Less complicated and low-cost algorithms that work on structured data are used to sort through an unlimited selection of mobile phones based on price or to search for a certain book among millions of volumes on Flipkart.
Because in 2024 data structures in java are crucial to every programming language, and choosing the proper data structure has a substantial impact on both the performance and usefulness of Java programmes, mastering the many data structures available in Java is worthwhile.
This article will walk you through all concepts of data structures in java in 2024, including examples and terminology, as well as how to implement and use them in Java.
Popular Live Courses
• For Freshers Candidates LIVE Course
Advanced Course of Data Structures, Algorithms & Problem Solving
Learn From Basic to Advanced Data Structures, Algorithms &
Problem-Solving techniques in Java
Curriculum
1:1 Mentorship
Duration
4 Months Classes
Mode
LIVE Classes Weekend
ADDITIONAL CURRICULUM
Projects included
Professional Projects to learn with real work experience
A data structure is a collection of data with well-defined operations, behaviour, or features.
A data structure in Java language is a special manner of storing or organising data in java in computer memory so that we may make good use of it.
Data Structures are used extensively in practically all areas of computer science, including computer graphics, operating systems, artificial intelligence, compiler design, and many more.
2. What is the need for Data Structures in Java?
As the amount of data expands, applications get more complicated, and the following issues may arise:
Processing Speed: As the amount of data grows, high-speed processing is necessary to handle it. However, the processor may be unable to handle such a large amount of data.
Data retrieval: Take, for example, a 200-item inventory. Every time your application needs to look for a specific item, it must go through 200 items.As a result, the search process is slowed.
At the same time, multiple requests are made: If millions of users are seeking the data on a web server at the same time, there is a risk of server failure.
We employ data structures to solve the difficulties listed above.
The data structure stores and organises the information in such a way that the relevant information may be found quickly.
3. What are the Advantages of Java Data Structures
Data Structures are used to improve an application's efficiency and performance by organising data in such a way that it takes up less space while processing at a faster rate.
Data reusability is provided by data structures, which means that once a data structure is implemented, it can be used many times in different places.
The implementation of these data structures can be compiled into libraries, which clients can use in a variety of ways.
Abstraction: To specify a data structure in Java, the ADT (Abstract Data Types) is utilised.
The ADT adds a layer of abstraction to the equation.The client software simply utilises the data structure through the interface and is unaware of the implementation details.
4. What are the Types of Data Structure in Java?
The following are some examples of common data structures in Java:
Arrays
Linked Lists
Stack
Queue
Graph
Set
Tree
Hash
Heap
5. Data Structure Classification in Java
Linear Data Structures: All of the elements in a linear data structure are ordered in a linear or sequential order.
A single level data structure is the linear data structure.
Non-Linear Data Structures: Unlike linear data structures, non-linear data structures do not arrange data in a sequential order.
Multilevel data structures are non-linear data structures.
