Choose a Language

Experts to solve your doubts in Lectures & Assignments
Solve your everyday’s doubts by
By Team of Top tech developers of 10+ exp.



Solve your everyday’s doubts by
By Team of Top tech developers of 10+ exp.

Data structures are used in C to organise and store data in a logical and efficient manner. An array, stack, queue, linked list, tree, and other data structures are accessible in the C programming language. A programmer selects a suitable data structure and adapts it to their requirements.
In a wide number of businesses, data structures are critical. Companies all over the world are investing millions of dollars to fully integrate their data handling systems utilising efficient data structures rather than old methods. Whether you work for a startup or a large organisation, all companies require the use of Data Structures in 2024, so mastering and analysing the best Data Structures Interview Questions and Answers is vital.

Introduction to C Programming Language
The C programming language, a versatile, methodical, and commanding coding lexicon, emerged in the nascent 1970s. Conceived by Dennis Ritchie at the eminent Bell Telephone Laboratories, it catered to the Unix operating system's exigencies. In the annals of programming dialects, C has proliferated prodigiously, boasting compilers for virtually every extant computer architecture and operating framework.
The Origins of C Programming Language
The inception of the C programming language followed its precursor, the B programming language, which Ken Thompson devised in 1970 for Unix operating system's premier iteration. The primary impetus behind C's genesis was to facilitate the creation of a resourceful, portable operating system compatible with an assortment of hardware platforms. Owing to its unpretentiousness, efficacy, and adaptability, the C programming language swiftly garnered acclaim, becoming the preferred lexicon for system programming and the development of operating systems, compilers, and sundry software instruments.

Learn From Basic to Advanced DSA, Problem Solving, Scalable System Design (HLD + LLD),Design Patten etc

Video Course
Life Time Access

Course Fee : 4,000/-
Learn From Basic to Advanced Data Structures, Algorithms & Problem-Solving techniques
Video Course
Life Time Access
Course Fee : 3,000/-
We'll go through both basic and advanced data structures in C in depth in this article. We'll also go over in detail the many searching and sorting strategies that may be applied to data structures.
In computer jargon, a data structure is a method of storing and organising data in a computer's memory so that it may be used effectively later.
Data can be organised in a number of different ways.
A data structure is a logical or mathematical representation of how data is organised.
A data model's variety is defined by two factors:
To begin, it must be well-structured in order to accurately portray the data's true relationships with real-world objects.
Second, the structure should be basic enough that anyone can readily process the data as needed.
Data structures can be divided into two categories:
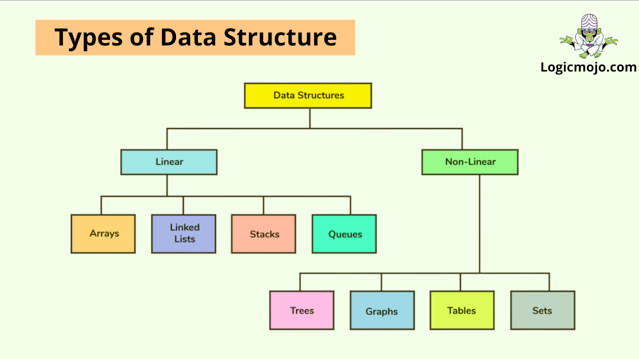
1. Linear data structures : The organisation of linear data structures is similar to that of computer memory. In a linear approach, linear data structures store elements one after the other. At any one time, just one element of the data can be explored. Consider a stack of books on a shelf. A book will be put between two other books, but not three; at any given time, a book will only have a relationship with two other books. In a similar fashion, linear data elements are stored. Arrays, Queues, Linked Lists, and Stacks are some common examples of linear data structures.
2. Non linear data structures :Data structures that are not linear are stored in a sequential order. In non linear data structures, data elements may have relationships with one or more elements at the same time. It is more harder to manipulate non linear data structures than linear data structures. Tree and graph are common examples of non linear data structures.
Data structures are important in almost every field you can think of. Algorithms are required in any data handling circumstance. Here are a few scenarios in which data structures are frequently used:
Artificial Intelligence
DBMS
Operating System
Numerical Analysis
Graphics
Compiler Design
Simulation etc.
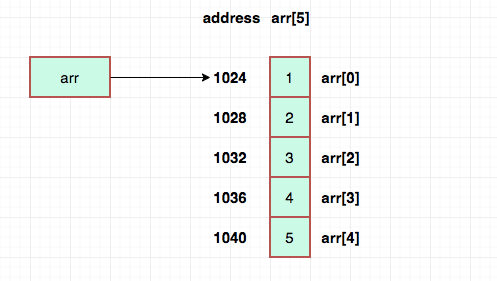
Arrays are groups of data elements of similar types stored in memory regions that are contiguous. It is the most basic data structure in which the index number of each data element can be used to get it at random.
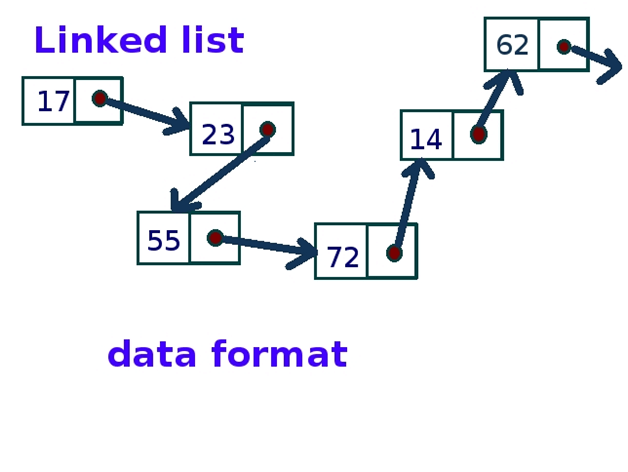
A Linked List is a collection of nodes, or data objects that are randomly stored. A pointer connects each node in a Linked List to its neighbouring node. In a node, there are two fields: Data Field and Link Field.
struct node { int data; struct node *next; }; struct node *head, *ptr; ptr = (struct node *)malloc(sizeof(struct node));
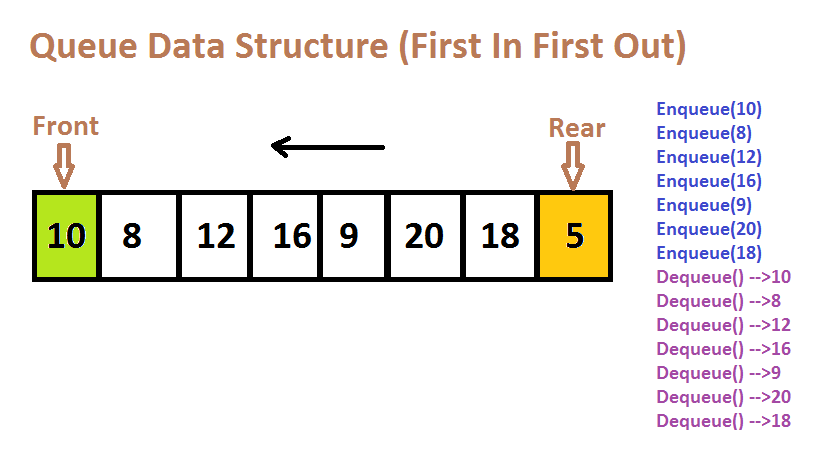
A queue is a collection of data organised according to the FIFO principle (First in, First Out).
It's some kind of linear data structure.
Only the elements at the front of a queue are removed, and only the elements at the back are added.
Consider a line of people forming in front of a movie theatre to purchase tickets.
People who want to skip to the front of the queue for tickets must wait in the back.
People leave the line only after collecting their tickets at the front.
The two operations that take place on a queue are enqueue (adding data elements) and dequeue (removing data elements) (removing data elements).
The front pointer is at the head of the line, while the rear pointer is at the tail end.
We pull components from the back of the queue and put them in front.
