Unlock the complete
Logicmojo experience for FREE
Sign Up Using
1 Million +
Strong Tech Community
500 +
Questions to Practice
50 +
Jobs Referrals
Sign Up Using
Strong Tech Community
Questions to Practice
Jobs Referrals

There isn't a spot on the planet where Data doesn't exist!
Every day, around 2.5 quintillion bytes of data are generated in today's market.
As a result, it is critical that we all examine this data and generate the necessary outcomes using database management systems (DBMS).
Knowing DBMS, on the other hand, opens the way to becoming a Database Administrator.
I suppose you are already aware of these facts, which is why you are reading this post on DBMS Interview Questions Latest Questions on 2024.
Knowing your way around a Database Management System is the foundation of any data analytics career (DBMS).
You must be able to organise, evaluate, review, and make sense of large amounts of data in order to construct functional database systems.
Here are some DBMS interview questions asked latest in 2024 that can help you prove your competence and understanding in your next job interview and get the job you've always wanted, whether you've already started a career in data analytics or are just getting started.
To assist you ace your interview, we've compiled a list of the most regularly asked DBMS interview questions to help you solidify your knowledge and concepts in the field.
Let's start with the fundamental DBMS interview questions.
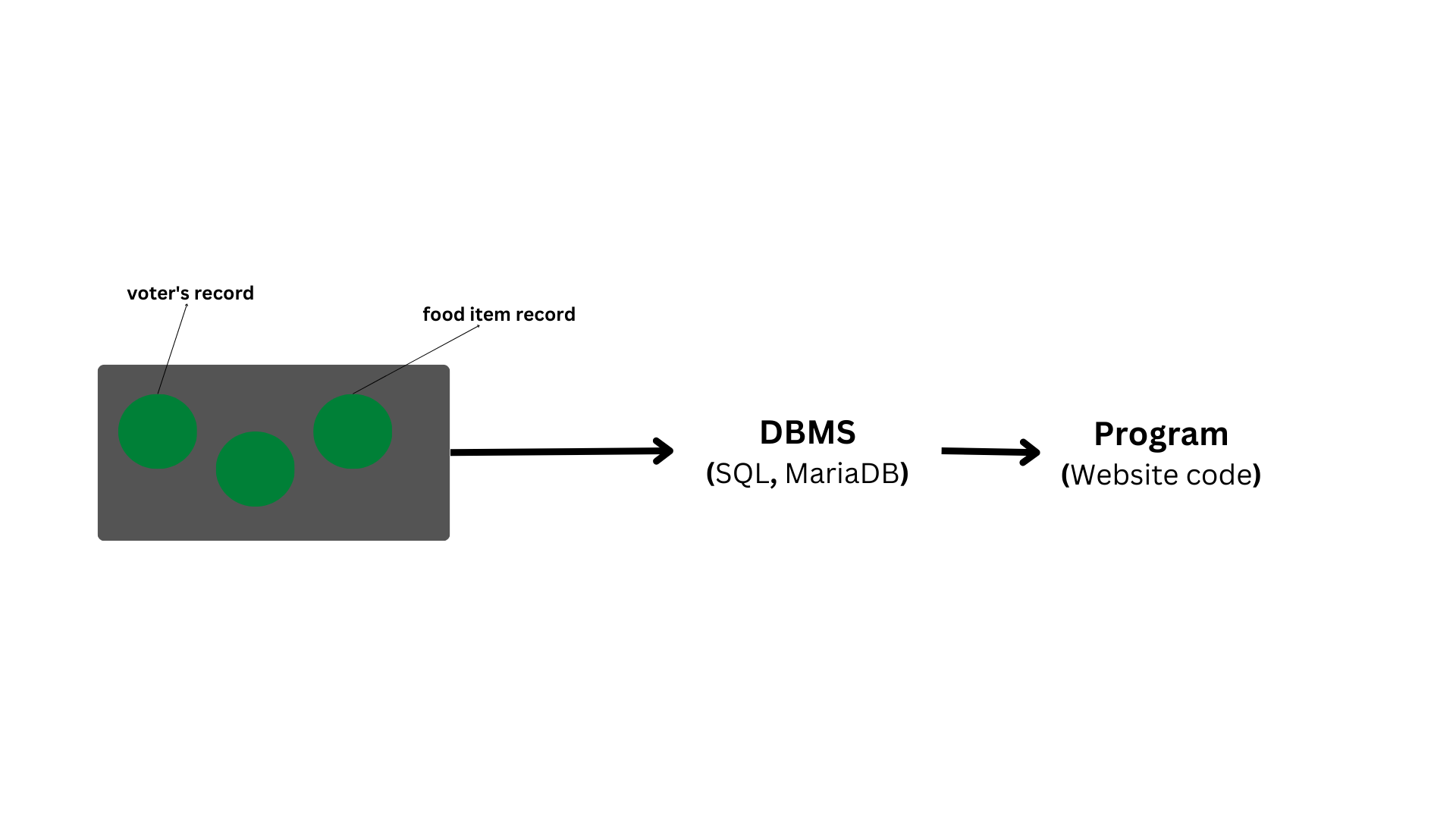
A database management system (DBMS) is a set of tools that make it easier for users to construct and maintain databases.
In other words, a database management system (DBMS) provides us with an interface or tool for completing various tasks such as creating a database, entering data into it, deleting data from it, updating data, and so on.
A database management system (DBMS) is software that allows data to be kept in a more secure manner than a file-based system.
We can solve a variety of issues using DBMS, such data redundancy, data inconsistency, quick access, more ordered and intelligible data, and so on.
There are some well-known Database Management Systems, such as MySQL, Oracle, SQL Server, Amazon Simple DB (Cloud-based), and so on.
A database is a collection of logical, consistent, and organised data that can be easily accessed, controlled, and updated.
Databases, also known as electronic databases, are structured to allow for the efficient production, insertion, and updating of data and are saved as a file or set of files on magnetic discs, tapes, and other secondary devices.
Objects (tables) make up the majority of a database, and tables contain records and fields.
Fields are the fundamental units of data storage, containing information on a certain element or attribute of the database's entity.
A database management system (DBMS) is used to extract data from a database in the form of queries. To make it easier to access relevant information, you can organise data into tables, rows, and columns, as well as index it.
Database handlers design a database such that all users have access to the data through a single piece of tools.
The database's primary goal is to manage a huge amount of data by storing, retrieving, and managing it.
Databases are used to manage a large number of dynamic websites on the Internet today.
Consider a model that checks the availability of hotel rooms.
It's an example of a database-driven dynamic webpage.
Databases such as MySQL, Sybase, Oracle, MongoDB, Informix, PostgreSQL, SQL Server, and others are available.
The lack of indexing in a traditional file-based system leaves us with little choice but to scan the entire page, making content access time-consuming and slow.
The other issue is redundancy and inconsistency, as files often include duplicate and redundant data, and updating one causes all of them to become inconsistent.
Traditional file-based systems make it more difficult to access data since the data is disorganised.
Another drawback is the lack of concurrency management, which causes one operation to lock the entire page, as opposed to DBMS, which allows several operations to work on the same file at the same time.
Other concerns with traditional file-based systems that DBMSs have addressed include integrity checks, data isolation, atomicity, security, and so on.
The following are some of the benefits of using a database management system:
🚀 Data sharing: Data from the same database can be accessed by multiple people at the same time.
🚀 Integrity restrictions: These limitations allow for more refined data storage in a database.
🚀 Data redundancy control: Supports a system for controlling data redundancy by combining all data into a single database.
🚀 Data Independence: Allows the structure of the data to be changed without affecting the structure of any running application applications.

🚀 Backup and recovery feature: Provides a 'backup and recovery' feature that automatically creates a data backup and restores the data as needed.
🚀 Data Security: A database management system (DBMS) provides the capabilities needed to make data storage and transfer more dependable and secure.
Some common technologies used to safeguard data in a DBMS include authentication (the act of granting restricted access to a user) and encryption (encrypting sensitive data such as OTP, credit card information, and so on).
The following are some of the DBMS languages:
🚀
DDL (Data Definition Language) is a language that contains commands for defining databases.
CREATE, ALTER, DROP, TRUNCATE, RENAME, and so on.
🚀
DML (Data Manipulation Language) is a set of commands that can be used to manipulate data in a database.
SELECT, UPDATE, INSERT, DELETE, and so on.
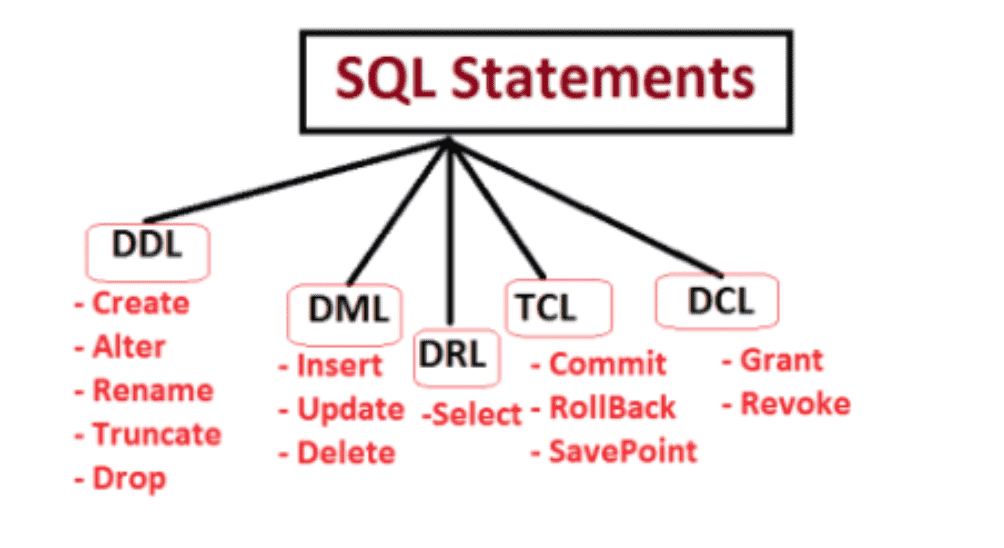
🚀 DCL (Data Control Language): It offers commands for dealing with the database system's user permissions and controls.
GRANT and REVOKE, for example.
🚀 TCL (Transaction Control Language) is a programming language that offers commands for dealing with database transactions.
COMMIT, ROLLBACK, and SAVEPOINT, for example.
The ACID properties of a database management system are the basic principles that must be observed in order to maintain data integrity.
They are as follows:
🚀Atomicity - Also known as the "all or nothing" rule, atomicity states that everything evaluated as a single unit is either executed to completion or not at all.
🚀
Consistency - This attribute indicates that the database's data is consistent before and after each transaction.