Further classification of types of Data Structures
There are two types of Data Structures:-
1. Primitive Data Structures
2. Non-primitive Data Structures
Data Structures can be classified as:-
Static Data Structures are data structures that have their size stated and fixed at compile time and can't be modified later. Example – Arrays
Dynamic data structures are data structures whose size is not specified at compile time and can be determined at runtime based on requirements. Example – Binary Search Tree
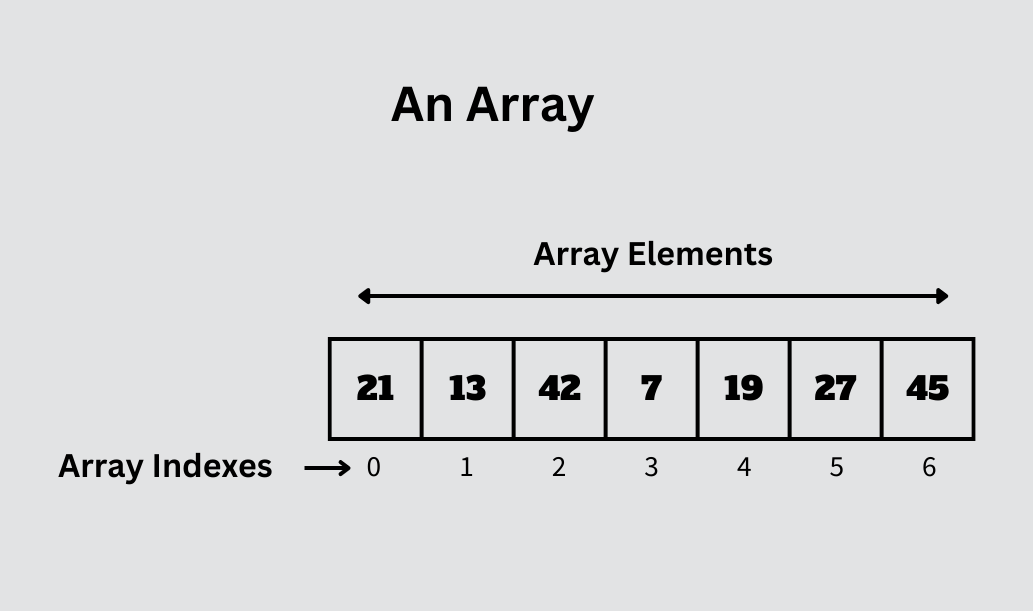
6. What are Arrays?
The simplest data structure is an array, which is a collection of objects of the same kind that are linked by a common name.
Arrays are collections of memory regions that are connected in some way.
The array's initial address belongs to the array's first element, and its last address belongs to the array's last element. Syntax in Java: dataType var[]; (or) dataType[] arr;
A few notes on arrays:
Data elements in arrays can be of simple and similar kinds, such as int or float, or user-defined datatypes, such as structures and objects.
The base type of an array is the most common data type for array elements.
In Java, arrays are considered objects.
In an array, the variable indexing starts at 0.
Before we can utilise an array to hold data, we must first define it.
In Java, array storage takes the form of dynamic allocation in the heap.
The member 'length' can be used to determine the length of an array.
An array's size must be an int value.
There are three types of arrays:
Single Dimensional Arrays
Two-dimensional Arrays
Multi-dimensional arrays
The below diagram is the representation of single dimensional array
Advantages Of Array
Arrays use one term to represent a collection of similar data components.
Array items can be retrieved at random using the index number.
Arrays allocate memory in shared memory regions to all of its elements. As a result, there is no chance of additional memory being allocated. This prevents memory overflow and array shortages.
Arrays can be used to implement other data structures such as linked lists, stacks, queues, trees, and graphs.
Disadvantages Of Array
The amount of elements that will be stored in an array should always be known ahead of time.
The array's size cannot be changed once it is declared. The amount of memory available cannot be increased or lowered. As a result, array is a static structure.
Allocating more memory than several items results in memory waste. A problem arises when there is insufficient memory allocation.
Insertion and deletion in an array are tough due to the items being stored in consecutive memory areas and the shifting operation being expensive.
7. What are the Time complexities for array operations?
For Accessing an elements: O(1)
For Searching an element:
Using Sequential Search: O(n)
Using Binary Search [If Array is sorted]:O(log n)
For Inserting an element: O(n)
For Deleting any element: O(n)
8. What are Linked List in Java?
Another essential form of data structure in Java is Linked Lists.
A Linked List is a collection of similar sorts of data pieces, called nodes, that are connected by pointers to the next nodes in the chain.
Linked lists are required:
Linked lists solve the disadvantages of arrays because there is no need to specify the amount of elements before using them.
As a result, memory may be allocated and dealt with as needed during processing, making insertions and deletions considerably easier and simpler. Syntax : LinkedList < dataType > var = new LinkedList < dataType > (); Linked lists come in a variety of types :
Singly Linked List :
A singly-linked list is a linked list that holds data as well as the following node's reference or a null value.