#include<stdio.h> #define SIZE 5 void enQueue(int); void deQueue(); void display(); int items[SIZE], front = -1, rear = -1; int main() { deQueue(); enQueue(1); enQueue(2); enQueue(3); enQueue(4); enQueue(5); enQueue(6); display(); deQueue(); display(); return 0; } void enQueue(int value) { if(rear == SIZE-1) printf("nQueue is Full!!"); else { if(front == -1) front = 0; rear++; items[rear] = value; printf("nInserted -> %d", value); } } void deQueue() { if(front == -1) printf("nQueue is Empty!!"); else { printf("nDeleted : %d", items[front]); front++; if(front > rear) front = rear = -1; } } void display(){ if(rear == -1) printf("nQueue is Empty!!!"); else { int i; printf("nQueue elements are:n"); for(i=front; i<=rear; i++) printf("%dt",items[i]); } }
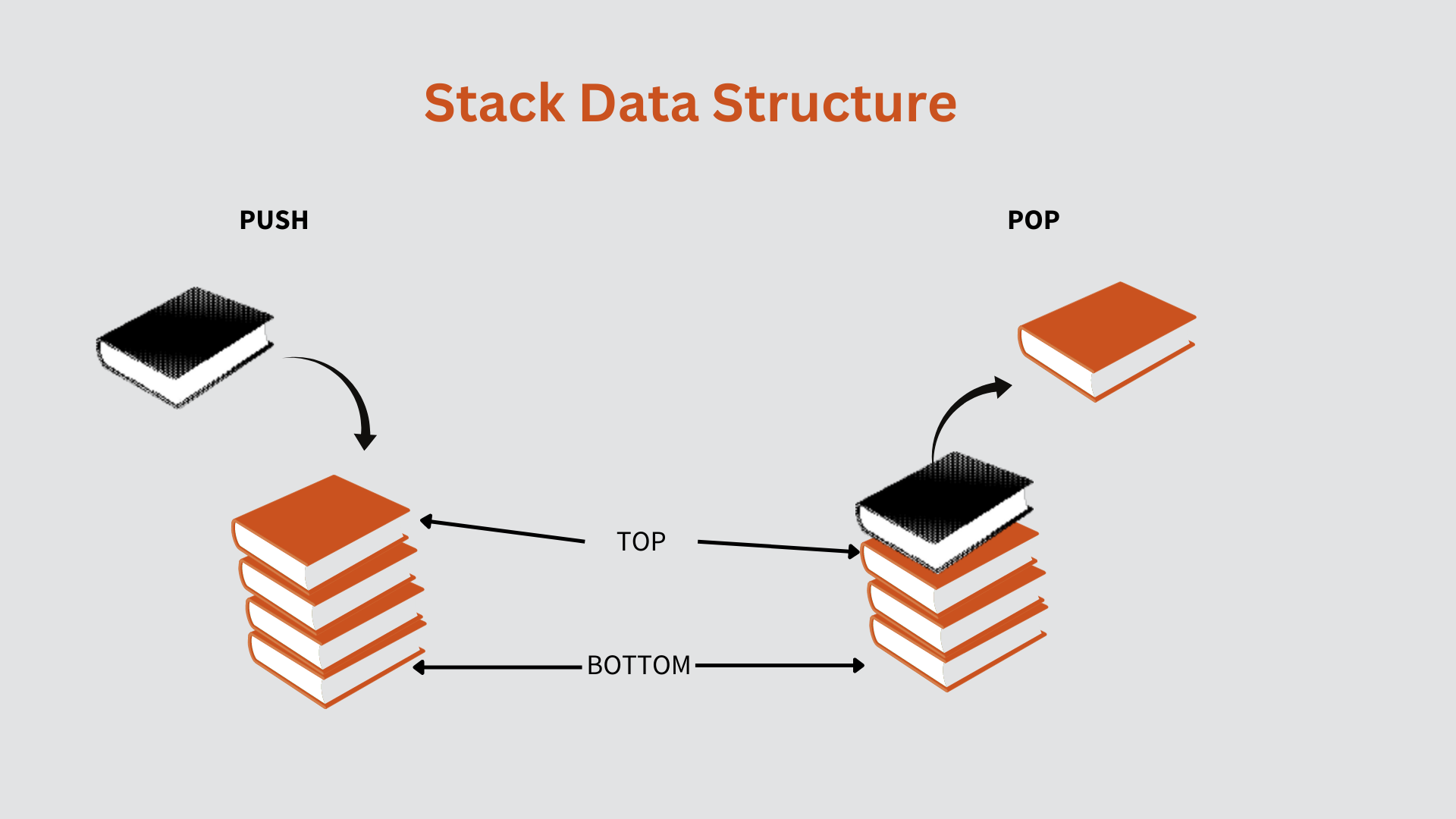
A linear data structure is referred to as a stack.
Stacks follows the strategy of "last in, first out."
A new item is added to the top of a stack.
Both insert and delete actions are performed from one end of the stack.
There are two different uses for stacks.
Use the push method to add components to the stack, and the pop function to remove parts from the stack.
Consider the following scenario: you have a cookie jar into which you can only add one cookie at a time.
The method of placing one cookie at a time into the jar is known as pushing.
Alternatively, you can erase one cookie at a time.
The process of deleting cookies from the topmost location is known as a pop function.
#include <limits.h> #include <stdio.h> #include <stdlib.h> struct Stack { int top; unsigned capacity; int* array; }; struct Stack* createStack(unsigned capacity) { struct Stack* stack = (struct Stack*)malloc(sizeof(struct Stack)); stack->capacity = capacity; stack->top = -1; stack->array = (int*)malloc(stack->capacity * sizeof(int)); return stack; } int isFull(struct Stack* stack) { return stack->top == stack->capacity - 1; } int isEmpty(struct Stack* stack) { return stack->top == -1; } void push(struct Stack* stack, int item) { if (isFull(stack)) return; stack->array[++stack->top] = item; printf("%d pushed to stackn", item); } int pop(struct Stack* stack) { if (isEmpty(stack)) return INT_MIN; return stack->array[stack->top--]; } int peek(struct Stack* stack) { if (isEmpty(stack)) return INT_MIN; return stack->array[stack->top]; } int main() { struct Stack* stack = createStack(100); push(stack, 11); push(stack, 12); push(stack, 33); printf("%d popped from stackn", pop(stack)); return 0; }
It's a type of linked list (double-ended LL) in which each node has two links, one to the next node in the sequence and the other to the previous node in the series. This allows traversal of the data elements in both directions.

Examples:
A music playlist with next and previous track navigation options.
RECENTLY VISITED PAGES IN THE BROWSER CACHÉ
Undo and redo functions in the browser, which let you to return to a previous page by reversing the node.
The fundamental difference between the two data structures is the memory space that is accessed. The phrase "storage structure" refers to the structure that houses the computer system's main memory. When interacting with auxiliary structures, we refer to them as file structures.
Some examples of queue applications are as follows:
Queues are commonly used to build queues for a single shared resource, such as a printer, disc, or CPU.
Queues are used for asynchronous data transfer in pipes, file IO, and sockets (when data is not transferred at the same pace between two processes).
Queues are used as buffers by most programmes, such as MP3 players and CD players.
In media players, queues are used to maintain track of the playlist and add and remove tracks.
Interrupts are handled by queues in operating systems. The following are some examples of queue applications:
The scanned input travels to the left or right of the root node, also known as the parent node, in a binary tree called a Binary Search Tree.
The value at the root node is smaller than all of the elements on the left.
All elements to the right have a value larger than the value of the root node.
The root's children are the values to the left and right of the root (parent).
Sub-trees are the collective term for their offspring.
The basic purpose and principle of such a data structure is to have a storage mechanism that enables efficient sorting, searching, traversal, insertion, and deletion.