🚀
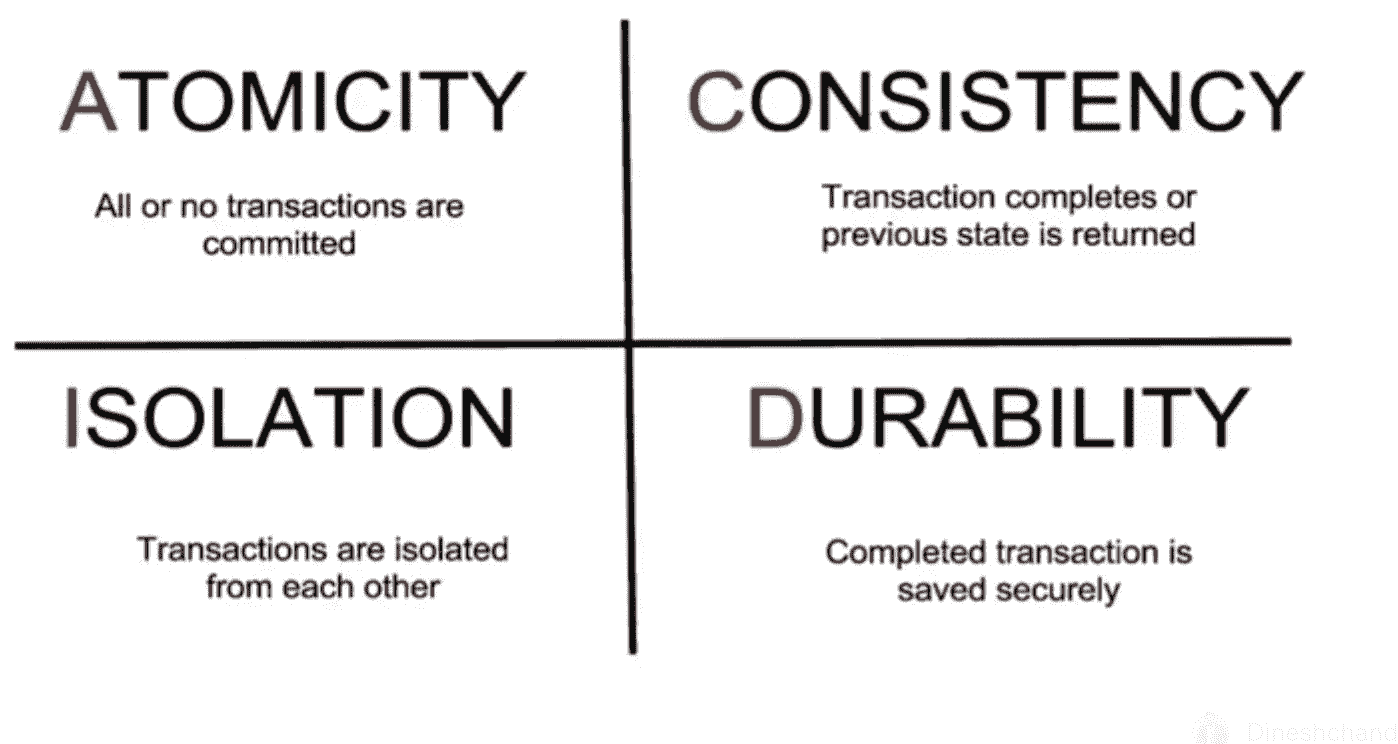
Isolation - This characteristic specifies that several transactions can be conducted at the same time.
🚀
Durability - This characteristic ensures that each transaction is saved in non-volatile memory once it has been finished.
No, a NULL value is distinct from zero and blank space in that it denotes a value that is assigned, unknown, unavailable, or not applicable, as opposed to blank space, which denotes a character, and zero, which denotes a number.
For instance, a NULL value in "number of courses" taken by a student indicates that the value is unknown, but a value of 0 indicates that the student has not taken any courses.
🚀A super key is a set of relation schema attributes that all other schema attributes are functionally dependent on.
The values of super key attributes cannot be the identical in any two rows.
🚀A Candidate key is a minimum superkey, which means that no suitable subset of Candidate key properties may be used to create a superkey.
🚀One of the candidate keys is the Primary Key.
🚀One of the candidate keys is chosen as the primary key and becomes the most important.
In a table, there can only be one main key.
🚀A foreign key is a field (or set of fields) in one table that is used to uniquely identify a row in another table.
Although the primary key cannot have a NULL value, the unique constraints can. A table has just one main key, but it might have numerous unique constraints.
The Database Management System, or DBMS, is a collection of applications or programmes that allow users to construct and maintain databases.
A database management system (DBMS) provides a tool or interface for executing various database activities such as inserting, removing, updating, and so on.
It is software that allows data to be stored in a more compact and secure manner than a file-based system.
A database management system (DBMS) assists a user in overcoming issues such as data inconsistency, data redundancy, and other issues in a database, making it more comfortable and organised to use.
File systems, XML, the Windows Registry, and other DBMS systems are examples of prominent DBMS systems.
RDBMS stands for Relational Database Management System, and it was first introduced in the 1970s to make it easier to access and store data than DBMS.
In contrast to DBMS, which stores data as files, RDBMS stores data as tables.
When opposed to DBMS, storing data as rows and columns makes it easier to locate specific values in the database and makes it more efficient.
MySQL, Oracle DB, and other prominent RDBMS systems are examples.
The Checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
Preserving the log of each transaction and maintaining shadow pages are two methods that can assist the DBMS in recovering and maintaining the ACID properties.
When it comes to a log-based recovery system, checkpoints are necessary.
Checkpoints are the minimal points from which the database engine can recover after a crash as a specified minimal point from which the transaction log record can be utilised to recover all committed data up to the moment of the crash.
A database system is a collection of database and database management system software.
We can execute a variety of tasks using the database system, including:
The data can be easily stored in the database, and there are no concerns about data redundancy or inconsistency.
When necessary, data will be pulled from the database using DBMS software.
As a result, using database and DBMS software together allows you to store, retrieve, and access data with precision and security.
A data model consists of a set of tools for describing data, semantics, and constraints. They also assist in the description of the relationship between data entities and their attributes. Hierarchical data models, network models, entity relationship models, and relational models are some of the most prevalent data models. You may also learn more about data models by looking at other data modelling interview questions.
A checkpoint is a snapshot of the database management system's current state. The DBMS can use checkpoints to limit the amount of work that needs to be done during a restart in the event of a subsequent crash. After a system crash, checkpoints are utilised to recover the database. The log-based recovery solution employs checkpoints. When we need to restart the system because of a system crash, we use checkpoints. As a result, we won't have to execute the transactions from the beginning.
In a database, an entity is a real-world thing.
Employee, designation, department, and so on are examples of different entities in an employee database.
A trait that describes an entity is called an attribute.
For example, the entity "employee" can have properties such as name, ID, and age.
DBMS can handle a variety of interactions, including:
🚀Data definition
🚀 Update
🚀 Retrieval
🚀 Administration
Query optimization is the phase in which a plan for evaluating a query with the lowest estimated cost is identified.
When there are numerous algorithms and approaches to perform the same goal, this phase emerges.
The following are some of the benefits of query optimization:
• The output is delivered more quickly.
• In less time, a higher number of queries can be run.
• Reduces the complexity of time and space
A NULL value is not to be confused with a value of zero or a blank space. While zero is a number and blank space is a character, NULL denotes a value that is unavailable, unknown, assigned, or not applicable.
| Aggregation | Atomicity |
|---|---|
| This is an E-R model feature that allows one relationship set to interact with another relationship set. | This attribute specifies that a database alteration must either adhere to all of the rules or not at all. As a result, if one portion of the transaction fails, the transaction as a whole fails. |
In DBMS, there are three degrees of data abstraction.
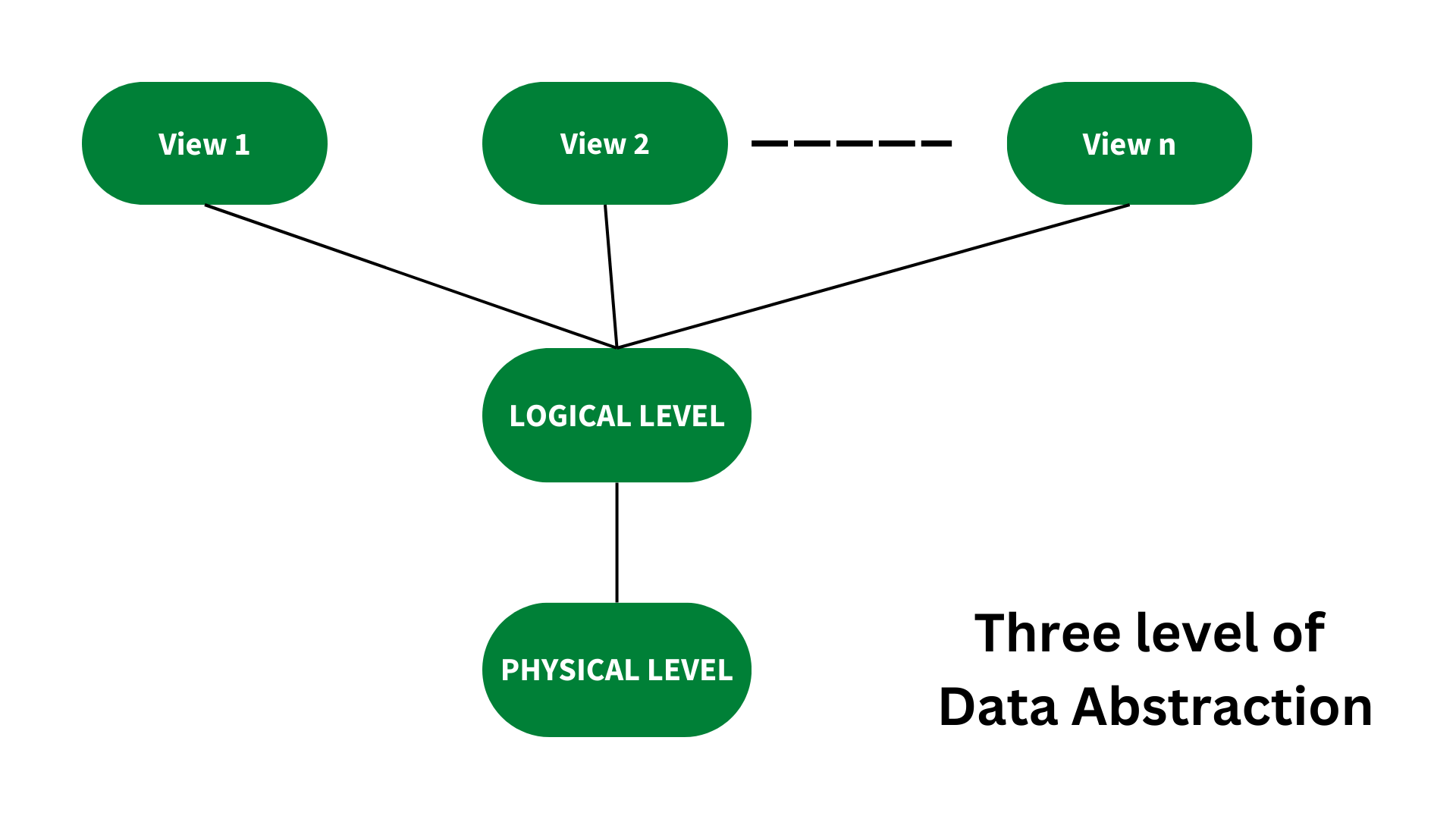
They are as follows:
🚀Physical Level : The physical level of abstraction specifies how data is stored and is the lowest degree of abstraction.
🚀Logical Layer : After the Physical level, there is the Logical level of abstraction.
This layer decides what data is saved in the database and how the data pieces relate to one another.
🚀
View Level: The greatest level of abstraction, the View Level describes only a portion of the entire database.
It's a diagrammatic approach to database architecture in which real-world things are represented as entities and relationships between them are mentioned. This method allows the DBA staff to quickly grasp the schema.
🚀Entity: An entity is a real-world object with attributes, which are nothing more than the object's qualities.
An employee, for example, is a type of entity.
This entity can have attributes like empid, empname, and so on.
🚀Entity Type: An entity type is a collection of entities with similar attributes.
An entity type, in general, refers to one or more related tables in a database.
As a result, entity type can be thought of as a trait that uniquely identifies an entity.
Employees can have attributes such as empid, empname, department, and so on.