Singly-linked lists are also referred to as one-way lists since each node contains a single reference referring to the next node in the sequence.
There is a START pointer that stores the linked list's very first address.
The NULL value is stored in the next pointer of the last or end node, which points to the last node of the list and does not point to any other node.
Doubly Linked List :
It is similar to a singly-linked list except that it has two pointers, one pointing to the previous node in the sequence and one pointing to the next node in the sequence.
As a result, a doubly-linked list allows us to traverse the list in both ways.
Circular Linked List :
All of the nodes in the Circular Linked List align to form a circle. There is no NULL node at the end of this linked list. Any node can be designated as the initial node. Circular linked lists can be used to create a circular queue.
Advantages Of Linked-list
Dynamic in size
No wastage as capacity and size is always equal
Easy insertion and deletion as 1 link manipulation is required
Efficient memory allocation
Disadvantages Of Linked-list
If head Node is lost, the linked list is lost.
No random access is possible.
9. Time complexities for linked-list operations?
For Traversing elements: O(n)
For Searching an element: O(n)
For Insertion: O(1)
For Deletion: O(1)
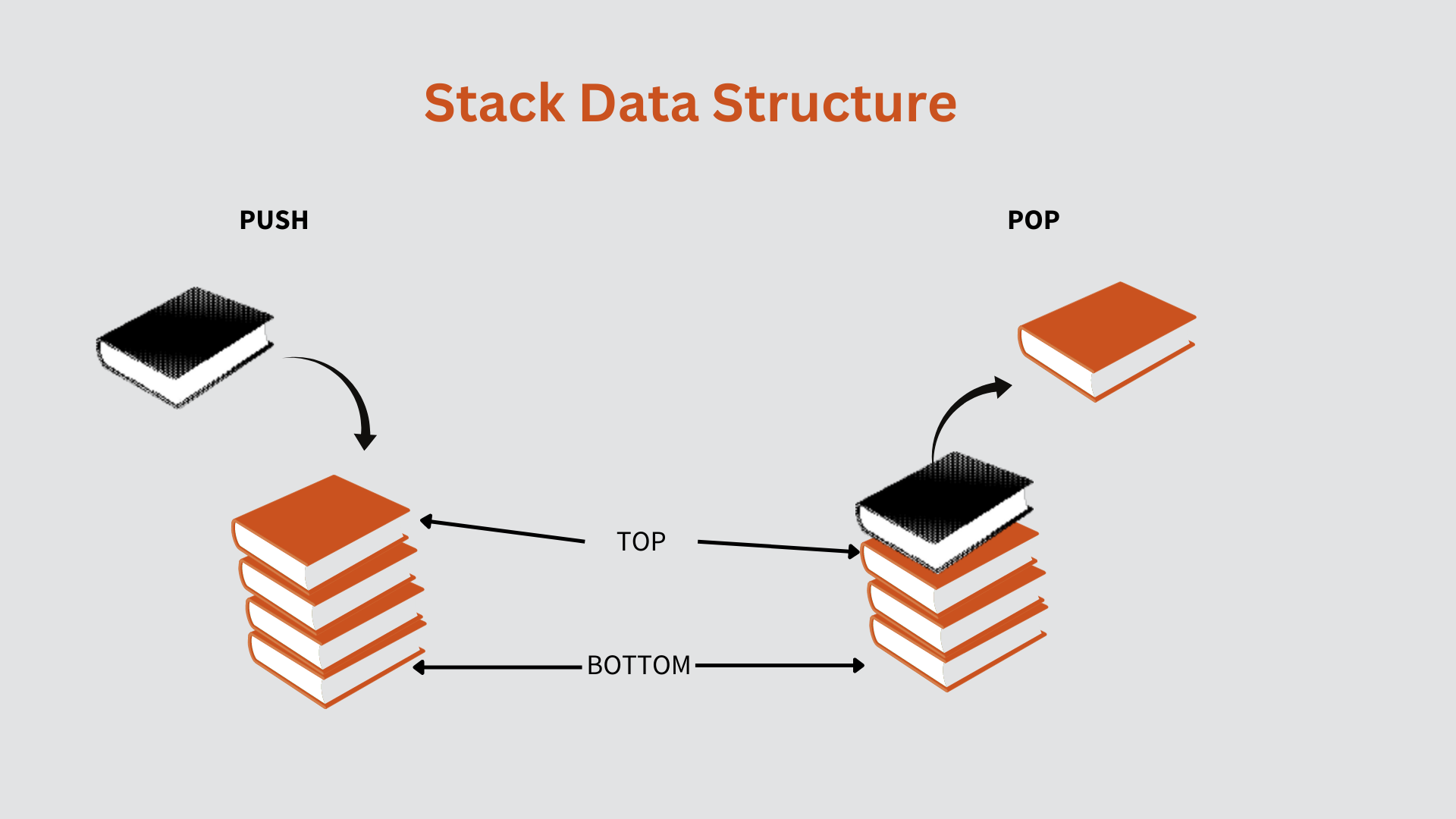
10. What is a stack? What are the applications of stack?
A stack is a linear data structure that accesses elements using the LIFO (Last In First Out) method.
A stack's basic operations are push, pop, isEmpty and top (or peek).
push() – used to insert element at top
pop() – removes the top element from stack
isEmpty() – returns true is stack is empty
peek() – to get the top element of the stack
Syntax : Stack var = new Stack(size);
All operation works in constant time i.e, O(1)
Advantages Of Stack
Maintains data in a LIFO manner
The last element is readily available for use
All operations are of O(1) complexity
Disadvantages Of Stack
Stack overflow can arise if you construct an excessive number of things on the stack.
The stack memory is finite.
A stack's data cannot be retrieved at random.
The following are some examples of stack applications:
