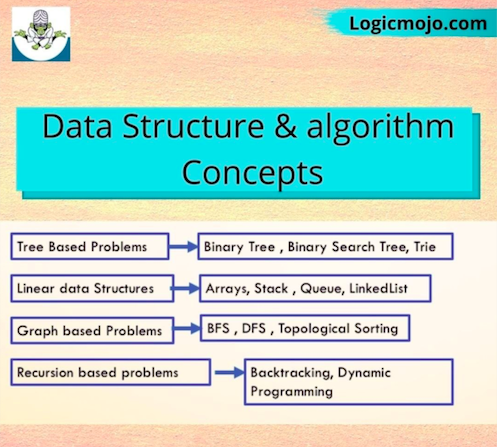
What are the different types of data structures ?
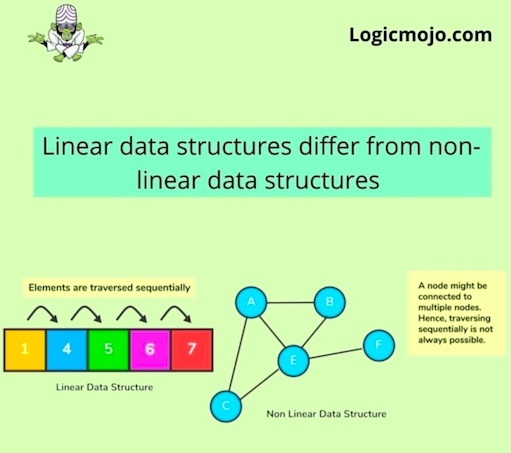
Data structures are of two types:
Linear Data Structure:
For Ex : Array, Stack, Queue, Linked-List
Non-Linear Data Structures: The Non-linear data structure does not form a sequence i.e. each item or element is connected with two or more other items in a non-linear arrangement. The data elements are not arranged in the sequential structure.
For Ex : Graphs, Trees
What are the applications of Data structures ?
Data Structures are used in almost every aspect of computing, particularly in the domains of algorithms and algorithm optimization. Here are a few more places where Data Structures are utilised frequently :
1. Compiler Design
2. Operating System
3. Database Management System
4. Statistical analysis package
5. Numerical Analysis
6. Numerical Analysis
7. Graphics
8. Artificial Intelligence
9. Simulation
10. Lexical Analysis
11.Compiler design and development

List the data structures used in relational databases, network data models, and hierarchical data models.
The major data structures used are as follows:
1. RDBMS - Array (i.e. Array of structures)
2. Network data model - Graph
3. Hierarchical data model - Trees
Why data structures concepts are important
Prepare yourself for tech interview by learning Data Structures and Algorithms Concepts
It's really important to understand the real-world significance of algorithms and its properties because using different ideas one can design many algorithms for computing a solution to a given problem. Key important questions in algorithms are
1. How do we design good algorithms?
2. How do we know that our algorithm is efficient ?
3. How to efficiently implement algorithms in a programming language?
4. Iteration and Two Pointer Approach
Data structures and algorithm is paramount as in today’s world, companies deal with a lot of data. As coders, you should know about code optimization to ensure space and time resources are utilized efficiently. Also, for cracking product-based company interviews which offer a high-paying job, data structures and algorithm is a must.
Let’s look at some important product-based companies that test data Structures and algorithms skills in coding rounds:
| Company | Average Package in INR |
|---|---|
| 25 Lakh | |
| Amazon | 25 Lakh |
| WalmartLabs | 23 Lakh |
| Flipkart | 23 Lakh |
| Microsoft | 24 Lakh |
| Uber | 21 Lakh |
| Abobe | 18 Lakh |
| Intuit | 19 Lakh |
| Apple | 21 Lakh |

How to prepare for Algorithms & Data Structures
• Iteration is a fundamental programming idea that is commonly used in writing programs.
Recursion and Divide & Conquer Approach
• Recursive thinking is an important art in programming which helps you to formulate the solution of a problem via the solution of its smaller subproblems.
Array and Linked-List
• Array and Linked list are used to store linear data of similar type but the
major difference between them is related to their structure
• A binary tree is a tree data structure in which each node has at most two children,
which are referred to as the left child and the right child.
• Binary Search Tree combine the efficiency of insertion of a Linked List
and the quick search of a sorted array.