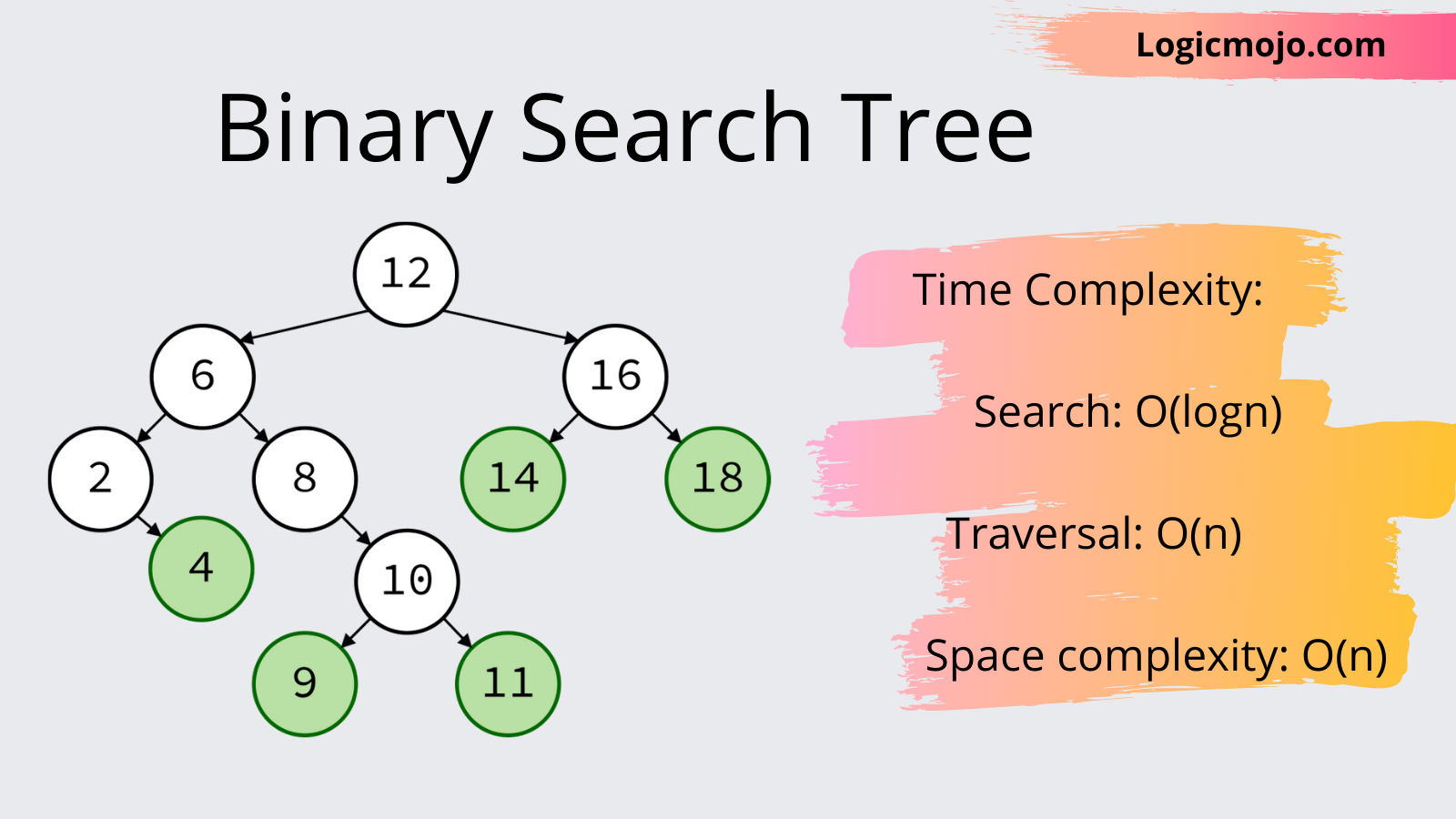
The Binary Search Tree in Action:
1.Each element that is to be added is sorted as soon as it is inserted, according to the Binary search tree.
2. Depending on whether the value to be inserted is less than or greater than root, the comparison starts at the root and moves to the left or right sub-trees.
3. As a result, any value entered is checked against the root value. The left child and its offspring receive any value less than or equal to the root, but the right child and its children receive any value greater than or equal to the root.
4. As a result, the values are automatically sorted as they are inserted into the tree.
Implementation in C
#include<stdio.h> #include<stdlib.h> struct node // Structure defined for each node { int value; struct node* left; struct node* right; }; struct node* createNode(int data){ //function which initializes a new node int nodeSize = sizeof(struct node); struct node* newNode = malloc(nodeSize); newNode->value = data; newNode->left = NULL; newNode->right = NULL; return newNode; } struct node* insertNode(struct node* current, int data) //inserts a node in BST { if (current == NULL) // if the current reaches NULL, data is to be inserted here return createNode(data); if (current->value < data) current->right = insertNode(current->right, data); else if (current->value > data) current->left = insertNode(current->left, data); return current; } void inOrderTraversal(struct node* current){ //recursive code to print in-order if(current == NULL) // reaches end of any leaf and can’t go any deeper in tree return; inOrderTraversal(current->left); printf("%d \n", current->value); inOrderTraversal(current->right); } int main(){ struct node *root; root = NULL; root = insertNode(root, 8); insertNode(root, 3); insertNode(root, 1); insertNode(root, 6); insertNode(root, 7); insertNode(root, 10); insertNode(root, 14); insertNode(root, 4); inOrderTraversal(root); return 0; }
#include<stdio.h> #include<stdlib.h> void beg_insert(int); struct node { int data; struct node *next; }; struct node *head; void main () { int choice,item; do { printf("\nEnter the item which you want to insert?\n"); scanf("%d",&item); beg_insert(item); printf("\nPress 0 to insert more ?\n"); scanf("%d",&choice); }while(choice == 0); } void beg_insert(int item) { struct node *ptr = (struct node *)malloc(sizeof(struct node)); struct node *temp; if(ptr == NULL) { printf("\nOVERFLOW"); } else { ptr -> data = item; if(head == NULL) { head = ptr; ptr -> next = head; } else { temp = head; while(temp->next != head) temp = temp->next; ptr->next = head; temp -> next = ptr; head = ptr; } printf("\nNode Inserted\n"); } }
🚀 Because items can only be placed at the front end, and because the value of front may be so high that all the space preceding it can never be filled, the array space used to store queue elements can never be reused to store queue elements.
🚀 Array Size: When creating a queue with an array, there may be times when we need to extend the queue to include more elements.
Because it's practically difficult to increase the array size when using an array to construct a queue, figuring out the right size is always a challenge.
OA postfix expression is made composed of operators and operands, with the operator arriving after the operands. In a postfix expression, the operator comes after the operands. Also, what is the proper postfix form? The right postfix phrase is A B + C *.
Merge sort is a data sorting algorithm that divides and conquers. It works by merging and sorting neighbouring data to create larger sorted lists, which are then merged recursively to create even larger sorted lists until only one remains.
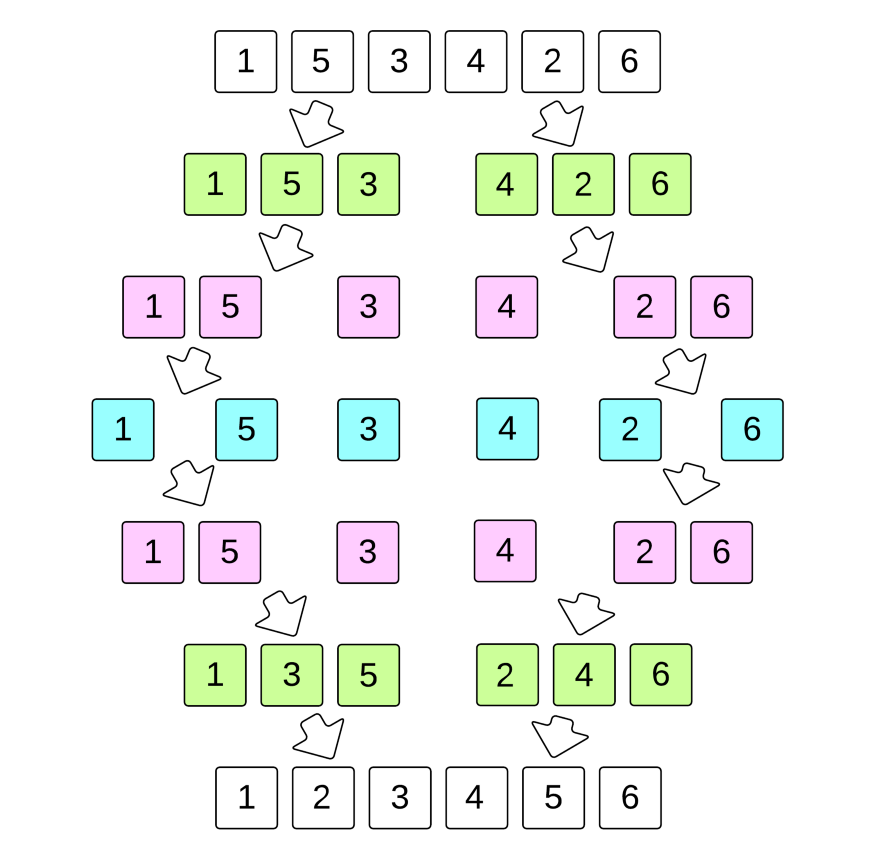
The smallest number from the list is repeatedly selected in ascending order and placed at the top of the selection sort.
This operation is repeated as you get closer to the end of the list or sorted subarray.
Scan through all of the items to find the tiniest one.
The first item in the position should be replaced.
Repeat the selection sort on the remaining N-1 items.