🚀Entity Set: In a database, an entity set is a collection of all the entities of a specific entity type.An entity set can include, for example, a group of employees, a group of companies, and a group of persons.
The transparent DBMS is a form of database management system that conceals its physical structure from users. Physical structure, also known as physical storage structure, refers to the DBMS's memory manager and explains how data is saved on disc.
In relational algebra, the unary operations are PROJECTION and SELECTION.
Single-operand operations are known as unary operations.
SELECTION, PROJECTION, and RENAME are unary operations.
Relational operators, like as =,=,>=, and others, are employed in SELECTION.
Relational Database Management Systems (RDBMS) is an acronym for Relational Database Management Systems. It's used to keep track of data records and table indices. RDBMS is a type of database management system that employs structure to identify and access data about other pieces of data in the database. RDBMS is a database management system that allows you to update, insert, delete, manipulate, and administer a relational database with minimal effort. The SQL language is utilised by RDBMS the majority of the time since it is simple to grasp and is frequently employed.
There are number of data modesl and they are :
🚀 Hierarchical data model
🚀Network model
🚀Relational model
🚀Entity-Relationship model
A Relation Schema is a collection of properties that define a relationship.
Table schema is another name for it.
It specifies the name of the table.
The blueprint with which we may explain how data is grouped into tables is known as the relation schema.
There is no data in this blueprint.
A set of tuples is used to define a relation.
A connection is a collection of connected attributes with key attributes that identify them.
Consider the following scenario:
Let r be the relation containing set tuples (t1, t2, t3, ..., tn).
Each tuple consists of an ordered list of n-values (t=1) (v1,v2, ...., vn).
The degree of a relationship is one of its relation schema's attributes. A degree of connection, also known as Cardinality, is defined as the number of times one entity occurs in relation to the number of times another entity occurs. One-to-one (1:1), one-to-many (1:M), and many-to-one (1:N) are the three degrees of relation (M:M).
An association between two or more entities is characterised as a relationship.
In a database management system, there are three types of relationships:
🚀One-to-One: In this case, one record of any object can be linked to another object's record.
🚀One-to-Many (many-to-one): In this case, one record of any object can be linked to many records of other objects, and vice versa.
🚀Many-to-many: In this case, multiple records of one item can be linked to n records of another object.
tThe disadvantages of file processing systems are :
🚀 Data redundancy
🚀 Not secure
🚀 Inconsistent
🚀 Difficult in accessing data
🚀 Limited data sharing
🚀 Data integrity
🚀 Concurrent access is not possible
🚀 Data isolation
🚀 Atomicity problem
In a database management system, data abstraction is the process of hiding unimportant facts from users.
Because database systems are made up of complicated data structures, user interaction with the database is made possible.
For example, we know that most users prefer systems with a simple graphical user interface (GUI), which means no sophisticated processing.
As a result, data abstraction is required to keep the user engaged and to make data access simple.
Furthermore, data abstraction divides the system into layers, allowing the job to be stated and properly defined.
The following are some of the primary advantages of DBMS:
🚀Controlled Redundancy: DBMS enables a way to control data redundancy inside the database by integrating all data into a single database and preventing duplication of data because data is stored in just one location.
🚀Data Sharing: In a DBMS, data can be shared among several users at the same time because the same database is shared across all users and by various application applications.
🚀Backup and Recovery Facility: DBMS eliminates the burden of producing data backups over and over by including a 'backup and recovery' function that automatically produces data backups and restores them as needed.
🚀Integrity Constraints Must Be Enforced: Integrity Constraints must be enforced.
So That The Refined Data Is Stored In The Database And This Is Followed By DBMS
🚀Data independence: It basically means that you can modify the data structure without affecting the structure of any application applications.
In a select statement, HAVING is used to establish a condition for a group or an aggregate function. Before grouping, the WHERE clause picks. After grouping, the HAVING clause picks rows. The WHERE clause, unlike the HAVING clause, cannot contain aggregate functions.
A database transaction is a collection of database operations that must be handled as a whole, meaning that all or none of the actions must be executed. A bank transaction from one account to another is a good illustration. Either both debit and credit operations must be completed, or none of them must be completed. The ACID qualities (Atomicity, Consistency, Isolation, and Durability) ensure that database transactions are processed reliably.
An SQL Join is a technique for combining data from two or more tables based on a shared field.
Identity (or AutoNumber) is a column that creates numeric values automatically. It is possible to set a start and increment value, however most DBAs leave them at 1. A GUID column generates numbers as well, but the value cannot be changed. There is no need to index the identity/GUID columns.
A view is a virtual table created from a SQL statement's result set. We can use the create view syntax to do so.
The uses of view are as follows :
1. Views can represent a subset of the data in a table; as a result, a view can limit the extent to which the underlying tables are exposed to the outside world: a user may be allowed to query the view but not the whole of the base database.
2. Views allow you to combine and simplify numerous tables into a single virtual table.
3. Views can be used as aggregated tables, in which the database engine aggregates data (sum, average, and so on) and displays the generated results alongside the data.
4. Views can obscure data complexity.
5. Views take up extremely minimal storage space; the database simply maintains the specification of a view, not a copy of all the data it displays.
6. Views can give additional security depending on the SQL engine utilised.
A trigger is a code that is connected with inserting, updating, or deleting data. When a table's associated query is run, the code is automatically performed. Triggers are useful for maintaining database integrity.
A stored procedure is similar to a function in that it contains a collection of operations that have been put together. It includes a set of procedures that are frequently used in applications to perform database activities.
Triggers, unlike Stored Procedures, cannot be called directly. Only inquiries can be linked to them.
It is a method for assessing relation schemas based on their functional dependencies and primary keys in order to obtain the following desirable properties:
1. Keeping Redundancy to a Minimum
2. Reducing Insertion, Deletion, and Update Inconsistencies
Relation schemas that don't meet the properties are broken down into smaller relation schemas that might meet the requirements.
A database index is a data structure that improves the speed of data retrieval operations on a database table at the expense of more writes and storage space to keep the extra copy of data. On a disc, data can only be stored in one order. Faster search, such as binary search for different values, is sought to provide faster access according to different values. Indexes on tables are constructed for this purpose. These indexes take up more disc space, but they allow for speedier searches based on several frequently queried parameters.
Clustered indexes are the indexes that determine how data is stored on a disc. As a result, each database table can only have one clustered index. Non-clustered indexes define logical ordering rather than physical ordering of data. In most cases, a tree is generated, with the leaves pointing to disc records. For this, a B-tree or B+ tree is utilised.
Denormalization is a database optimization method in which duplicated data is added to one or more tables.
In SQL, a clause is a portion of a query that allows you to filter or personalise how your data is queried for you.
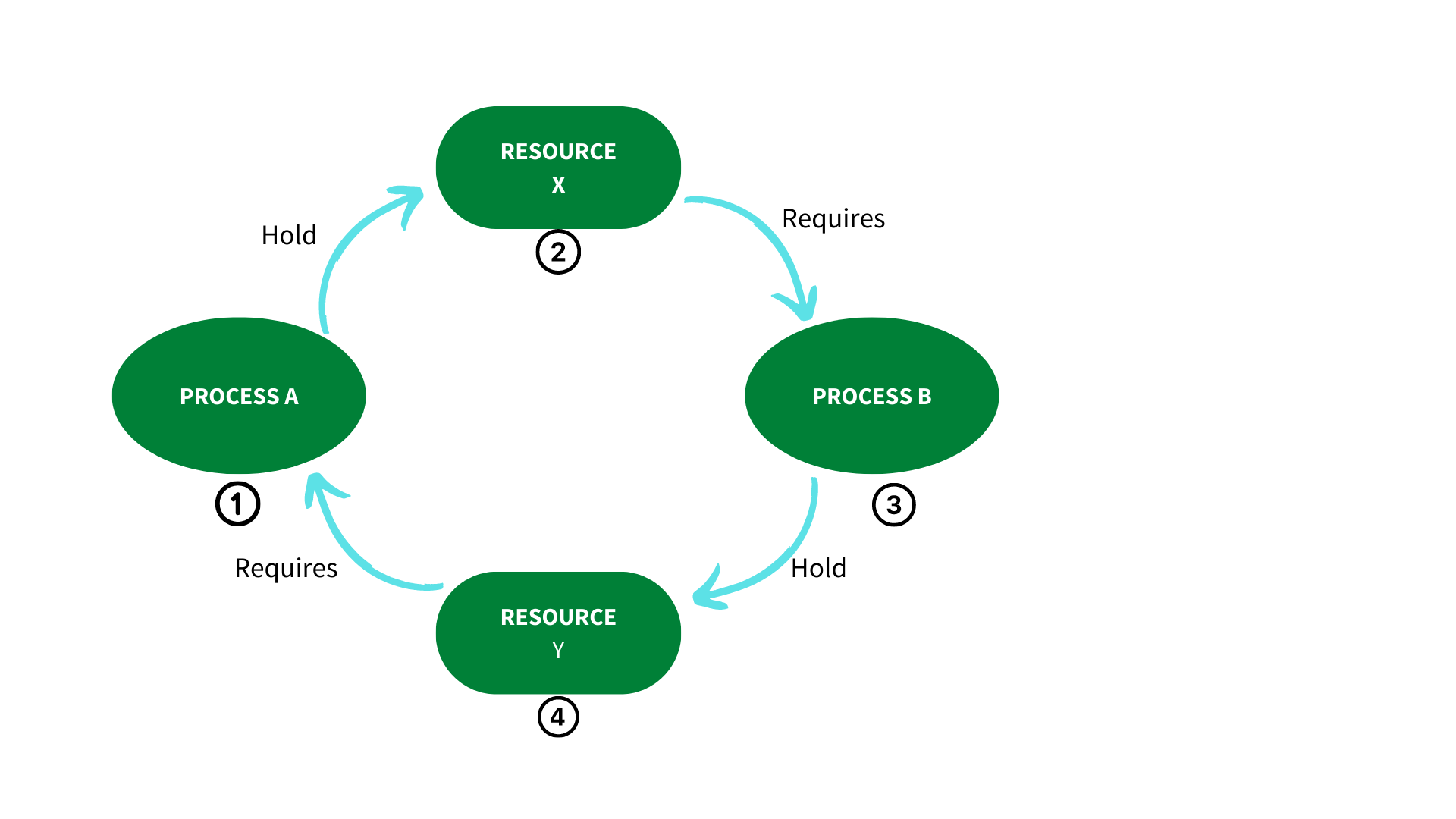
When two or more processes repeatedly repeat the same interaction in reaction to changes in the other processes without producing any beneficial work, this is known as a livelock situation. These processes are not in a condition of waiting, and they are all executing at the same time. This is distinct from a stalemate, which occurs when all processes are in a state of waiting.
Query-by-example is a visual/graphical technique to obtaining information in a database by using skeleton tables as query templates.
It's used to express what has to be done by explicitly entering example values into a query template.
Many database systems for personal computers use QBE.
QBE is a very strong tool that allows the user to access the information they want without having to know any programming languages.
Skeleton tables are used to express queries in QBE.
QBE has two distinguishing characteristics:
Queries in QBE use a two-dimensional syntax, which makes them look like tables.
A cursor is an object that stores the outcome of a query so that application programmes can process it row by row. SQL statements are statements that operate on a collection of data and return another set of data. Host language programmes, on the other hand, work in a row at a time. Cursors are used to move through a set of rows produced by a SQL SELECT statement included in the code. A cursor is similar to a pointer.
The practise of structuring the attributes of a database in order to decrease or remove data redundancy is known as database normalisation (having the same data but at different places).
