Master Data Structures & Algorithms with Logicmojo DSA Course
Learn DSA for 4 months with System Design for 3 months, and get placed into product-based companies after completing the course.
"
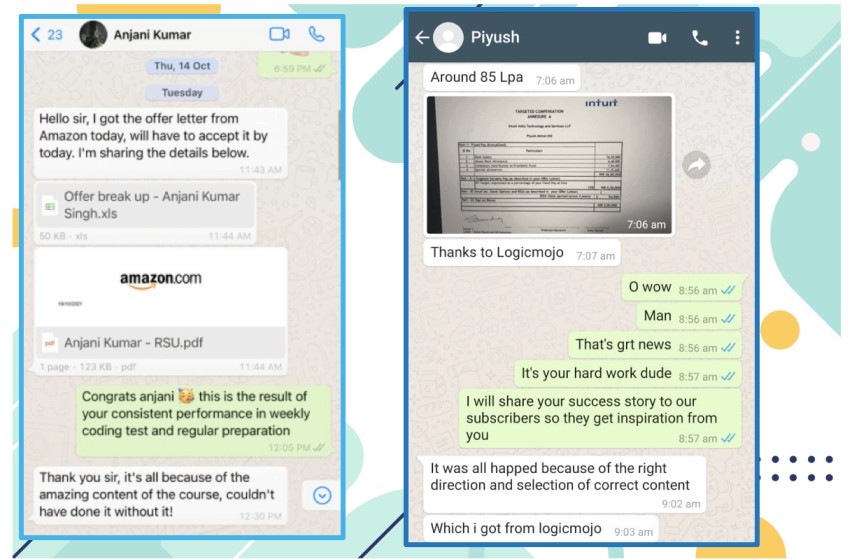
Amazon
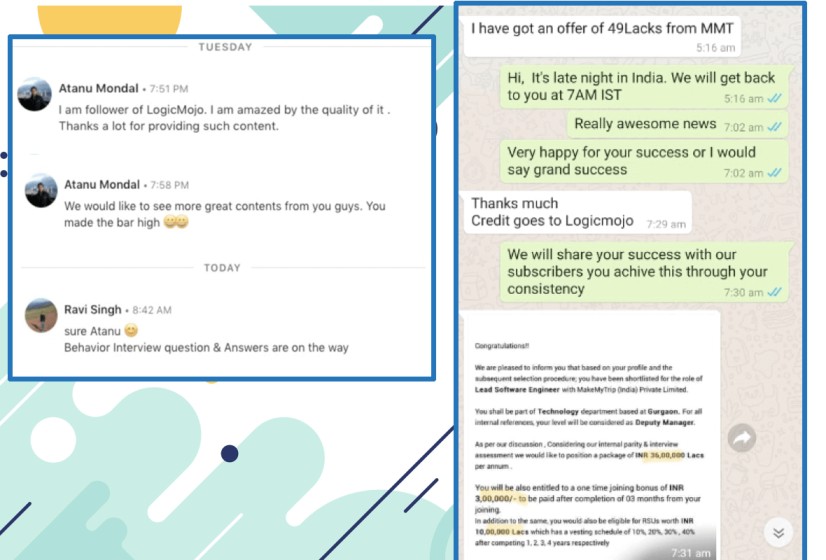
Must recommend for the aspirants who are preparing for Amazon, Google, Microsoft, and Top Product Based Company interview. Logicmojo focus on techniques of solving data structures problems

"
Microsoft
The course curriculum is of the best quality along with the best learning experience from my tutor. Best course to prepare for MAANG companies interview. I cracked Paytm, Adobe, Intuit, and Microsoft. Finally joined Microsoft at 1.3 Cr LPA Hyderabad MS IDC