Every time we iterate forward I from 0 to N-1, we swap with the smallest element (always i).
Space complexity: worst O(1)
Implementation in C
#include <stdio.h> void swap(int *xp, int *yp) { int temp = *xp; *xp = *yp; *yp = temp; } void selectionSort(int arr[], int n) { int i, j, min_idx; // One by one move boundary of unsorted subarray for (i = 0; i < n-1; i++) { // Find the minimum element in unsorted array min_idx = i; for (j = i+1; j < n; j++) if (arr[j] < arr[min_idx]) min_idx = j; // Swap the found minimum element with the first element swap(&arr[min_idx], &arr[i]); } } /* Function to print an array */ void printArray(int arr[], int size) { int i; for (i=0; i < size; i++) printf("%d ", arr[i]); printf("\n"); } // Driver program to test above functions int main() { int arr[] = {64, 25, 12, 22, 11}; int n = sizeof(arr)/sizeof(arr[0]); selectionSort(arr, n); printf("Sorted array: \n"); printArray(arr, n); return 0; }
A bubble sort is a data structure sorting algorithm that may be used with arrays. It compares objects in close proximity and swaps their values if they are out of order.
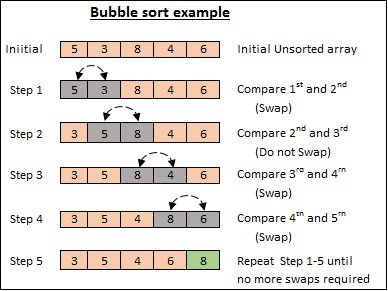
Implementation in C
#include <stdio.h> void swap(int* xp, int* yp) { int temp = *xp; *xp = *yp; *yp = temp; } // A function to implement bubble sort void bubbleSort(int arr[], int n) { int i, j; for (i = 0; i < n - 1; i++) // Last i elements are already in place for (j = 0; j < n - i - 1; j++) if (arr[j] > arr[j + 1]) swap(&arr[j], &arr[j + 1]); } /* Function to print an array */ void printArray(int arr[], int size) { int i; for (i = 0; i < size; i++) printf("%d ", arr[i]); printf("\n"); } // Driver program to test above functions int main() { int arr[] = { 64, 34, 25, 12, 22, 11, 90 }; int n = sizeof(arr) / sizeof(arr[0]); bubbleSort(arr, n); printf("Sorted array: \n"); printArray(arr, n); return 0; }
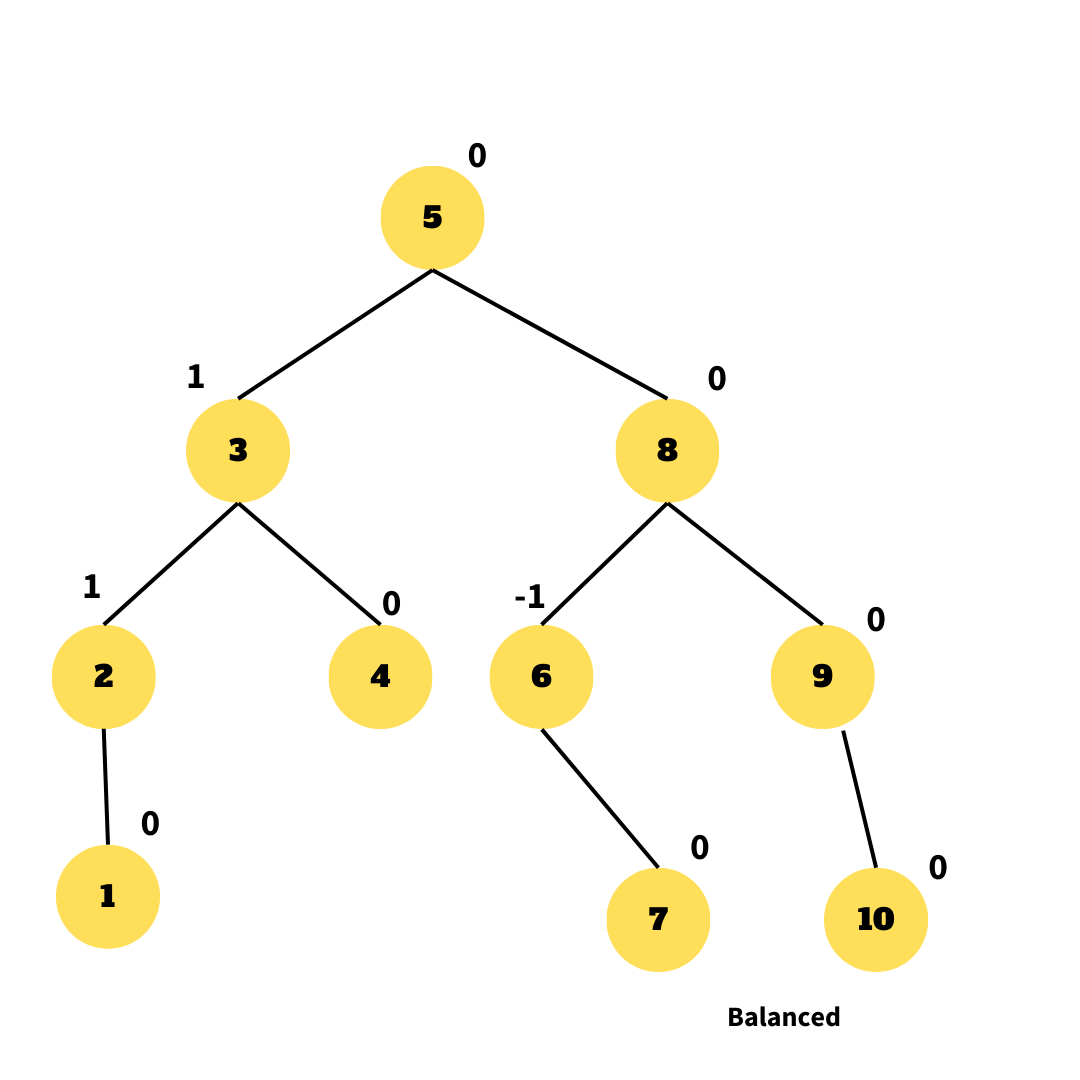
An AVL tree is a binary search tree that is always in a partially balanced state. The difference in the heights of the subtrees from the root is used to calculate the balance. This self-balancing tree is credited as being the first data structure of its kind.
A binary search tree that is always partially balanced is known as an AVL tree. The balance is calculated by subtracting the heights of the subtrees from the root. This self-balancing tree is considered as the first of its kind data structure.
A priority queue is an abstract data type that resembles a standard queue but contains entries of varying priority. Components with a higher priority are processed first, followed by those with a lower priority. A minimum of two queues are necessary in this circumstance, one for data and the other for storing priority.
Lexical analysis
Hierarchical data modeling
Arithmetic expression handling
Symbol table creation
Two data structures are crucial in the implementation of graphs. They are as follows:
Adjacency list: Used to represent linked data
Adjacency matrix: Used to represent sequential data.
The new item must be unique because duplicates are not allowed in a binary search tree.
Assuming that it is, we will check to see if the tree is empty.
If the root node is empty, the new item will be inserted there.
If the tree isn't empty, though, we'll use the key for the new item.
If the new item's key is less than the root item's key, it will be added to the left subtree.
If the new item's key is greater than the root item's key, the new item is placed in the correct subtree.
A graph G can be used to represent an ordered collection G(V, E), where V(G) represents the set of vertices and E(G) represents the set of edges connecting these vertices. A graph can be thought of as a cyclic tree in which the vertices (Nodes) keep any complicated relationship among themselves, rather than having parent-child relationships.