In an expression, look for balanced parentheses.
A postfix expression is evaluated.
Conversion from infix to postfix is a problem.
Reverse a string of characters
11. What is a queue? What are the applications of queue?
A queue is a linear data structure that accesses elements in the FIFO (First In First Out) order.
A queue is defined as a list where every additions to the list occur at one end and all deletions occur at the other. The operation is done on the element that is first pushed into the order. Basic operations include
dequeue() : from the queue,
enqueue() : element to the queue,
getfront() : element of queue,
getrear() : element of queue.
Syntax :
Queue q1 = new LinkedList();
Queue q2 = new PriorityQueue();
All operation works in constant time i.e, O(1)
Advantages Of Queue
Maintains data in FIFO manner
Insertion from beginning and deletion from end takes O(1) time
Applications of Queue
Queues are beneficial in a variety of situations, including phone queries, reservation requests, traffic flow, and so on.
You may have heard "Please wait, you are in a QUEUE" while utilising a telephone directory service.
To gain access to resources such as printer queues, disc queues, and so on.
In specific data structures such as graphs and trees, for searching by breadth first.
For managing process scheduling in a multitasking operating system, such as FCFS (First Come, First Serve), Round-Robin, and so on.
Variations in Queue: Two popular variations of queues are Circular queues and Dequeues.
12. What is Graph Data Structure?
A graph is a non-linear data structure made up of vertices or nodes connected by edges or connections and used to store information.
Edges between nodes can be either directed or undirected.
A collection of a finite number of vertices known as nodes.
An edge that has a finite set of ordered pairs of the kind (e, v).
The letter V stands for the number of vertices.
The letter E represents the number of edges.
Syntax : BaseType (ParameterType) obj = new BaseType (ParameterType) ();
Different Categories Of Graph
Graph Data Structures in Java can be categorized on the basis of two parameters: direction and weight. 1. Direction : On the basis of direction, the graph can be categorized as a directed graph and an undirected graph.