Normalization's purpose:
1. It is used to clean up the relational table by removing duplicate data and database oddities.
2. By assessing new data types utilised in the table, normalisation helps to decrease redundancy and complexity.
3. It's a good idea to break down a huge database table into smaller tables and use relationships to connect them.
4. It prevents duplicate data from being entered into a database, as well as no recurring groups.
5. It lowers the likelihood of anomalies in a database.
Database state refers to the collection of data kept in a database at a specific point in time, whereas database schema refers to the database's overall design.
SQL stands for Structured Query Language, and its primary purpose is to interact with relational databases by entering, updating, and altering data in the database.
Primary Key is used to uniquely identify records in a database table, whereas Foreign Key is used to connect two or more tables together, since it is a specific field(s) in one database table that is the primary key of another table.
Employee and Department are two tables, for example.
Both tables have a similar field/column called 'ID,' which is the primary key for the Employee table and the foreign key for the Department table.
A few discrepancies are listed below:
The primary distinction between the Primary and Unique keys is that the Primary key can never contain a null value, whereas the Unique key can.
There can only be one main key in each table, although there can be multiple unique keys in a table.
A sub-query is a query that is contained within another query. It is also known as an inner query because it is found within the outer query.
The DROP command is a DDL command that deletes an existing table, database, index, or view from a database.
The following are the main differences between the DROP, TRUNCATE, and DELETE commands:
The DDL commands DROP and TRUNCATE are used to delete tables from the database, and after the table is gone, all rights and indexes associated with the table are likewise deleted.
Because these two actions cannot be reversed, they should only be utilised when absolutely required.
The DELETE command, on the other hand, is a DML command that may also be rolled back to delete rows from a table.
UNION and UNION ALL are both used to connect data from two or more tables, but UNION removes duplicate rows and selects the distinct rows after merging the data from the tables, whilst UNION ALL does not remove duplicate rows and simply selects all of the data from the tables.
A nested query, or a query written inside another query, is known as a subquery. A Correlated Subquery is defined as a Subquery that is conducted for each row of the outer query.
In a database management system, there are two major integrity rules.
🚀Entity Integrity: This is a crucial rule that stipulates that the value of a primary key can never be NULL.
🚀Referential Integrity: This rule is connected to the Foreign key and stipulates that a Foreign key's value must be NULL or it must be the primary key of another relation.
In relational databases, the E-R model is known as an Entity-Relationship model, and it is built on the concept of Entities and the relationships that exist between them.
This is a constraint that can be used to describe the relationship between the various attributes of a relation.
For example, if a relation 'R1' has two attributes, Y and Z, the functional dependency between these two qualities can be represented as Y->Z, indicating that Z is functionally dependent on Y.
Pattern matching is feasible in SQL with the help of the LIKE operator. When the LIKE operator matches 0 or more characters, 'percent' is used, while '_' is used when it matches a single character.
Data warehousing is the process of collecting, extracting, processing, and importing data from numerous sources and storing it in a single database. A data warehouse can be thought of as a central repository for data analytics that receives data from transactional systems and other relational databases. A data warehouse is a collection of historical data from an organisation that aids in decision-making.
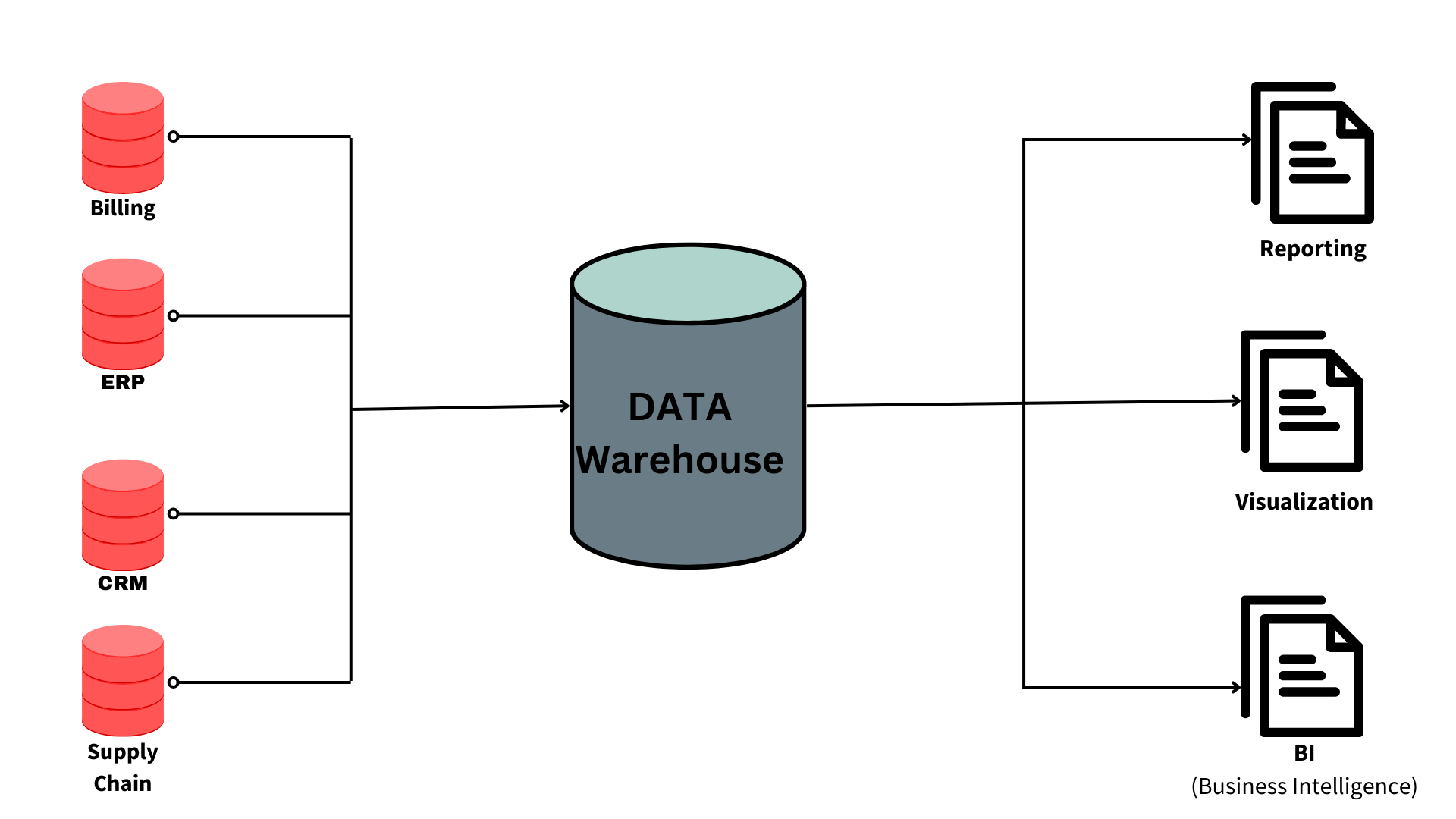
The main distinction between intension and extension in a database is as follows:
Intension: Intension, also known as database schema, is used to define the database's description. It is specified throughout the database's design and typically remains unmodified.
Extension, on the other hand, is a measurement of the number of tuples in a database at any particular point in time.
The snapshot of a database is also known as the extension of a database, and its value changes as tuples are created, updated, or destroyed in the database.
DELETE command: This command is used to delete rows from a table based on the WHERE clause's condition.
🚀It only deletes the rows that the WHERE clause specifies.
🚀
If necessary, it can be rolled back.
🚀
It keeps a log to lock the table row before deleting it, which makes it slow.
TRUNCATE command :The TRUNCATE command is used to remove all of the data from a table in a database.
It's similar to a DELETE command without a WHERE clause.
🚀
It deletes all of the data from a database table.
🚀It can be rolled back if necessary.
(Depending on the database version, truncate can be rolled back, but it's hard and can result in data loss.)
🚀
It doesn't keep a log and deletes the entire table at once, so it's quick.
A database lock is a method that prevents two or more database users from updating the same piece of data at the same time.
When a lock is acquired by a single database user or session, no other database user or session can edit the data until the lock is released.
🚀 Shared Lock :A shared lock is necessary for reading a data item, and in a shared lock, multiple transactions can hold a lock on the same data item.
A shared lock allows many transactions to read the data items.
🚀Exclusive Lock :A lock on any transaction that is about to perform a write operation is known as an exclusive lock.This form of lock prevents any database inconsistency by allowing just one transaction at a time.
The major normalisation forms in a database management system are as follows:
1. 1 NF :The first normal form, sometimes known as the first normal form, is the most basic sort of database normalisation.
The following conditions must be met for a table to be in its initial normal form:
🚀
Every column should have only one value and be atomic.
🚀
Columns from the same table that are duplicated should be eliminated.
🚀
For each category of linked data, separate tables should be constructed, and each entry should be recognised by a distinct column.
2. 2NF : The second normal form is referred to as 2NF.
The following conditions must be met for a table to be in its second normal form:
🚀
The table should be in its 1NF state, which means it must meet all of the 1NF requirements.
🚀
Every non-prime attribute of the table should be entirely functionally reliant on the main key, i.e., every non-key attribute should be dependant on the primary key in such a way that if any key element is destroyed, the database will still save the non key element.
3. 3NF : The third normal form is referred to as 3NF.
The following conditions must be met for a table to be in its second normal form:
🚀
The table should be in its 2NF state, which means it must meet all of the 2NF requirements.
🚀
One property does not have a transitive functional dependency on any other attribute in the same table.
4. BCNF :BCNF is an advanced form of 3NF that stands for Boyce-Codd Normal Form.
For the same reason, it's also known as 3.5NF.
The following conditions must be met for a table to be in its BCNF normal form:
🚀
The table should be in its 3NF state, which means it must meet all of the 3NF requirements.
🚀
A should be the table's super key for any functional dependency of any attribute A on B (A->B).
🚀It simply means that if B is a prime attribute, A cannot be a non-prime attribute.