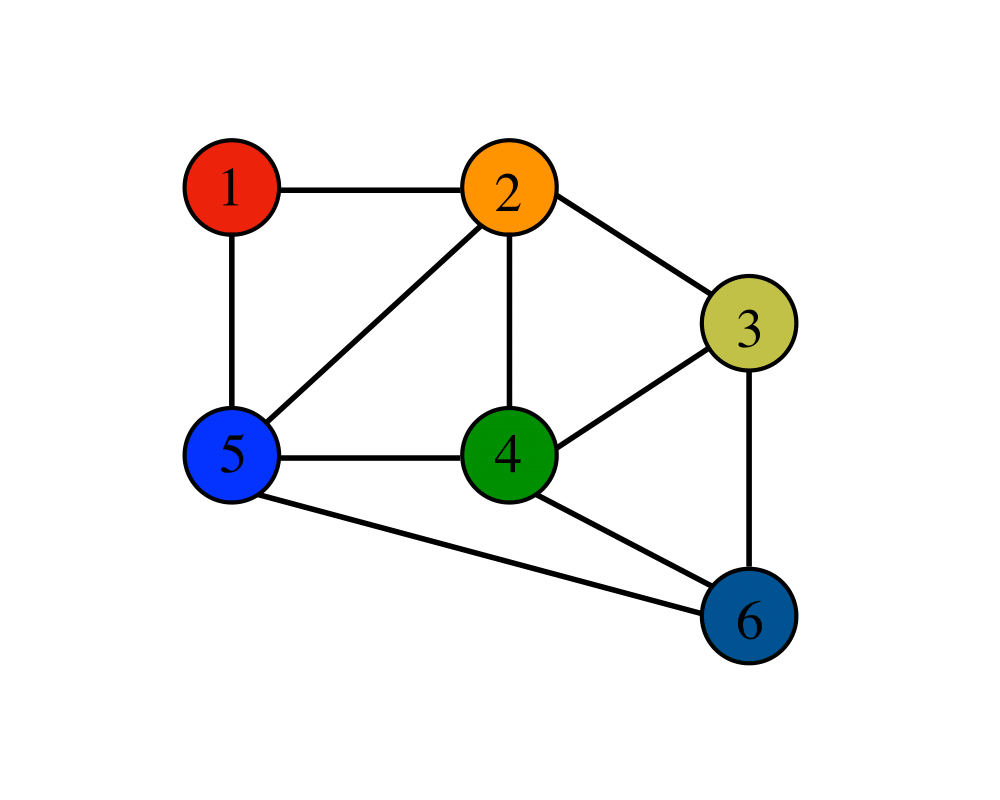
The graph can be used for a variety of purposes, including:
🚀
On maps, cities/states/regions are represented as vertices, whereas adjacency relationships are represented as edges.
🚀
In programme flow analysis, procedures or modules are viewed as vertices, and calls to these processes are represented as edges of the graph.
🚀
Stations are shown as vertices in transportation networks, whereas routes are drawn as edges of the graph.
🚀
Vertices are shown as points of connection in circuit networks, while component cables are drawn as graph edges.
int countHeight(struct node* t) { int l,r; if(!t) return 0; if((!(t->left)) && (!(t->right))) return 0; l=countHeight(t->left); r=countHeight(t->right); return (1+((l>r)?l:r)); }
The AVL tree controls the height of the binary search tree, preventing it from being skewed. The total time taken for all operations in a binary search tree of height h is O. (h). The BST can be extended to O(n) if it becomes skewed (i.e. worst case). By limiting the height to log n, the AVL tree imposes an upper limitation on each operation of O(log n), where n is the number of nodes.
A B tree of order m has all of the characteristics of a M way tree.
It also has the following characteristics.
🚀All leaf nodes must have the same level.
🚀At least two root nodes are required.
🚀Every node in a B-Tree has at least m/2 children, with the exception of the root and leaf nodes.
🚀Each node in a B-Tree can have up to m children.
void in-order(struct treenode *tree) { if(tree != NULL) { in-order(tree→ left); printf("%d",tree→ root); in-order(tree→ right); } }
int count (struct node* t) { if(t) { int l, r; l = count(t->left); r=count(t->right); return (1+l+r); } else { return 0; } }
This page has finally reached its conclusion. With the information on this page, you should be able to construct your own programmes with some research, and modest projects are actually encouraged for honing your programming skills. There's no way to cover everything you need to know to be a successful programmer in a single course. In truth, whether you're a seasoned professional developer or a complete beginner, programming is a never-ending learning process.
Good luck and happy learning!
Data organization and storage in a computer system or memory are referred to as data structures. It offers a methodical technique to organize data so that algorithms or processes may access, alter, and process it effectively. In many areas of computer science, data structures are essential for efficient data management, storage, and retrieval. A thorough overview of data structures is provided below:
1. Organization and Storage: Data structures specify how data is organized and formatted for storage in memory or on disk. They describe how various records or data components are arranged and connected to create a logical structure. The type of data, the operations that will be performed on the data, and the application's performance requirements all play a role in the decision of which data structure to use.
2. Access and Manipulation: Efficient access and manipulation of data items are made possible by data structures. They offer procedures or ways to add, remove, get back, search for, and change data elements. The effectiveness and speed of these procedures are impacted by the data structure selection. Effective data architectures optimize access patterns and reduce the amount of time and resources needed to process data.
3. Efficiency and Performance: The effectiveness and performance of the algorithms and operations carried out on the data are directly impacted by the choice of an appropriate data structure. In terms of space complexity (how much memory is needed to store the data) and time complexity (how the execution time grows with the size of the data), different data structures perform differently. Performance can be increased overall and processing times can be sped up by using efficient data structures.
4. Data Structure Types: There are many different types of data structures, each with unique properties and application scenarios. Data structures that are often utilized include:
- Arrays: A group of related elements stored together in a continuous block of memory.
- Linked Lists: A group of nodes where each node has a reference to the node after it and data.
- Stacks: An LIFO data structure where items are inserted and removed from the top end.
- Queues: A FIFO data structure where items are added at one end (the back) and withdrawn from the other end (the front).
- Trees: Hierarchical data structures like binary trees and B-trees that have nodes connected by edges.
- Graphs: A set of nodes (vertices) connected by edges that show the connections between different items.
- Hash Tables: Data structures that efficiently store and retrieve key-value pairs by using a hash function to map keys to values.
5. Application Areas: Data structures are employed in a number of application areas, including:
- Algorithms: The design and analysis of algorithms depend critically on data structures.
- Database Management: Data structures are essential to the organization and indexing of data in databases.
- Programming: To store and manipulate data effectively, programming languages and frameworks make heavy use of data structures.
- Compiler Design: To store and retrieve code efficiently during compilation, data structures are used.
- Networking: In network systems, data structures help with efficient packet routing, caching, and protocol implementations.
- Scientific Computing: Data structures enable the processing and archiving of enormous amounts of computing and scientific data.
The performance and resource usage of software applications must be optimized, which calls for the use of effective and well-designed data structures. The precise needs of the problem, the type of data, and the operations to be carried out all play a role in the selection of the best data structure. Developers can choose the best data structure for effective data storage and manipulation in their applications by being aware of the various data structures and their qualities.
Because they offer a method for effectively organizing and managing data within a C program, data structures are crucial to the language. Compared to higher-level languages, C is a low-level programming language with few built-in data structures. To accomplish effective data storage and manipulation, developers must manually define and build data structures in C. To see why data structures are so important in C programming, read on:
1. Efficient Data Storage: Data structures make it possible to store data components in memory in an effective manner. Although there are basic data types in C, such as integers and characters, they might not be adequate for managing complicated data structures. Developers can arrange data in a way that optimizes memory usage and enables effective access and manipulation by building custom data structures, such as arrays, linked lists, stacks, queues, trees, or graphs.
2. Better Data Organization: C programs frequently work with complicated data that needs to be structuredly organized. To ensure coherence and simplicity of management, data structures offer a way to logically group together similar data items. Data structures allow developers to organize related data components into groups, create relationships between them, and specify rules for data access and modification. This company makes program logic simpler and improves the readability and maintainability of code.
3. Effective Data Retrieval and Manipulation: Data structures make it possible for C programs to efficiently retrieve and manipulate data. In order to search, insert, delete, and update data items, various data structures provide various operations and methods. For instance, arrays offer quick random access to elements, linked lists enable efficient insertion and deletion and dynamic memory allocation, and trees simplify hierarchical search and sorting. Developers can obtain optimum efficiency and lower computing complexity by selecting the proper data structure based on the particular requirements of the software.
4. Algorithm Implementation: Since algorithms depend on effective data organization and access techniques, data structures and algorithms are closely related concepts. Numerous algorithms are created with a focus on particular data structures. Developers can efficiently construct and use a broad variety of algorithms by implementing data structures in C. For instance, arrays are frequently used to create sorting algorithms like Quicksort and Merge Sort, but graph algorithms like Dijkstra's algorithm make use of graph data structures.
5. Performance Optimization: C's effective data structures help to improve performance. Developers can cut down on the time and resources needed for data access, search, and manipulation by carefully choosing the best data structure for a particular task. Effective data structures reduce the amount of operations required to handle data, resulting in quicker execution and better program performance overall.