2. Weight : On the basis of direction, the graph can be categorized as a Weighted graph and an Unweighted graph.
Advantages Of Graph
discovering connections
shortest route
minimum cost to travel from one point to another
Minimum tree span
Disadvantages Of Graph
Its large memory complexity.
Applications Of Graph
Graphs can be found in a wide range of applications. The following are a few of them:
To determine the flow of information in social networking websites such as Facebook, LinkedIn, and others, social network graphs are used.
Nodes represent neurons, while edges indicate synapses between them in neural network graphs.
Stations are the nodes and routes are the graph's edges in transport grids.
Graphs of power or water utility connections, with vertices representing connection sites and edges representing the cables or pipes that connect them.
Algorithms for finding the shortest distance between two end locations.
13. What is Tree Data Structure?
A tree is a recursive, non-linear data structure made up of a set of one or more data nodes, with one node serving as the root and the others serving as the root's progeny.
Data is organised in a hierarchical manner via a tree.
The binary tree and its variants are the most often used tree data structures.
Trees can be used for a variety of purposes, including:
Filesystems are folders within folders within folders within folders within folders within folders within folders within folders within folders within folders within folders within folders within folders within folders
Social media comments – comments, replies to comments, replies to replies, and so on — are represented as a tree.
The family hierarchy is represented through family trees, which include parents, grandparents, children, and grandchildren.
Some basic terms used in Tree data structure:- Root, Child node, Parent, Sibling , Leaf Node, Internal nodes, Ancestor node, Descendant.
Basic Operation On Tree:
Inserting an element.
Removing an element.
Searching for an element.
Traversing the tree.
Different Types of Tree Data Structure:-
1. Binary Tree
2. Binary Search Tree
3. AVL Tree
Advantages Of Tree
Data with a relationship can be represented.
Insertion and search are substantially faster.
Applications Of Tree
In a hierarchical system, trees are employed to store data. Consider the file system. The file system stored on the disc drive, the file and folder are inherently hierarchical data stored in the form of trees.
It is used to arrange data in order to make insertion, deletion, and searching more efficient. A binary tree, for example, has a logN time for searching for an element.
The dictionary is stored in a certain type of tree. It is a quick and efficient method of dynamic spell checking.
It, too, is a tree data structure constructed with arrays. Priority queues are implemented using it.
The data in routing tables in the routers are also stored using the tree data structure.
14. What is a heap data structure?
Heap is a non-linear data structure built on a tree with a complete binary tree as the tree.
A binary tree is said to be full if all levels are completely filled, with the exception of the last level, which has all elements pointing to the left as much as feasible. Basic operations of Heap :-
Heapify: the process of converting an array into a heap.
Insertion: the process of inserting an element into an existing heap with temporal complexity O. (log N).
Deletion: delete the top element of the heap or the element with the highest priority, then organise the heap and return the element with time complexity O. (log N).
Peek: to inspect or locate the heap's most recent constituent (max or min element for max and min heap).
There are two types of heaps:
Max-Heap: In a Max-Heap, the data element at the root node must be the most significant of all the data items in the tree.
This condition should be true for all sub-trees of that binary tree recursively.
Min-Heap: In a Min-Heap, the data element at the root node must be the smallest (or smallest) of all data elements in the tree.
Time Complexity:-
Depending on the height of the tree, the maximum heap requires a total of comparisons. Because the height of the whole binary tree is always logn, the time complexity is also O. (logn).
Advantages of Heap
There are two types: min heap and max heap.
The smallest element is kept in the min heap, while the largest is kept in the top and max heaps.
O(1) for interacting with minimum and maximum elements
Disadvantages of Heap
It is not feasible to gain access at random.
For accessibility, only the minimum and maximum elements are available.