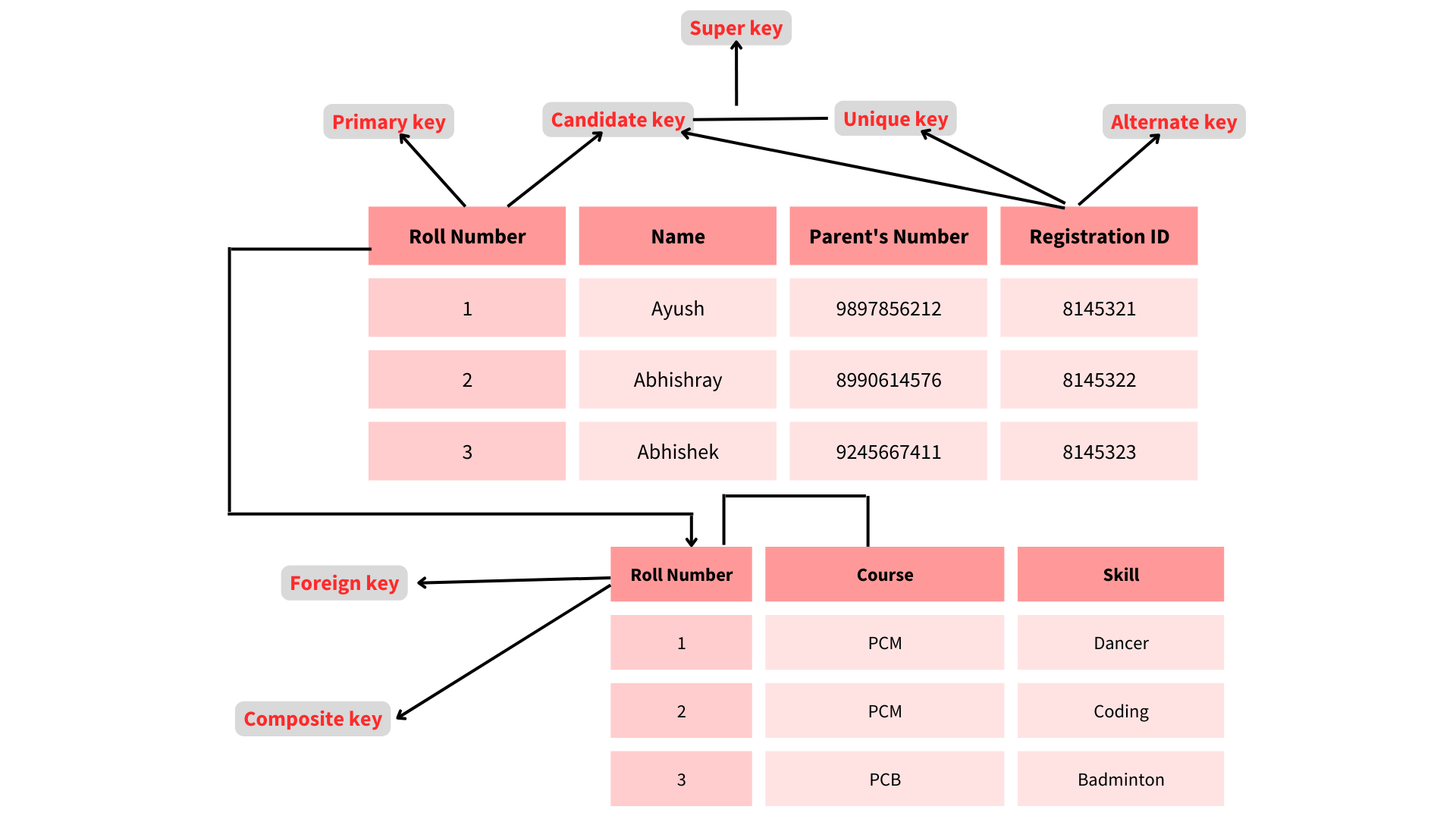
In a database, there are primarily seven types of keys:
🚀Candidate Key: A set of features that can be used to uniquely identify a table is referred to as a candidate key.
There may be numerous candidate keys in each table.
A primary key can be chosen from among all candidate keys.
🚀Super Key :
The super key is a set of properties that can be used to uniquely identify a tuple.
Candidate and main keys are subsets of the super key, with the super key being their superset.
🚀Primary Key :The main key specifies a collection of characteristics that are used to uniquely identify each tuple.
StudentId and firstName are candidate keys in the example below, and any of them can be used as a Primary Key.
🚀
Unique Key: A unique key is identical to a primary key, with the exception that primary keys do not accept NULL values in columns, whereas unique keys do.
Unique keys are just primary keys with NULL values.
🚀
Alternate Key: All candidate keys that were not selected as primary keys are referred to as alternate keys.
🚀Foreign Key: A foreign key is an attribute that can only take values from one table and is shared by an attribute in another table.
🚀Composite Key :
A composite key is a combination of two or more columns that allows each tuple in a table to be uniquely identified.
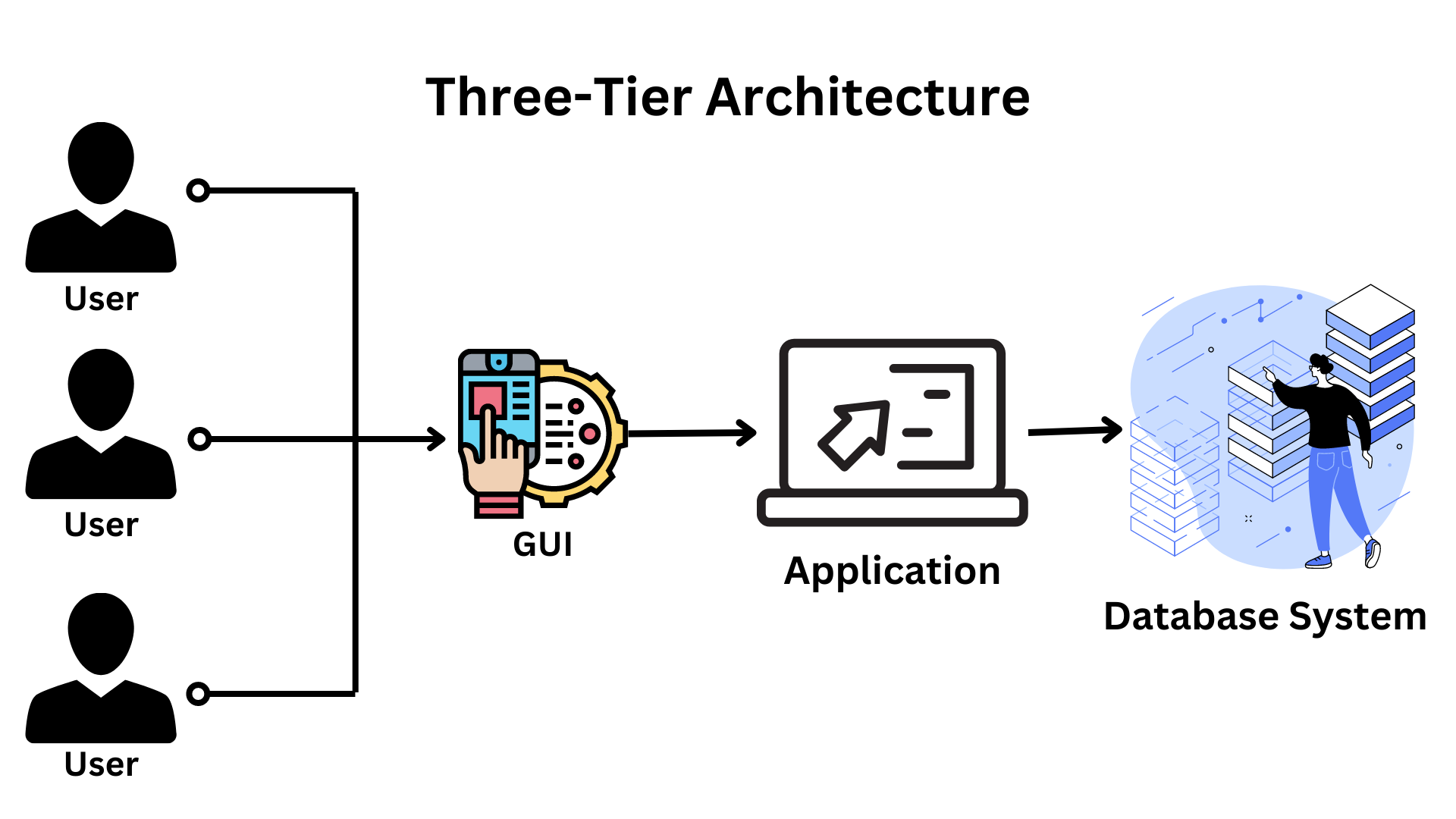
The 2-tier architecture : It is a client-server architecture in which client applications interface directly with the database on the server end without the use of any middleware.
For instance, a Contact Management System built in MS-Access or a Railway Reservation System, for example.
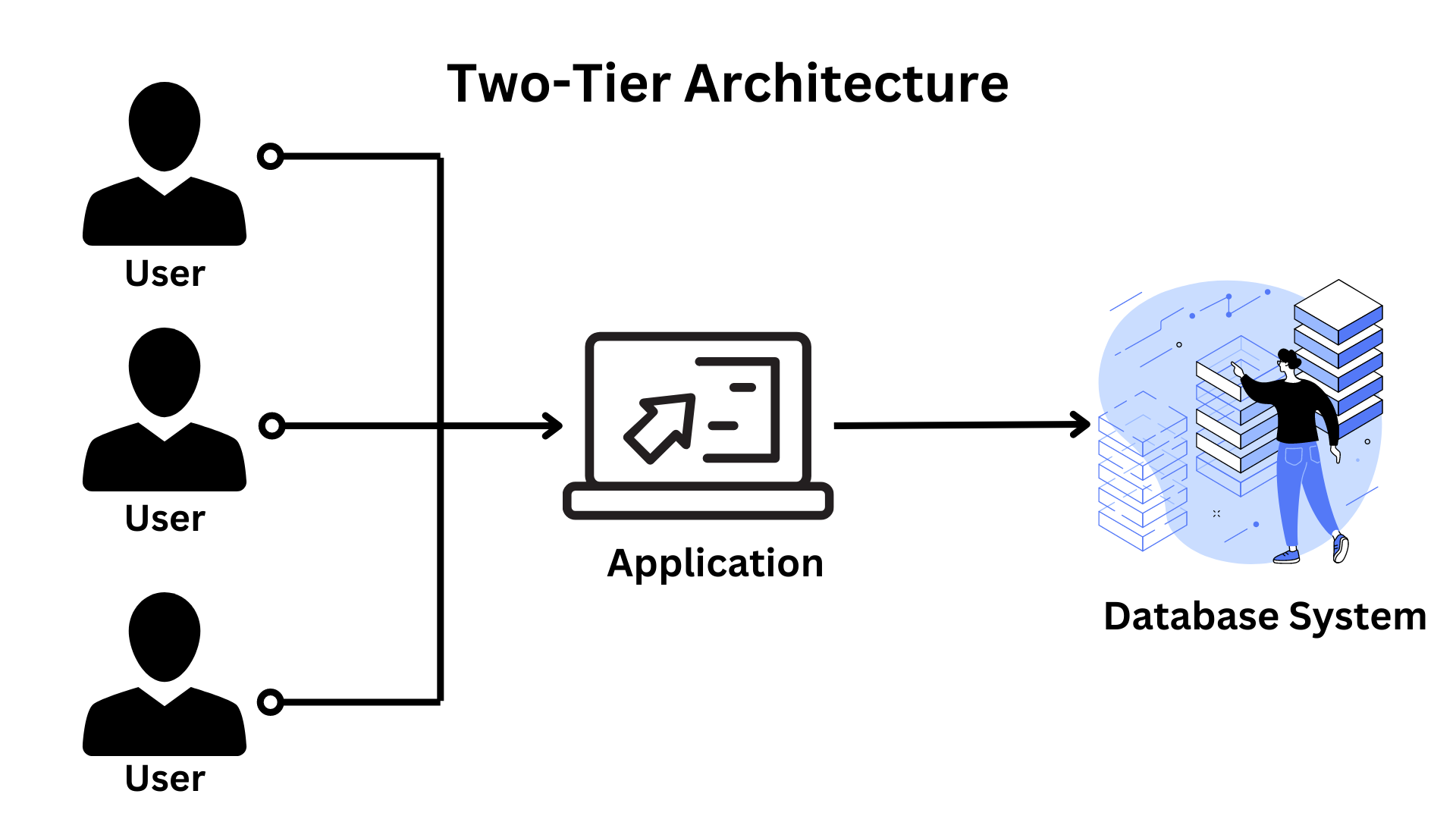
The 3-tier design : It adds a layer between the client and the server to give users a graphical user interface and make the system more safe and accessible.
In this form of design, the client-side application communicates with a server-side application, which then communicates with the database system.