6. Customization and Control: The versatility and control of the C programming language are well known. Developers can adapt the structures to their particular requirements by creating custom data structures in C. They have total control over the data representation and operations because they can construct data structures with the desired characteristics, behavior, and functionality. This personalization improves the modularity, reuse, and adaptability of the code.
In conclusion, data structures are essential to C programming because they make it possible to store, organize, retrieve, and manipulate data effectively. They improve readability and maintainability of the code, improve program performance, and offer control and customization choices. C programmers may efficiently select and implement the most suitable data structure for their particular requirements by studying various data structures and their properties. This will ensure good data management in their programs.
A thorough explanation of a few popular data structure types is provided below:
1. Arrays: An array is a basic data structure that keeps objects of the same type in close proximity to one another in memory. Using indices, they give users direct access to elements. Arrays are useful for situations when the size is known in advance because their fixed size is set at the time of declaration. However, they are less adaptable when it comes to dynamic scaling or the addition or removal of pieces. They provide efficient random access.
2. Linked Lists: Linked lists are dynamic data structures made up of nodes, each of which has a reference to the node after it and a data element. Unlike arrays, linked lists support flexible element insertion and deletion as well as dynamic memory allocation. In contrast to arrays, accessing entries in a linked list necessitates starting at the beginning of the list, which could prolong access times.
3. Stacks: A stack is a Last-In-First-Out (LIFO) data structure in which items are added to and deleted from the top end, which is the same end both operations occur at. It operates under the tenet of "last in, first out." Managing function calls, dealing with recursive algorithms, and implementing undo/redo actions are all possible with stacks. Pushing an element to the top of a stack and deleting it are frequent operations on stacks.
4. Queues: A queue is a FIFO data structure in which items are inserted at one end (the back) and withdrawn from the other end (the front). It adheres to the tenet of "first in, first out. " Task management, process scheduling, and the use of breadth-first search techniques can all be done with queues. Enqueue, which adds an element to the back of a queue, and dequeue, which removes an element from the front, are frequent operations on queues.
5. Trees: Made up of nodes connected by edges, trees are a type of hierarchical data structure. At the top, they have a root node, then child nodes, and finally leaf nodes. For activities like organizing data in file systems, implementing search algorithms (like binary search trees), and creating decision trees, trees offer an effective approach to describe hierarchical relationships. Binary trees, AVL trees, and B-trees are a few types of trees.
6. Graphs: Graphs are non-linear data structures that are made up of vertices (also known as nodes) and edges. They are used to simulate networks, social networks, routing algorithms, and more because they express interactions between entities. Graphs can be either undirected (where edges have no direction) or directed (when edges have a specific direction). Graphs are frequently represented using adjacency matrices and adjacency lists.
There are many more specialized data structures, including hash tables, heaps, and priority queues, and these are only a few examples. The selection of a data structure is based on the particulars of the problem, such as the type of data involved, the operations to be carried out, and the desired level of time and space complexity. For effective data management and algorithm design, it is essential to comprehend the traits and trade-offs of various data structures.
Yes, in computer programming, an array is a basic data structure. It is utilized to store a fixed-length sequence of identical data type elements. An array's items are kept in contiguous memory regions for quick access and retrieval.
A more thorough explanation of arrays as a data structure is provided below:
1. Structure and Organization: An array is a set of components that are arranged in a particular hierarchy. An array can include items of any data type, including objects, characters, and integers. Since the items are kept in successive memory regions, direct access using an index is possible. The index, which starts at 0 for the first element in the array, indicates where an element is located inside the array.
2. Fixed Size: An array's fixed size is one of its key features. An array's size, which specifies the most elements it may carry, is given when the array is declared. This fixed size cannot be altered during runtime; it is chosen during array construction. The set size of an array is both a benefit and a drawback because it guarantees effective memory allocation but limits the array's ability to change size on the fly.
3. Random Access: Through their indices, arrays offer constant-time access to their elements. Simple arithmetic operations can be used to determine the location of an element given an index. The efficient retrieval and alteration of array elements is made possible by this random access characteristic. One of the main benefits of arrays is that they allow for easy access to individual elements.
4. Efficiency: Efficient storage and retrieval of elements are provided by arrays. The elements of an array can be accessed with an O(1) constant time complexity since they are stored in contiguous memory regions. This means that accessing an element can be completed in a single operation regardless of the size of the array. But relocating other items is necessary when adding or removing members from an array, which results in a temporal complexity of O(n), where n is the total number of elements.
5. Memory Management: Arrays need to be allocated contiguous memory, which means that each block of memory needed to hold an array element should be available. Large array memory allocation can occasionally be difficult, especially when the needed memory isn't accessible in contiguous blocks. Additionally, if the allocated size is greater than what is required, the constant size of arrays may cause memory inefficiencies.
6. Applications: Arrays are frequently used for a variety of tasks, such as: - Storing and processing data sets, such as lists of names, numbers, or locations.
- Implementing additional data structures, such as matrices, stacks, and queues.
- Displaying audio, video, or image data.
- Enabling effective sorting and searching algorithms.
The foundation for numerous other data structures and algorithms is the straightforward yet effective data structure known as an array. They are appropriate for situations when the size of the collection is known and fixed and they offer effective access to the elements. However, compared to other dynamic data structures like linked lists or dynamic arrays, arrays are less flexible due to their fixed size and memory management restrictions.
In the C programming language, data structures can be implemented in a variety of ways. The decision depends on the particular requirements of the application and the benefits and drawbacks of each solution. Various methods for implementing data structures in C are listed below:
1. Arrays: C comes with arrays as a default data structure. For the purpose of storing elements of the same type, they offer a contiguous block of memory. Implementing an array is simple since you can define an array variable and use indices to access its elements. When the size of the data structure is fixed during runtime and is known in advance, arrays are appropriate. They are not adaptable for dynamic resizing but do provide effective random access to elements.
2. Structs: C structs allow many data types to be combined into a single entity. You can design a unique data structure that contains several pieces of various types by defining a struct. Structures can represent intricate data structures and are adaptable. However, they lack built-in operations for typical data structure operations and need for explicit memory management.
3. Linked Lists: Structs and pointers can be used to implement linked lists in C. A data element and a pointer to the following node are both included in each node of the linked list. Linked lists are flexible and can expand or contract as required. In contrast to arrays, they provide quick insertion and deletion operations but involve traversal to get to individual components. When dynamic resizing or frequent insertions and deletions are necessary, linked lists are appropriate.
4. Stacks and Queues: Arrays or linked lists can be used to implement stacks and queues. For stack and queue operations on arrays, you can use a fixed-size array and remember the top or front indices. You can use a singly linked list for linked lists and keep references to the top or front node. While queues adhere to the First-In-First-Out (FIFO) principle, stacks adhere to the Last-In-First-Out (LIFO) philosophy. For organizing collections of components with certain ordering constraints, both are appropriate.
5. Trees: Structs and pointers can be used to implement trees in C. A data element and pointers to each node's child nodes are present in every node in the tree. There are numerous sorts of trees, each with its own specifications and operations, including binary trees, AVL trees, and B-trees. The memory management and traversal techniques for tree implementations are critical for searching, insertion, and deletion operations.
6. Hash Tables: Using structs or arrays, hash tables can be built in C. Keys are mapped to array indices in hash tables using a hash function. An ordered linked list of entries with the same hash value is stored in each array index (bucket). Storage and retrieval of key-value pairs are made efficient by hash tables. They need a carefully thought-out hash function and methods for resolving collisions, including chaining or open addressing.
These are some of the typical ways that data structures are implemented in C. In terms of memory utilization, performance, and adaptability, each approach has benefits and drawbacks. It's crucial to take the application's unique requirements into account when selecting the implementation that will best serve the data structure's requirements and the operations that will be carried out on it.
An algorithm is a step-by-step process or a series of instructions that defines how to complete a certain activity or solve a specific problem in the context of C programming. A problem-solving methodology that is methodical and well-defined is provided by an algorithm, enabling programmers to create accurate and effective solutions.
A thorough explanation of algorithms in C is provided below:
1. Problem Solving: From straightforward activities to intricate calculations, algorithms are utilized to handle a variety of problems. They offer a methodical approach for segmenting a task into more manageable chunks. Prior to constructing an algorithm to successfully address the problem, it is essential to understand the problem and its needs.
2. Step-by-Step Guidelines: An algorithm is a set of exact guidelines that must be followed in a certain order in order to complete a certain activity. The algorithm's steps each represent a logical action, such as a calculation, choice, or data manipulation. Typically, these directives are expressed in formal language or pseudocode.