• A Heap is an array implementation of complete binary tree where each node satisfy the heap-property
• Hash Table is an important Data Structure which is used to map a
given value with a particular key for faster access of elements
• Dynamic Programming solves the problem by breaking down into smaller sub-problems,
and storing the solution to each sub-problem so that each sub-problem is only solved once.
• A greedy algorithm is a simple, intuitive algorithm that is used in optimisation problems.
• Backtracking solves problems recursively by building a solution incrementally, one piece at a
time and removing those solutions that fail to satisfy the constraints of the problem at any point of time.
• Graphs are used to represent, find, analyse, and optimise connections between elements like locations, users etc.

Name various operations that can be performed in data structures and algorithms
• Insert: Here, we add a new data item in a data structure.
• Search: In this, we find an element in the data structure.
• Sort: Simple sorting like arranging values in ascending or descending order. For example, arranging values in an array.
• Delete: Here, we delete unwanted data points in a data structure.
• Traversal: We access each data item exactly once so that it can be processed for further use.
Benefits of Learning Data Structures
The actual reason behind your learning can improve your knowledge in the domain accordingly. For example, some people learn them particularly to suffice job interviews, few to make their resumes look better, etc. While others might learn to ace competitive programming. Regardless of the reason for learning data structures and algorithms, there are benefits pertaining to knowledge. The following are some of those benefits.
• To write the logical statement, this means that a programmer can write the correct code if they knew both data structures and algorithms.
• if-then-else statement: If-Then statements are a type of variable logic that allows the output of the variable to be conditionally determined.
For all If-Then statements, the conditions must be defined as well as the actions that should occur when those conditions are met.
Therefore, the guarantee is that at least one of the two statements is true and will execute
if(Boolean_expression) {
// Executes when the Boolean expression is true
}else {
// Executes when the Boolean expression is false
}
• Loop Statements: As the term ‘loop’ suggests, they are used to perform similarly, if not the same action multiple times consecutively.
It makes them an essential part of every programming language there is.
There can many different types of loop statements based on the desired outcome.
However, there are for core types that are:
1. For
2. While/do
3. Repeat/until
4. Infinite looping
Which data structure is used to perform recursion ?
Stack data structure is used in recursion due to its last in first out nature. Operating system maintains the stack in order to save the iteration variables at each function call

Data structures in C/C++, Java & Python
The core concepts of data structures remains the same across all the programming languages. Only the implementation differs based on the syntax or the structure of the programming language.
The implementation in procedural languages like C is done with the help of structures, pointers, etc.
In an objected oriented language like Java, data structures are implemented by using classes and objects
Having sound knowledge of the concepts of each and every data structures helps you to stand apart in any interviews as selecting right data structure is the first step towards solving problem efficiently
What are the types of searching used in Data Structures ?
Design patterns use object-oriented concepts like decomposition, inheritance and polymorphism.They provide the solutions that help to define the system architecture
Design patterns can be classified in three categories: Creational, Structural and Behavioral patterns
Linear Search
Binary Search
Jump Search
Interpolation Search
Exponential Search
When is a binary search best applied ?
A binary search is an algorithm that is best applied to search a list when the elements are already in order or sorted. The list is searched starting in the middle, such that if that middle value is not the target search key, it will check to see if it will continue the search on the lower half of the list or the higher half. The split and search will then continue in the same manner.
What is an array ?
An array is a collection of data points of the same type stored at contiguous memory locations. For example, an array of integers like 1,2,3,4,5. This array has 5 elements.The index of an array usually starts with 0
What is linked list ?
A linked list is a sequence of nodes in which each node is connected to the node following it. This forms a chain-like link for data storage
What is a Stack ?
Stack is an ordered list in which, insertion and deletion can be performed only at one end that is called the top. It is a recursive data structure having pointer to its top element. The stack is sometimes called as Last-In-First-Out (LIFO) list i.e. the element which is inserted first in the stack will be deleted last from the stack.
Array elements are stored in contiguous memory blocks in the primary memory.
Array name represents its base address
The base address is the address of the first element of the array.
Array’s index starts with 0 and ends with size-1.
Progressively optimize your solution
After talking through the brute-force solution, your interviewer may ask you whether you can come up with a better solution. If so, it’s now time to revisit your suboptimal solution and optimize it.