Designing a registration form with a text box, label, button, or a large website on the Internet, as an example.
| Logical database design | Physical database design |
|---|---|
| The conceptual schema (or an ER schema) from the high-level data model is mapped or transformed into a relational database structure. | The specifications for the stored database are created, including physical storage structures, record placement, and indexes. |
| The mapping process can be divided into two stages:
🚀 Data model-dependent but system-independent mapping 🚀 Adapting the schemas to a certain database management system | The criteria listed below are frequently used to inform the selection of physical database design options:
🚀 Space Utilization 🚀Response Time 🚀 Throughput of transactions |
| DDL statements in the chosen DBMS language that define the database system's conceptual and external level schemas. However, if the DDL statements incorporate physical design parameters, the DDL specification must be performed after the physical database design step is completed. | An first determination of database file storage architecture and access pathways. In terms of Data Storage Definition Language, this relates to defining the internal schema. |
There are various stages to database design. Two of them are logical database design and physical database design. This separation is usually based on the three-level design of a database management system (DBMS), which ensures data independence. As a result, we may argue that this separation leads to data independence since the logical database design's output is the database system's conceptual and external level schemas, which are independent of the physical database design's output, which is an internal schema.
Temporary tables are tables that are only used for a single session or whose data is only kept for the duration of the transaction. Temporary tables are most commonly utilised to support unique rollups or specific application processing needs. A temporary table does not have space given to it when it is formed, unlike a permanent table. As rows are added, space for the table will be dynamically allotted. To build a temporary table in Oracle, use the CREATE GLOBAL TEMPORARY TABLE command.
Entity type extension is the process of combining comparable entity types into a single type that is then grouped together as an entity set.
The first step in the database design process is conceptual design. At this stage, the goal is to create a database that is unaffected by database software or physical details. A conceptual data model describes the primary data items, properties, relationships, and constraints of a specific issue domain as a result of this procedure.
In the Oracle database differnt types of failures can occur, some of them are given below:
🚀Bad data type
Insufficient space
🚀 Instance Failure
Media Failure
The user drops a table
User damages data by modification
Alert Logs
Records informational and error messages
All Instance startups and shutdowns are recorded in the log
🚀 User Process Failure
The user performed an abnormal disconnect
The user’s session was abnormally terminated
The user’s program raised an address exception
🚀 User Error
The user drops a table
User damages data by modification
🚀 Statement Failure·
🚀 Insufficient Privileges
The acronym RAID stands for Redundant Array of Inexpensive (or "Independent")Disks.
RAID is a technique for merging many hard drives into a single logical unit (two or more discs grouped together to appear as a single device to the host system).
RAID was created to overcome the fault-tolerance and performance limitations of traditional disc storage.
It can provide greater fault tolerance and throughput than a single hard disc or a collection of independent hard drives.
Arrays were originally thought to be complex and specialised storage solutions, but they are now simple to use and critical for a wide range of client/server applications.
The process of splitting a logical database into independent components to improve availability, performance, and manageability is known as data partitioning.
The following are some of the reasons why database partitioning is important:
🚀
Allows you to access significant portions of a partition.
🚀
Data can be stored on low-cost, slower storage.
🚀
Improves the speed of queries
The DML Compiler converts DML statements into query language that can be understood by the query evaluation engine. Because DML is a set of grammar elements that is quite similar to other programming languages that require compilation, a DML compiler is necessary. As a result, it's critical to compile the code in a language that the query evaluation engine understands, and then work on the queries with the appropriate output.
Relational Algebra is a Procedural Query Language that includes a collection of operations that accept one or two relations as input and output a new relationship.
The relational model's basic set of operations is known as relational algebra.
The key feature of relational algebra is that it resembles algebra that operates on numbers.
Relational algebra has only a few basic operations:
🚀
set difference
🚀 project
🚀 select
🚀 union
🚀rename,etc.
Relational Calculus is a non-procedural query language that instead of algebra employs mathematical predicate calculus.
Relational calculus does not work with math essentials like algebra, differential equations, integration, and so on.
It's also known as predicate calculus because of this.
Relational calculus is divided into two types:
🚀
Relational calculus in a tuple
🚀
Calculus of Domain Relationships
Even if the system fails before all of the changes are reflected on disc, the effect of a transaction should endure once the DBMS alerts the user that it has completed successfully. Durability is the term for this quality. Durability guarantees that once a transaction is committed to the database, it will be stored in non-volatile memory, where it will be safe against system failure.
From 1974 through 1979, IBM San Jose Research Centre conceived and built System R.
System R was the first to demonstrate that a relational database management system (RDBMS) could give higher transaction processing performance, and it was also the first to implement SQL, the standard relational data query language.
It's a working prototype that demonstrates how to create a Relational System that can be utilised in a real-world setting to address real-world problems.
Two primary subsystems of System R are as follows:
🚀
Relational Data System
🚀
Research Storage System
To interface with the RDBMS, you must utilise Structured Query Language (SQL). We can offer input to the database using SQL queries, and the database will provide us with the required output when the queries have been processed.
🚀Proactive Update: These changes are made to the database before it is put into use in the actual world.
🚀
Retroactive Updates: These updates are applied to a database after it has been operational in the real world.
🚀
Simultaneous Update: These updates are applied to the database at the same moment as they become effective in the actual world.
🚀Specialization is the process of defining a set of subclasses for a particular entity type.
Each subclass will contain all of the parent entity's characteristics and relationships.
Aside from that, subclasses may have additional attributes and relationships that are unique to them.
🚀
Generalization is the process of identifying relationships and common attributes among a group of entities, and then defining a common superclass for them.
The term "fill factor" refers to the percentage of space left on each leaf-level page that is densely packed with information. The default number is usually 100.
Index hunting is the process of enhancing a collection of indices.
This is done because indexes improve query performance as well as query processing time.
It aids in query performance improvement in the following ways:
🚀
Using the query optimizer, the optimal queries are suggested.
🚀
To check the effect, measurements such as index, query distribution, and performance are used.
🚀
Databases are optimised for a small number of problem queries.
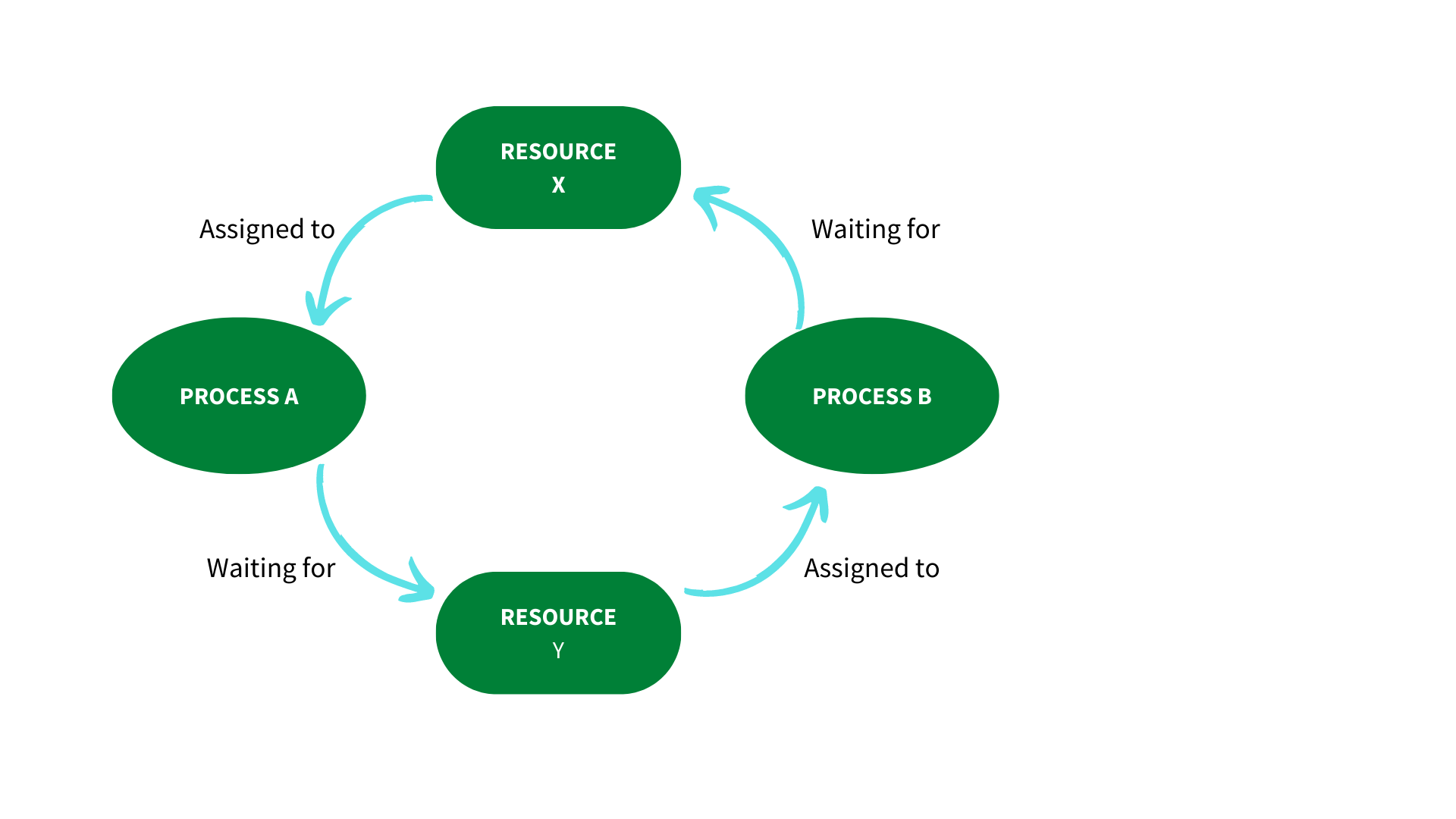
A deadlock occurs when two transactions wait for a resource that is unavailable or while another operation is halted. Deadlocks can be avoided by requiring all transactions to acquire all locks at the same time. As a result, the only way to break the deadlock is to abort one of the transactions and remove the partially completed work.
When you want to ensure that a database is unique, you can use an index. It can also be used to simplify sorting and retrieve data quickly. A frequently used column may be an excellent candidate for an index.
We have now reached the end of this page. With the knowledge from this page, you should be able to answers your interview question confidently.
Database Management System (DBMS). This program allows database creation, organization, management, and manipulation. Databases store, manage, and access structured data electronically. DBMS ensures data integrity, security, and concurrency while efficiently storing, retrieving, and manipulating data.
DBMS mediates between users and the physical database. It simplifies data management and processing by providing tools to create, change, and query databases. Oracle, MySQL, SQL Server, PostgreSQL, and MongoDB are popular DBMSs.
DBMS features include:
Data Definition Language (DDL): DDL creates, modifies, and deletes database objects like tables, indexes, and constraints. It defines the database's structure, including table relationships, data types, and integrity constraints.
Data Manipulation Language (DML): DML lets users manipulate database data. INSERT, UPDATE, DELETE, and SELECT allow database data to be inserted, modified, deleted, and retrieved. DML lets you query data based on conditions and criteria.
Data Query Language (DQL): DML's data retrieval subset is DQL. It lets users utilize conditions, joins, sorting, grouping, and aggregating methods to query multiple tables. Relational database DQL SQL is popular.
Data Control Language (DCL): DCL controls access and security to protect data. GRANT and REVOKE allow administrators to grant or revoke database object permissions to users or roles. DCL allows fine-grained data access and security controls.
Data Transaction Management: DBMS ensures database transaction ACID qualities (atomicity, consistency, isolation, and durability). Database operations form transactions. DBMS executes transactions reliably and concurrently without data corruption.
Data Concurrency Control: DBMS systems handle data access and modification by numerous users or applications. Locking, timestamp ordering, and optimistic concurrency control keep DBMS data consistent. These strategies prevent data corruption and conflicts in multi-user contexts.