3. Input and Output: Algorithms receive input—which might come from the user or other sources—and generate output, which is the answer to the problem. Data values, variables, and even other algorithms can be used as input. A result, a modified data structure, or any other desired outcome might be considered output.
4. Correctness: The accuracy of an algorithm is a basic need. Every acceptable input must result in the desired output for an algorithm to work, and any potential edge cases or extraordinary circumstances must be handled correctly. An algorithm's correctness must be ensured through thorough design, testing, and validation.
5. Efficiency and Complexity: The effectiveness and complexity of an algorithm are measured. Efficiency is the amount of time and memory needed to carry out the algorithm. Analyzing complexity entails evaluating performance traits, such as time complexity (the rate at which execution time grows with input size) and space complexity (the rate at which input size increases memory use). The goal of efficient algorithms is to reduce resource consumption and enhance performance.
6. Algorithmic Paradigms: There are numerous algorithmic paradigms that each offer a unique method of problem-solving. Some prevalent paradigms are:
- Greedy Algorithms: Find an overall optimal solution by making locally optimal decisions at each step.
- Divide and Conquer: Break an issue down into smaller subproblems, go through each one recursively, then combine the results.
- Dynamic programming: Split a problem into overlapping subproblems and reuse those subproblems' answers to solve the larger problem.
- Backtracking: Investigate all viable options by gradually assembling candidates and reversing poor decisions.
- Search and Sort: Methods for looking for particular values or putting elements in a particular order.
7. Libraries and Data Structures: To facilitate the construction of algorithms, C offers a wide range of libraries and data structures. These libraries provide predefined data structures and functions that make it easier to do frequent tasks like sorting, searching, and mathematical calculations. The standard C library (stdlib.h, math.h) and other libraries like string.h and time.h are some examples.
Algorithms are essential to computer programming because they make it possible to develop trustworthy and effective software solutions. Algorithms must be written clearly and logically in order to solve problems efficiently and maintain software quality. Programmers may create the best solutions and enhance their capacity to address complicated issues in a methodical and logical way by grasping the fundamentals of algorithm design.
A structure is a user-defined data type in C programming that enables you to combine related data pieces into a single entity. Multiple advantages and benefits of structures help C programs be more effective, organized, and flexible. Here is a thorough justification of how utilizing structures in C is advantageous:
1. Organizing Related Data: Structures let you group and logically combine several related data pieces into a single entity. An entity or notion with several qualities can be represented by a structure. You could construct a structure containing properties like name, age, and grade if you were working with student records, for instance. Structures help organize the code and make the program easier to read and maintain by collecting similar data in one place.
2. Modularity and Reusability: By encapsulating data and associated actions within a single structure definition, structures encourage modularity and code reuse. Once established, a structure can be applied to numerous modules and functions, minimizing the need for duplicate code. As a result, it is easier to maintain the code and there are fewer chances of mistakes or inconsistencies while handling linked data.
3. Data Abstraction: By obscuring the core mechanics of the structure implementation, structures offer a type of data abstraction. Only the characteristics and their types are specified in the structure specification, letting you to work with the data without worrying about the implementation specifics. This abstraction makes working with complex data easier and streamlines software development.
4. Passing complicated Data to Functions: You can pass complicated data structures to functions as arguments by using structures. By passing a structure, you may easily combine several related parameters into a single parameter, improving code readability and cutting down on the number of function arguments. When working with vast and complicated data entities, this is especially helpful.
5. Effective Memory Management: C's structures make it possible to manage memory effectively. A contiguous block of memory is allocated for a structure's memory needs, allowing for quick access to structure members. The dot operator (.) can be used to gain direct access to certain structural members in this way. Structures optimize memory use and reduce memory fragmentation by combining similar data.
6. Flexibility and Extensibility: Structures are extensible and flexible, allowing them to adapt to shifting program needs. A structure's properties can be readily added or changed without having an impact on other code segments that make use of the structure. Structures are ideally suited for dynamic projects where data requirements may vary over time because of their flexibility.
7. Compatibility with I/O Operations: C structures can read and write structured data to and from files and other sources thanks to the language's support for input/output (I/O) operations. The processing of files and data persistence are made simpler by the ability to read or write a whole structure at once.
8. User-Defined Data Types: In C, you can define your own data types using structures. You can develop sophisticated data entities that match the issue domain by defining custom structures, which will increase the readability and clarity of your code. User-defined data types offer more expressiveness and improve code abstraction.
Overall, C structures have several advantages, such as improved data organization and encapsulation, code reuse, modular design, effective memory usage, and more flexibility. You may develop clearer, easier to maintain code and efficiently manage complex data entities in your C programs by utilizing structures.
There are various methods for gaining access to the information held within data structures when dealing with them. The exact data structure and the needs of the program determine which access mechanism should be used. Here are a few typical methods for getting at data in a data structure:
1. Direct Access: Direct access is a technique for gaining access to data by looking up its position in memory directly. This technique is frequently applied to data structures like arrays, where the items are kept in close proximity to one another in memory. By employing the index or address, direct access enables constant-time access to elements. For instance, array[i] allows you to directly access the element at index i in an array. When the place of the data is known, direct access offers effective random access to elements.
2. Sequential Access: In a predetermined order, sequential access entails gaining access to data items one at a time. Linked lists and stacks are two examples of data structures that frequently use this strategy. Starting at the beginning of the data structure and working your way through each element until you reach the one you want, you can access each one. Sequential access is appropriate for processing elements in a particular order or repeatedly going through a set of data.
3. Pointer-Based Access: With pointer-based access, you can move around the data structure and access certain elements by utilizing pointers. This approach is frequently used in data structures where items are connected by pointers, such as linked lists, trees, and graphs. By following the references, pointers make it possible to traverse and manipulate data structure pieces quickly. When it is necessary to traverse or edit data elements non-sequentially, pointer-based access is appropriate.
4. Key-Based Access: Hash tables and binary search trees are two examples of data structures that frequently use key-based access. Key-based access relies on distinct keys connected to each element rather than indices or addresses. Without having to go through the full structure, you may quickly access or change the correct data element by using a key. For searching, insertion, deletion, and update operations based on specified criteria, key-based access is especially helpful.
5. Iterator-Based Access: Iterators are used to navigate and access data elements in iterator-based access. Iterators offer an abstraction layer that conceals the precise implementation details of the underlying data structure. You can successively access elements and perform operations on them using an iterator without being aware of the internal representation of the structure. Many different data structures use iterator-based access, which offers a flexible and general technique to access data components.
The properties of the data structure, the operations to be carried out, and the program's efficiency requirements are some examples of the elements that influence the choice of access method. Each access technique has advantages and disadvantages of its own. For instance, sequential access permits easy iteration but may not be appropriate for rapid element retrieval, whereas direct access offers efficient random access but necessitates a fixed-size structure. For particular cases, pointer-based access and key-based access offer greater flexibility and efficiency.
Designing and putting into practice effective algorithms and operations on data structures requires an understanding of the various access mechanisms and the implications they have. The right access mechanism must be chosen in order to best meet the program's requirements and carry out the needed operations on the data structure.
Many different fields and applications employ data structures to efficiently organize, store, and manipulate data. Following are some applications for data structures:
1. Programming and software development: The basis of programming and software development is data structures. For managing and organizing data within applications, they are crucial. To efficiently store and process data, a variety of data structures including arrays, linked lists, stacks, queues, trees, and graphs are frequently utilized. Data structures are used by programmers to construct algorithms, handle data input/output, maintain program state, and build effective data storage systems.
2. Database Management Systems: In database management systems (DBMS), data structures are essential. For effective data retrieval and storage, DBMS rely on data structures including indexes, B-trees, hash tables, and different indexing methods. These data structures provide optimum efficiency and scalability by enabling efficient searching, sorting, and updating of data within databases.
3. Networking and telecommunications: To manage and process network-related information, networking and telecommunications systems use data structures. For instance, to effectively route and manage network traffic, routers and switches use data structures like routing tables, priority queues, and graphs. Data structures assist protocols like TCP/IP and OSI, make networks run more efficiently, and assure dependable data delivery.
4. Compiler Design: Data structures are essential to the design of compilers. To evaluate and translate source code into executable programs, compilers use data structures including symbol tables, abstract syntax trees, and intermediate code representations. These data structures help with the compilation process' parsing, semantic analysis, optimization, and code generation stages.