Like the process of getting to a brute-force solution, don’t jump straight into code when finding a more optimal solution. Discuss your approach with your interviewer and lean on them to get a sense of whether they have a preference for whether you optimize for time, space, or both. When optimizing, some of your initial assumptions may change, so it’s important to check with your interviewer
You may see the most optimal solution right away or be unsure on how to proceed. If you’re stuck, here are some common approaches to optimizing:
Take a second look at the problem, its constraints, and write down your assumptions and possible simplifications
Consider similar problems you’ve seen and discuss them with your interviewer
Solve an example by hand and extrapolate about what algorithm(s) could be used
Simulate the brute-force solution by hand and identify the inefficiencies that could be optimized with a data structure
Solve a simple version of the problem first, then build on it
Don’t forget to communicate and analyze the time or space complexity of the solution you plan to optimize. Once you and your interviewer agree that you have a good solution, it’s time to code it
Don't code silently
It’s important to remember that this portion of the interview is not actually all about coding. Your interviewer doesn’t want you to code in silence for fifteen minutes and then announce that you’re done, but rather to talk out loud and explain what you’re coding.
As an interviewee, it’s important to ensure that your interviewer understands what you’re doing and why you’re doing it in real-time. If you’re explaining your thought process out loud and you take a wrong turn, your interviewer may offer you a hint to get you back on track. However, if you jump straight into coding without explaining your thought process first, you may miss the opportunity to receive support from your interviewer. Worse, you could be wasting valuable time on an incorrect approach.
While you’re coding, don’t read your code; but rather, talk about the section of the code you’re implementing at a higher level. Explain why you wrote it that way and what it’s trying to achieve.
Remember that your interviewer needs to be able to understand your code to efficiently evaluate whether your code returns the expected result and solves the problem. As you code, keep these pointers in mind:
Use good style when writing your code. Reading another person’s code is typically not an enjoyable task, but reading badly formatted code can be a challenge for your interviewe
Naming Matters. Make sure to use the right variable, function, and class names. You should also avoid single letter variables unless they’re for iteration
Demonstrate good modularity. Your goal is to write code that’s adaptable to change. Identify the concepts that are likely to persist as new requirements come in and cement them into your design; more volatile logic should be easy to identify and change
Leave time to check for bugs and edge cases. Include this in your mental to-do list
Once you’re finished coding, there’s a high chance that you missed a bug or syntax error somewhere in your code. Don’t stress about it, but you will want to repair the code by yourself
When you’re finished, let the interviewer know and then ask them if you can have a look at your code to ensure there are no mistakes
Take a step back and briefly read through your solution, examining it as if it were written by someone else, but don’t start debugging it manually. This is the same approach that will be taken by your interviewer. Fix any issues you may find
Walk your interviewer through the code and explain your rationale. If you find a bug or mistake, feel free to acknowledge it and make the change
Test Your Solution
Debugging is a very important skill, and in environments where it’s available, showcasing your ability to analyze why code failed and quickly understand how to fix it is a great signal. Good programmers are pragmatic: we’re more likely to create and solve bugs as we code, rather than to write perfect code on the first try
During the testing portion of the interview, you should have a few goals in mind
Demonstrate that you care that your code actually works
Show that you can understand and solve problems even if it doesn’t work
Exhibit your understanding of the various edge cases
Establish a feedback loop for your code that allows refactoring without having to worry about breaking existing functionality
How to write test cases
you’ve coded up a solution that you may not be so happy with, it’s time to do some manual testing to ensure it performs how you expected. The interviewer will want you to write tests for your code, so it’s a plus if you write tests without being prompted.There are a few types of inputs you’re going to test for:
Large and small valid inputs
Large and small invalid inputs
Random input
For each input, manually go through your code and ensure that it performs. You should jot down or tell your interviewer the values of each variable as you walk them through the code.
If you find an error, explain the error to your interviewer, fix it, and move on. Similarly, if there are large duplicated code blocks in your solution, you can take the time to restructure the code
In this stage, you’ll also have the opportunity to showcase your knowledge around automated testing. You can chat about how you’d generate different types of inputs, how you would stub parts of the code, the test runners you’d use, and more. These are all great signals to show an interviewer
If your interviewer was content with your solution, the interview would end here. Time permitting, they may ask you additional questions such as how you’d approach the problem if the input was too large to fit in memory. For companies that care about scale, this is a common follow-up question.