Data Recovery and Backup: DBMS allows data backup, restoration, and recovery in case of system failures, crashes, or data corruption. Full, incremental, and differential backups protect data against loss.
Data Integrity and Constraints: DBMS allows data integrity constraints on database data. Data constraints ensure uniqueness, referential integrity, data types, and range checks. DBMS maintains data correctness and consistency by following restrictions.
Data normalizing and Optimization: DBMS provides data normalizing to eliminate redundancy and improve data integrity. It also optimizes database queries. Indexing, query execution strategies, and caching speed up query processing.
In summary, a DBMS is a software system that manages databases, providing tools and functions to create, organize, manipulate, and retrieve data efficiently. It facilitates data definition, manipulation, query
DBMS improve data management and system performance. Discussing these benefits:
1. Data Integrity: DBMS enforces integrity restrictions and regulations on stored data. Primary keys, unique keys, foreign keys, and check constraints assist guarantee data accuracy and consistency. Preventing incorrect or inconsistent data from entering the database preserves data integrity.
2. Data Security: DBMS safeguards data from unauthorized access. It has authentication, access control, data encryption, and auditing. These security procedures prevent unauthorized access, modification, or viewing of sensitive data.
3. Data Consistency: DBMS enforces relationships and referential integrity between tables via foreign keys. It preserves data dependencies and makes database modifications consistent. Consistent data eliminates redundancy and data abnormalities, ensuring data accuracy.
4. Data Sharing: DBMS lets users and programs share data. Multiple people can access the database simultaneously. DBMS locks and controls concurrency to ensure data consistency and integrity.
5. Data Access: DBMS optimizes data access. Indexes allow quick data lookup and retrieval based on certain criteria. Indexes speed up queries by avoiding data scanning. The DBMS also optimizes query execution plans, speeding up data retrieval.
6. Concurrency Control: DBMS controls concurrent data access to prevent conflicts and data discrepancies. Locking or timestamp ordering coordinate access to shared resources to prevent race situations and data corruption.
7. Data Backup and Recovery: DBMS allows data backup, restoration, and recovery after system failures, crashes, or data corruption. Database backups help prevent data loss and assure data availability. DBMS uses transaction logs or backup files to restore databases after failures.
8. Data Normalization: Data normalization reduces redundancy and improves data integrity in DBMS. Normalization organizes data into many tables, reducing duplication and optimizing storage. Normalization reduces data abnormalities and inconsistencies, improving data management and quality.
9. Better Data Management and Organization: DBMS systems help organize and manage data. It supports database structure creation, relationship definition, and data access permissions. DBMS also streamlines data management by monitoring performance, optimizing queries, and managing data dictionaries.
In conclusion, a DBMS provides data integrity, security, consistency, sharing, efficient data access, concurrency control, backup and recovery, normalization, and improved data management and organization. DBMS is vital for data management in many applications and sectors due to its reliability, performance, and flexibility.The process of structuring data in a database to lessen redundancy, get rid of anomalies, enhance data integrity, and maximize storage is known as normalization.
It is a key idea in database architecture. It entails segmenting big tables into smaller, more manageable chunks and creating connections between these chunks using keys.
Eliminating data redundancy, which happens when the same data is kept in various locations in a database, is the major goal of normalization. The correctness and dependability of the data may be impacted by redundancy-related inconsistencies and anomalies, such as data inconsistencies and update anomalies.
The normal forms of database normalization are a set of guidelines that normalization adheres to. The following are the most typical normal forms:
1. First Normal Form (1NF): In 1NF, data is arranged in tables, and each attribute's (column's) value is an indivisible atomic value. It ensures that each attribute has a single value and gets rid of repetitive groups.
2. Second Normal Form (2NF): 2NF improves on 1NF by guaranteeing that each column in a table that isn't a main key is completely reliant on all of the other columns in the table. Partial dependencies—where non-key qualities rely on just a portion of the primary key—are eliminated.
3. Third Normal Form (3NF): By removing transitive relationships, 3NF substantially improves database design. It makes sure that non-key attributes in the same table depend only on the primary key and not on any other non-key attributes.
More stringent normalizing criteria and dependencies are addressed by further normal forms, such as the Boyce-Codd Normal Form (BCNF), Fourth Normal Form (4NF), and Fifth Normal Form (5NF).
Decomposing large tables into smaller ones is a process known as normalizing, commonly referred to as normalization decomposition. By detecting functional dependencies and segmenting tables according to these dependencies, this approach aids in reaching the required normal form. A unique entity or relationship in the database is represented by each of the generated tables.
Additionally, normalization creates connections across tables by employing keys, typically primary and foreign keys. While foreign keys connect tables by referencing the main key of another table, primary keys uniquely identify records in a table. These connections guarantee consistency and data integrity among connected tables.
Normalization has advantages that include:
• Integrity of the Data
• Consistency of Data
• Enhancements to Data Storage
• Simplified Database Architecture
It's crucial to keep in mind that the process of normalization necessitates comprehensive examination and consideration of the unique requirements of the database and its intended usage. While normalization aids in data organization and integrity improvement, it is crucial to balance normalization with the necessity for effective data retrieval and performance.
To organize and arrange data, a variety of database models are utilized. The most typical varieties are listed below:
1. Hierarchical Model: The hierarchical model shows data in a tree-like form with parent-child relationships between each item. It forms a hierarchy out of parent nodes and child nodes. Children can have more than one parent, but only one parent can have a given child. For the representation of one-to-many relationships, this paradigm works well. However, when working with complicated data linkages, it can be rigid and difficult to maintain.
2. Network Model: A development of the hierarchical model, the network model enables more adaptable linkages between records. It makes use of a graph-like structure where sets (links) are used to connect data elements (called nodes). This approach has stronger querying capabilities and allows many-to-many relationships. However, because of the development of the relational model, it has become less popular because it can be difficult to install and maintain.
3. Relational Model: The relational model is the database model that is most frequently utilized. Data is arranged into tables, each of which represents an entity, and the connections between entities are made using keys. In the relational model, data is represented as rows (tuples) and columns (attributes) using a set theory-based methodology. The capacity to construct associations between tables using primary keys and foreign keys, which facilitates effective data retrieval and manipulation, is the main characteristic of the relational model. This concept serves as the foundation for relational databases and the Structured Query Language (SQL).
The object-oriented approach represents data as objects, much like how objects are described in object-oriented programming languages. 4. Encapsulation, inheritance, and polymorphism are all included in it. The objects in this paradigm can be classified into classes and hierarchies and contain characteristics (properties) and behaviors (methods). This paradigm enables the storage of rich, structured data and is appropriate for sophisticated data structures. This model serves as the foundation for object-oriented databases (OODBs) and object-relational mapping frameworks (ORMs).
The Entity-Relationship (ER) model, which concentrates on entities, attributes, and relationships, is another less popular database architecture. NoSQL databases use the Document Model, which stores data as semi-structured or unstructured documents.
According to certain use cases and requirements, each database model has advantages and things to keep in mind. The relational model is most frequently used in business applications and serves as the basis for many enterprise systems due to its simplicity, adaptability, and wide adoption. Other models, such object-oriented or NoSQL models, on the other hand, are more suited to certain applications or domains and address needs like complicated data structures or scalability. The choice of database model is influenced by a number of variables, including the complexity of the data, the linkages, the performance standards, and the particular functionality and capabilities that each model offers.
The identification and distinction of records within a table is made possible through the use of a primary key, a fundamental idea in database management. Each row or record in a table is uniquely identified by a column or group of columns. No two rows in the database can have the same primary key value, which ensures the uniqueness and integrity of the data within.
The following are some essential ideas concerning primary keys:
1. Uniqueness: Each entry in the table's primary key must have a different value. It guarantees that each row can be distinguishable from others in the same table and individually identified. The preservation of data integrity and the avoidance of data duplication or discrepancies depend on its uniqueness.
2. Integrity and Consistency of Data: The primary key constraint makes sure that the primary key column(s) cannot have null values or duplicate data. The accuracy and consistency of the data in the table are ensured by this constraint. Data redundancy, data abnormalities, and data conflicts are all avoided.
3. Relationship Establishment: In a relational database, relationships between tables are created using primary keys. Relationships can be established by specifying a primary key in one table and using it as a foreign key in another. These connections make it possible to easily link and access data from other tables, which helps with data retrieval, consistency, and integrity.
4. Quick and Effective Data Retrieval: Because primary keys are used as unique identifiers, data retrieval procedures are quick and effective. The database system can easily find and access the particular record(s) when a primary key is used in a query based on the primary key value(s). The creation of indexes on primary key columns can improve search and retrieval processes even more.
5. Column(s) Selection: The stability and uniqueness of the data determine which primary key column or columns should be used. A primary key should ideally be made up of one or more columns with constant, unchanging values. Unique identifiers, such as auto-incremented integers, GUIDs (Globally Unique Identifiers), or natural keys (columns with naturally unique values, like social security numbers), are popular options for primary keys.
6. Primary Key Constraints: To ensure that the defined column(s) serve as a primary key, DBMSs offer techniques to enforce primary key constraints. Any infraction of the integrity or uniqueness rules is prevented by these restrictions. The database system will automatically check for duplicate or null values when defining a primary key and reject them.
Databases can effectively manage and retrieve data, uphold data integrity, and create connections across tables by using primary keys. In relational databases, the idea of primary keys is essential because it gives users a dependable way to identify entries uniquely and ensures that the data is accurate and consistent throughout the system.
A foreign key is a concept in database management that establishes relationships between tables by linking a field or a set of fields in one table to the primary key of another table. It serves as a reference to the primary key in another table, creating a link between the two tables and enabling the enforcement of referential integrity constraints.
Foreign key basics:
1. Relationship Establishment: One table's foreign key links to another's main key. This relationship links data in the two tables based on shared values.
2. Referential Integrity: Foreign keys ensure referential integrity. Referential integrity verifies table relationships. It prevents "orphaned" records by preventing foreign key values from referencing non-existent primary key values in associated tables.
3. Parent and Child Tables: The parent table is the one with the main key, while the child table has the foreign key. The child table "inherits" the primary key values from the parent table, linking them.
4. Relationship Types: Foreign keys can indicate one-to-one, one-to-many, or many-to-many relationships. Each record in the child table has one parent table record, and vice versa. In a one-to-many relationship , each child table record can be connected with numerous parent table records, but each parent table record is associated with only one child table record. Both tables can have many-to-many relationships.
5. Cascading Actions: DBMSs allow foreign key cascading. When a parent table record is updated or destroyed, cascading actions affect linked child table records. CASCADE, SET NULL, SET DEFAULT, and RESTRICT are common cascading actions.
6. Data Retrieval: Foreign keys are essential for linking tables to get relevant data. Foreign keys can integrate data from various tables depending on relationships. Joins enable meaningful analysis by retrieving data from both parent and child tables.
Foreign keys are necessary for data integrity and relational database relationships. They maintain referential integrity, avoid orphaned records, facilitate efficient joins, and ensure data consistency across connected tables. To construct a well-structured and integrated data model, carefully examine foreign key relationships while designing a database.
Clustered and non-clustered indexes differ in database structure and usefulness.
Clustered Index: A clustered index arranges table rows. It organizes disk data by reordering table rows by indexed column values. Thus, the clustered index determines table storage order.
This physical reordering limits tables to one clustered index.
Clustered Index Facts:
1. Physical Data Order: The clustered index determines disk data order. The indexed column(s) physically sort the table's data rows.
2. Storage Impact: Since the clustered index controls physical storage order, adding or rebuilding one on a table can change its storage structure. Rearranging data takes time and resources.