5. Artificial Intelligence and Machine Learning: The algorithms used in artificial intelligence (AI) and machine learning (ML) depend heavily on data structures. To efficiently store and analyze data, AI/ML models frequently rely on data structures including matrices, graphs, decision trees, and hash tables. Data structures make it possible to represent and manipulate big datasets, speed up classification and searching, and support advanced data structures like neural networks.
6. Geographic Information Systems (GIS): GIS applications use data structures to store, organize, and analyze geographical data. Map rendering, route planning, and geographical analysis are all made possible by the efficient storing and retrieval of geospatial data made possible by data structures like spatial indices, quadtrees, and KD-trees.
7. Operating Systems: Operating systems use data structures to handle file systems, manage system resources, and schedule tasks. To schedule processes, handle system interruptions, manage memory, and track file system metadata, data structures including queues, stacks, and linked lists are employed. These frameworks make it possible to manage processes, allocate resources effectively, and make the system responsive.
8. Computational biology and bioinformatics: To evaluate huge biological datasets, computational biology and bioinformatics use data structures. DNA sequences, protein structures, and biological networks are stored and processed using data structures such suffix trees, sequence alignment matrices, and graphs. The development of phylogenetic trees and the analysis of gene expression are supported by these structures.
These are only a few of the many fields in which data structures are applied. Data structures are an essential component of many applications and systems because effective data management and manipulation are essential in many industries. To achieve the best efficiency and functionality, the right data structure must be chosen depending on the particular requirements of a certain area or challenge.
A data structure is a means to arrange and store data to make it easier to access, manipulate, and manage it effectively. Let's examine a real-world example to better grasp data structures:
Consider a library, a well-known environment where data structures are widely used:
1. Arrays: as a library, the list of books on the shelves can be stored as an array. An element of the array can be used to represent each book. An array makes it simple to discover a book via its index, enabling instant access to particular books. Arrays are appropriate for situations when the position of the data items is known because they offer efficient random access.
2. Linked Lists: Linked lists can be used to display a patron's prior borrowing activity. A linked list node can be used to hold each user's borrowing record, which includes details like the borrower's name, the title of the book, and the due date. Without the necessity for contiguous memory, linked lists provide flexibility in dynamically adding or removing borrowing records. Because of this, linked lists can be used in scenarios where elements need to be added or removed often.
3. Hash Tables: A library's book collection can be indexed or cataloged using hash tables. Each book may have a distinct key that corresponds to a place in the hash table, such as the book's ISBN or title. As a result, books may be found and retrieved quickly using their keys. When quick access to particular elements is needed, hash tables can be especially helpful.
4. Trees: Trees can be used to depict the library's hierarchical categorization of its books. Books can be arranged using a tree structure into categories like fiction, non-fiction, or genre-specific sections. Each category is represented by a node in the tree, and its children are either subcategories or specific books. Based on their categorization, trees offer an effective way to search for and browse through books.
5. Queues: To manage the waiting list for popular books, queues can be used. Users' information can be inserted into a queue as they ask for a book that isn't available right now. The person in front of them in line gets informed when the book is made available. The "first-in, first-out" rule is observed in lines, guaranteeing impartial book distribution.
These examples show how various data structures might be used in a practical setting, such as a library. Fast access, manipulation, and retrieval of data are made possible by data structures, which efficiently organize, store, and manage information. We can optimize the administration of data and improve the performance of various activities by selecting the suitable data structure based on the particular requirements of a situation.
Several frequent issues that can occur when working with data structures might have an impact on the program's functionality, dependability, and performance. To prevent or effectively handle these issues, it's critical to be aware of them. Here are a few typical issues with data structures:
1. Memory Overflows and Underflows: Memory overflow happens when the allocated memory for the data structure is exhausted, resulting in erratic behavior or crashes. For instance, an array may overflow if not given enough room to accommodate new elements. Memory underflow, on the other hand, happens when the data structure is accessed outside of the allotted memory range, leading to erroneous or undefinable behavior.
2. Improper Data Representation or Structure: Improper data structure implementation or inaccurate data representation might produce inaccurate results or program failures. For instance, traversal or insertion operations may result in unexpected outcomes if a linked list is improperly linked. To ensure accurate representation and proper operation, it is crucial to properly design and implement data structures.
3. Poor Performance: If data structures are not selected or applied properly, they may display poor performance. Slow execution speeds, excessive memory usage, or inefficient resource utilization might be caused by inefficient algorithms, poor data structure selection, or a lack of optimization. It is essential to assess the program's requirements and select data structures that provide effective operations for the tasks at hand.
4. Data Inconsistency or Corruption: Data structures may experience problems with data consistency or corruption in concurrent or multi-threaded contexts. Without adequate synchronization, it is possible for race situations or data corruption to occur when many threads or processes access and modify shared data structures at the same time. Data consistency and integrity are maintained by implementing suitable synchronization techniques, such as locks or atomic operations.
5. Data Leakage or Loss: Data structures may have problems with data leakage or loss. When data is mistakenly overwritten, lost, or improperly handled, data loss can happen. When memory allotted to data structures is improperly released, data leakage can occur, resulting in memory leaks and decreased system performance. To avoid data loss or leakage, proper memory management and error handling are essential.
6. Poor Error Handling: Data structures must be resilient and handle errors well. If there is insufficient error handling, unusual circumstances like out-of-bounds accesses or invalid inputs might cause program crashes, inaccurate results, or unexpected behavior. For the application to be stable and reliable, proper input validation, error checking, and appropriate exception handling are necessary.
Data structures may have scalability issues as the volume or complexity of the data increases dramatically. Some data structures may become ineffective or unusable for large-scale applications even when they work well for small datasets. Increased memory utilization, protracted processing times, or decreased performance are all signs of scalability problems. For managing large-scale applications, selecting proper data structures and algorithms that scale effectively with rising data sizes is essential.
It is crucial to properly design, develop, and test data structures while taking into account the unique requirements and limitations of the application in order to prevent these issues. These typical data structure issues can be reduced or avoided by using effective algorithms, appropriate memory management strategies, error handling systems, and synchronization approaches.
Programmers use the recursion technique to solve problems by breaking them down into smaller, related subproblems. Recursion in the context of data structures refers to the use of a recursive function to iteratively traverse or modify a data structure. When dealing with recursive data structures or issues that have a recursive nature, recursive algorithms are frequently used.
Recursion in data structures is described in depth here:
1. Recursive Functions: Recursive functions repeat their execution with a smaller or simpler input by including a call to themselves in the function body. The base case of a recursive function serves as the termination condition, while the recursive case involves the function calling itself with updated input. The base case guarantees that the recursion will ultimately come to an end and avoids an endless cycle.
2. Recursive Data Structures: Recursive data structures are data structures with self-referential elements that enable the definition of the structure in terms of smaller instances of the same structure. Linked lists, trees, and graphs are a few examples of recursive data structures. Each node in a linked list has a reference to the one after it, creating a recursive chain. In a similar way, nodes in trees and graphs can relate to other nodes in the same structure.
3. Recursive Traversal: Recursive traversal entails utilizing recursion to iteratively explore each element or node in a data structure. For instance, while traversing a binary tree recursively, the traversal function first visits the current node before iteratively explores the left and right subtrees. Up till all nodes have been visited, this process is repeated. Depth-first search (DFS) is a method that is frequently used to implement recursive traversal.
4. Recursive Algorithms: Recursive algorithms are employed to address issues that can be broken down into more manageable issues of a similar nature. In addition to directly resolving the base case, the recursive approach also recursively resolves the other subproblems. The recursive Fibonacci sequence algorithm, for instance, calculates each number by adding the two before it, arriving at the base instances of 0 and 1.
5. Recursion's Benefits and Drawbacks: Recursion has a number of benefits, including the ability to quickly and elegantly resolve issues that have recursive qualities. It enables the organic expression of issues that can be broken down into smaller examples. Recursion can make some algorithms easier to implement, especially when using recursive data structures. Recursion may be advantageous, but there may be downsides, such as greater memory usage and the risk for stack overflow if not handled appropriately.
6. Tail Recursion Optimization: In tail recursion, the recursive call is the very last action carried out within a function. Some programming languages offer tail recursion optimization, enabling the compiler or interpreter to reduce memory usage and stack overflow by optimizing tail-recursive calls.
Working with recursive data structures and problem-solving using recursion can be quite effective. By utilizing the self-referential characteristics of data structures, it provides clear and beautiful solutions. But it's crucial to take into account the potential downsides and restrictions of recursion, such as stack overflow and higher memory utilization, and to make sure that base cases are adequately described to assure termination.


PHONE: +91 80889-75867