"
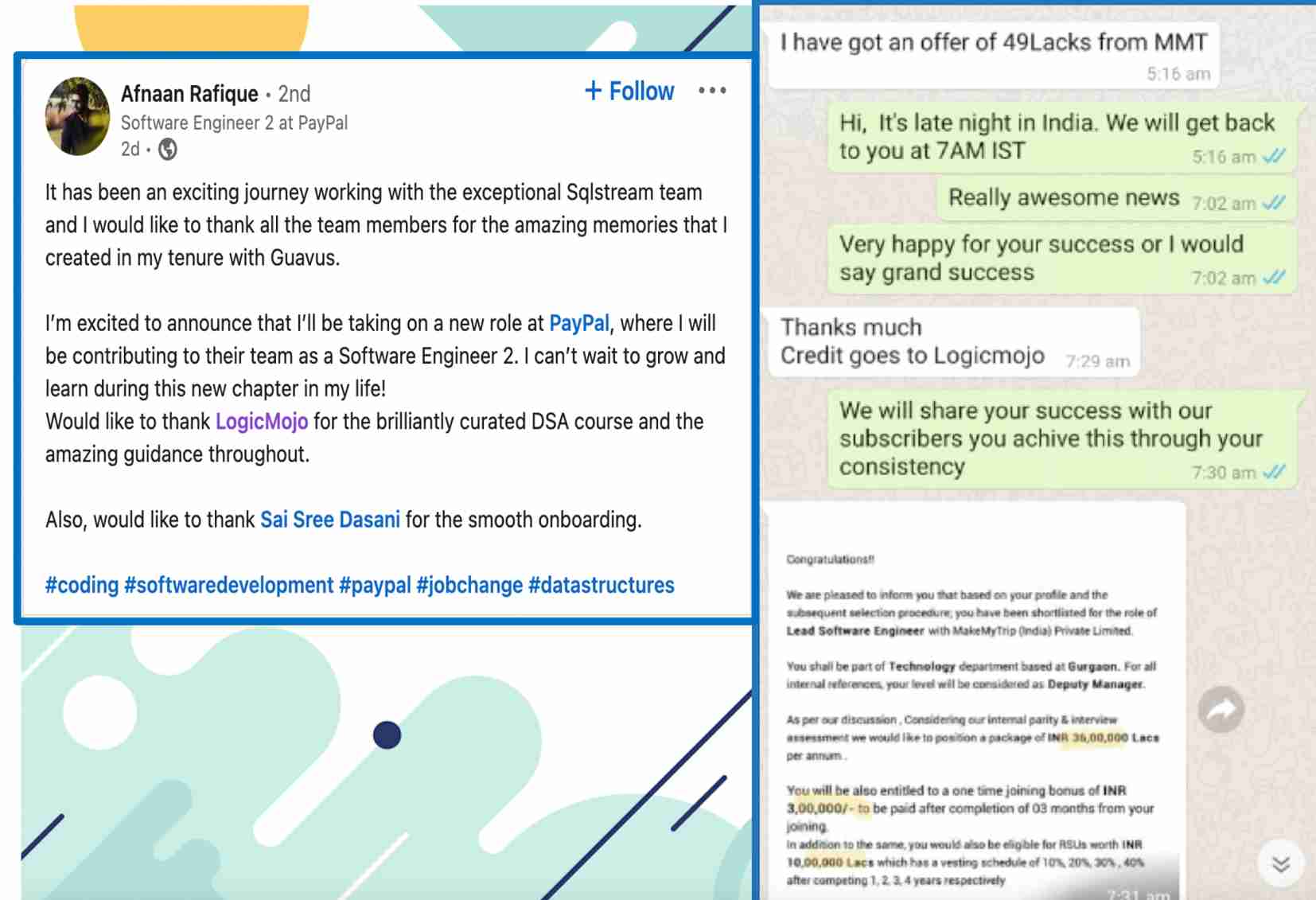
WalmartLabs
Excellent course for interview preparation, very straight to the point ,in depth coverage of every point. Nice way of explaining solutions to very complex problems in easy way. It helps me to land at Architect Position in WalmartLabs as well as VISA.

"
Microsoft
I would say the best part is the explanation by the instructor, concise and clear. Great quality of online materials and classes, it covers all algorithms and system design problems asked during interviews

"
Flipkart
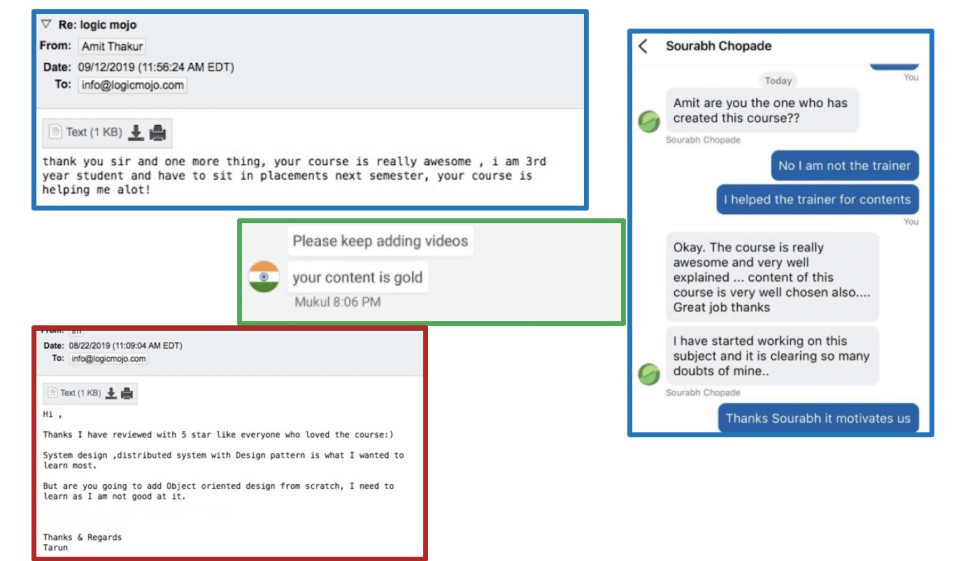
Great course! Definitely helped me open some new doors in understanding how algorithms work and implementing solutions for the different exercises

"
Cisco
The course curriculum is of best quality along with good coding problems.It's like a quick interview preparation guide
"
WalmartLabs
Excellent course for interview preparation, very straight to the point ,in depth coverage of every point. Nice way of explaining solutions to very complex problems in easy way
"
Amazon
Very well-arranged course and its amazing lectures. Focus on lectures concepts & techniques than solving thousands of problems of Leetcode. Problems set in the course is more than enough for top tech companies interviews.

 Download brochure
Download brochure








 Apply For DSA Classes
Apply For DSA Classes 

















 Live online interactive sessions
Live online interactive sessions