3. Performance Benefit: Since data is physically ordered, a clustered index can retrieve rows faster for range scans or data retrieval by indexed column(s). It organizes and accesses table data.
A non-clustered index is independent from the table data. It has an index key and data row pointers. Tables can have several non-clustered indexes.
Non-Clustered Index Facts:
1. Separate Data Structure: Non-clustered indexes are stored independently from data rows. It points to the table rows with the indexed column(s).
2. Faster Data Retrieval: The non-clustered index retrieves data faster when searching or filtering on indexed columns. It saves time by referencing data rows.
3. Additional Storage Space: Since a non-clustered index is a separate structure, it requires more storage than table data. This space holds the index key and pointers.
4. several Indexes: Unlike clustered indexes, which can only have one per table, non-clustered indexes can have several per table. various queries require various non-clustered indexes.
In summary, a clustered index dictates the actual order of data rows in a table, while a non-clustered index is a different structure that enables a rapid reference. Only one clustered index can physically order data in a table, but many non-clustered indexes can increase query performance by providing alternate data access methods. Data needs and query optimization determine whether to use a clustered or non-clustered index.
Database management systems (DBMS) use ACID attributes to ensure transaction dependability, integrity, and durability. Atomicity, Consistency, Isolation, and Durability are ACID. Detailing each property:
1. Atomicity: Atomicity makes a transaction a single, indivisible unit of work. The "all-or-nothing" approach means that either the entire transaction is successful or none of the database changes are performed. The entire transaction is rolled back if any part fails or errors out, leaving the database untouched. Atomicity ensures data integrity and prevents database inconsistency from partial transaction completion.
2. Consistency: Consistency keeps the database valid before and after a transaction. Transactions change the database state. It imposes database schema integrity requirements, data validation, and domain-specific rules. Consistency ensures database accuracy and correctness by meeting predetermined rules and limitations. To maintain consistency, rolled back transactions that break limitations are undone.
3. Isolation: Isolation prevents concurrent transactions from interfering. It isolates each transaction from other concurrent transactions until it is committed. Isolation prevents data inconsistencies and conflicts from concurrent data access. Each transaction seems to run alone, guaranteeing data integrity and preventing interference between operations.
4. Durability: Durability ensures that a transaction is persistent and will survive system failures like power outages or crashes. To preserve committed transaction modifications, disk or non-volatile memory is used. Logged changes can restore the database after a system failure. Durability protects data from unexpected events.
DBMS transaction management is strengthened by ACID characteristics. They keep database transactions reliable, consistent, segregated, and durable independent of concurrent access or system faults. These features are essential for data integrity, database validity, and important system reliability and fault tolerance.
Transaction logs, locking protocols, concurrency control methods, and crash recovery techniques enforce ACID properties and assure transaction reliability in DBMS systems. Financial, reservation, and other data-critical systems must follow the ACID principles.
In terms of their distinct goals, features, and intended uses for data processing and analysis, OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing) differ from one another.
Online transaction processing (OLTP) systems are made to handle real-time transactional processing duties, such as capturing, processing, and managing routine operating transactions. In operational settings like order processing, inventory management, banking, or online retail, these systems are frequently employed. With a high level of concurrency, data integrity, and transactional consistency, the efficient execution of individual transactions is the main goal of OLTP systems.
Important Features of OLTP Systems:
1. Transaction-Oriented: OLTP systems are designed to be used for transactional tasks including adding, updating, and removing specific records from a database.
2. Real-Time Processing: Where reaction time is crucial, OLTP systems handle immediate, real-time transaction processing.
3. High Concurrency: OLTP systems are made to handle several transactions from various users at once.
4. Normalized Data Structure: To reduce data redundancy and preserve data integrity, OLTP databases often employ a normalized data structure.
5. Quick Data Retrieval: For certain transactional activities, OLTP systems prioritize quick retrieval of individual records.
Online analytical processing (OLAP) systems are created for complicated data analysis and reporting, allowing organizations to gather knowledge, carry out multidimensional analysis, and support decision-making procedures. Large volumes of historical and summary data, often taken from OLTP systems, data warehouses, or other data sources, are processed using OLAP systems. Business intelligence, data mining, trend research, and strategic planning all make use of these technologies.
Important Features of OLAP Systems:
1. Advanced analytical processing: OLAP systems give users the ability to conduct challenging computations, aggregates, and comparisons across numerous dimensions.
2. Multidimensional Analysis: OLAP systems can analyze data that is grouped into dimensions (such as time, geography, and product) and measurements (such as sales, profit).
3. Query Flexibility: OLAP systems give users the ability to explore data in greater depth, run ad hoc queries, and create unique reports.
4. Historical and Summarized Data: OLAP systems evaluate data over lengthy time frames, frequently using substantial amounts of historical and summarized data.
5. Support for decision-making: OLAP systems support decision-making by delivering insights, trends, and patterns via interactive visualizations and reporting capabilities.
In conclusion, OLTP systems place a heavy emphasis on data integrity and parallelism while concentrating on real-time transactional processing. On the other hand, OLAP systems are experts in complicated data analysis and offer multidimensional modeling, extensive analytical capabilities, and decision support. OLAP systems are designed for strategic analysis and business intelligence, whereas OLTP systems are focused on meeting urgent transactional demands. This allows firms to draw insights from historical and summary data in order to make informed decisions.
A particular class of stored program or procedure known as a database trigger is automatically carried out in response to particular occurrences of events or activities within a database. Data updates (insert, update, delete), data definition language (DDL) commands, or database events can all operate as triggers for a particular table or view.
In the database, triggers are frequently used to automate specific operations or calculations, enforce business rules, and preserve data integrity. The following are some essential ideas about database triggers:
1. Event-Driven Execution: Triggers are created to react to particular database events or activities. These can be database-level events like system startup or shutdown or data modifications like inserting, updating, or deleting records from a table. Triggers are carried out automatically when the stated event takes place.
2. Enforcing Business Rules: Within the database, triggers can be utilized to impose business rules and restrictions. To make sure a specific requirement is satisfied before permitting the insertion or updating of a record, for instance, a trigger might be made. By evaluating data against preset rules, this aids in maintaining data integrity and consistency.
3. Data Validation and Integrity: By examining the values being added, modified, or removed from a table, triggers can carry out data validation and guarantee data integrity. Beyond what can be accomplished with straightforward table constraints, they can enforce complicated integrity constraints, referential integrity, or custom rules. Data that doesn't comply with the requirements can be rejected or changed by triggers.
4. Auditing and Logging: Mechanisms for auditing and logging can be implemented using triggers. A trigger, for instance, can record details about modifications made to a certain table, such as the person who performed the modification, the timestamp, and the old and new values. For further examination or tracking, this data can be documented or placed in an audit table.
5. Automating activities or computations: Within the database, triggers can automate specific activities or computations. For instance, a trigger can carry out computations based on certain conditions, automatically update associated tables when records are added or altered, or send out notifications or alerts in response to specific events. Data management workflows can be streamlined and manual involvement diminished with the use of triggers.
6. Trigger Types: There are two types of triggers: those that are executed before triggers and those that are executed after triggers. Triggers that come before the triggering event are executed, allowing for data modification or validation checks. After triggers are used for auditing, logging, or post-processing operations that are executed after the triggering event takes place.
Database triggers are an effective tool for automating processes, enforcing business rules, and preserving data integrity in database management systems. Triggers can impair speed and increase database complexity, therefore it's crucial to utilize them wisely. To guarantee that triggers are used successfully and efficiently in the database environment, proper planning, design, and testing are crucial.
The conceptual data model known as the Entity-Relationship (ER) model is employed to portray the organization and connections of data in a database system. Entities, properties, and the connections between them are graphically represented.
An entity in the ER model represents a real-world thing, concept, or object, such as a person, location, or event. In the figure, each entity is represented by a rectangle, and it is further specified by its attributes, which are traits or qualities connected to the entity. Ovals are used to symbolize attributes inside the entity rectangle.
Relationships between entities describe their dependence and affiliations with one another. Relationships describe the nature of interactions between entities and show how they are related to one another. Depending on the cardinality and participation requirements of the entities involved, relationships can be one-to-one, one-to-many, or many-to-many.
Cardinality and participation requirements are represented by the ER model using a variety of notations. A line with an arrow, for instance, denotes a one-to-many relationship, in which one entity is connected to numerous entities of a different sort. These relationships are frequently expressed using the crow's foot notation, where the crow's foot symbol denotes the "many" side of the relationship.
The ER model's essential elements consist of:
1. Entities: These are representations of actual things, ideas, or objects. They have linked qualities that specify their characteristics and are represented as rectangles.
2. Attributes: These terms describe the traits or features of entities and are shown as ovals inside the rectangle of the entity. Detailed information about the entity is provided by attributes.
3. Relationships: Identify dependencies and associations between things. Relationships outline the nature of interactions between entities and how they are related to one another. Lines linking several entities serve as their representation.
4. Cardinality: Indicates how many occurrences of one entity can be linked to occurrences of another entity in a connection. Whether a relationship is one-to-one, one-to-many, or many-to-many is determined by this.
5. Participation: Indicates whether an entity must fully participate in a connection (total participation) or may choose to participate in part of it (partial participation). Partial participation allows for certain instances to not participate, whereas total participation requires all instances of each entity in the relationship to engage.
The ER model aids in identifying entities, their attributes, and the relationships among them by serving as a visual and understandable representation of the database structure. Before a database is actually implemented, conceptual modeling is frequently used in database design to comprehend and express the data's structure and the connections between entities. The conceptual model is translated into a physical database design using the ER model, which also acts as a foundation for developing the database schema.
A join is an action used in database management systems to merge data from two or more tables based on a common column. By combining rows from many tables that have a common value in a certain column, it enables the retrieval of relevant and related data.
In relational databases, join procedures are crucial for data analysis and querying. Complex associations can be created by joining tables, allowing for the retrieval of extensive and useful data.
The following are some essential connect concepts to comprehend:
1. Join types:
- Inner Join: Based on the entered join criteria, an inner join only displays the matched rows from both tables. Rows that meet the join requirement are combined.
- Left Join: A left join returns all of the rows from the left table (also known as the first table) and any matching rows from the right table (also known as the second table). The columns of the right table are filled with NULL values if there is no match in the right table.
- Right Join: A Right joins are the polar opposite of left joins. Both the matched rows from the left table and all of the rows from the right table are returned. The columns of the left table contain NULL values if there is no match in the left table.
- Full Outer Join: This join retrieves every record from both tables, including any that were mismatched. The columns of the other table contain NULL values if there is no match for a row in the first table.
- Cross Join: A cross join, also referred to as a Cartesian join, merges all the rows of two tables to create a Cartesian product.
2. Join Conditions:
- Equality Join: This sort of join condition is the most prevalent and involves joining columns with same values from both tables.
- Non-Equality Join: Joins may also be carried out based on comparison operators other than equality, such as greater than, less than, or others.
- Multiple Conditions: Multiple columns or expressions can be used in join conditions, allowing for more intricate matching rules.
3. Joining More Than One Table: Joins might include more than just one table. In these circumstances, links between numerous tables can be created by combining various join conditions and join types.
4. Table aliases can be used to distinguish between columns and prevent naming issues when combining tables with similar column names.
SQL queries frequently employ join procedures to aggregate data from various tables according to the associations established by main and foreign keys. Joins offer a mechanism to join and analyze related data as well as the ability to retrieve data that is dispersed across multiple tables. By utilizing the connections between tables in a relational database, they play a significant part in producing reports, providing useful insights, and assisting decision-making processes.

PHONE: +91 80889-75867