Applications of Heap
Suitable for priority-related applications
The algorithm for scheduling
caching
15. What is a SET data structure?
A Set is a specific data structure in which duplicate values are not permitted. It is a very useful data structure, especially when we need to hold unique items, such as unique IDs.
The Java Collection API provides numerous implementations of Set, such as HashSet, TreeSet, and LinkedHashSet.
This interface inherits the Collection interface's methods and adds a feature that prevents the insertion of duplicate elements. SortedSet and NavigableSet are two interfaces that expand the set implementation. Declaration: The Set interface is declared as: public interface Set extends Collection Basic Operations on the Set Interface
1. Intersection: This operation returns all of the elements that are shared by the provided sets.
2. Union: This operation combines all of the elements in one set with all of the elements in the other.
3. The difference: This operation removes all of the values from one set from the other.
Advantages of Set
Set ensures that there are no duplicate objects in it.
Access times of O(logN) are often guaranteed by sets.
16. What is a Hashing data structure?
Hashing is a technique or procedure that uses a hash function to map keys and values into a hash table.
It is done to allow for quicker access to elements. The effectiveness of mapping is determined on the hash algorithm employed.
This provides constant-time access Collision resolution techniques
handle collision
Chaining
Open Addressing
There are 3 important operations in Hashing:- Key, Hashing Function and Hashing Value.
Advantages of Hashing
The hash function aids in retrieving elements in a consistent amount of time.
An effective method of storing elements
Advantages of Hashing
Collision resolution adds to the complexity.
Application of Hashing
Suitable for applications that require continual time retrieval.
17. How linear data structures differ from non-linear data structures in Java?
A linear data structure is one in which the data structure's elements produce a sequence or a linear list.
Non-linear data structures, on the other hand, traverse nodes in a non-linear fashion.
Linear data structures include lists, stacks, and queues, whereas non-linear data structures include graphs and trees.
18. What is a multidimensional array?
Data structures that span more than one dimension are known as multi-dimensional arrays.
This means that for each storage location, there will be several index variables.
This data structure is most commonly employed when data cannot be described or stored using only one dimension.
2D arrays are the most often used multidimensional arrays.
2D arrays mimic the tabular form structure, making it simple to store large amounts of data that can be accessed via row and column pointers.
19. How you can find the smallest and the largest element in the array?
Set up two variables. using arr[0] greatest and smallest
Iterate through the array
If the current element is greater than the largest, the current element will be assigned to the largest.
If the current element is smaller than the smallest, it should be assigned to the smallest.
In the end, you'll have the smallest and largest element.
public class Main {
public static void main(String[] args) {
//array of 8 numbers
int arr[] = new int[]{10, 1190, 67, 46, 7, 46, 234};
//assign first element of an array to largest and smallestint smallest = arr[0];
int largest = arr[0];
for(int i=1; i< arr.length; i++)
{
if(arr[i] > largest)
largest = arr[i];
else if (arr[i] < smallest)
smallest = arr[i];
}
System.out.println("Smallest Number is : " + smallest);
System.out.println("Largest Number is : " + largest);
}
}
20. Explain the scenarios where you can use linked lists and arrays.
The following are some circumstances in which we would prefer to utilise a linked list over an array:
When we don't know how many elements there will be ahead of time.
When we know there will be a significant number of actions to add or remove.
There are fewer random access operations.
A linked list is better for inserting items anywhere in the middle of a list, such as when building a priority queue.
The following are examples of where we would prefer to use arrays over a linked list:
When we need to index or access elements at random more often.
When we know how many elements are in the array ahead of time, we can allocate the appropriate amount of memory.
When we need to iterate over the sequence's elements quickly.
When your memory is a problem:
Because of the differences between arrays and linked lists, it's safe to assume that filled arrays consume less memory than linked lists.
Each array member represents only the data, but each linked list node contains both the data and one or more pointers or references to the other linked list components.
To recapitulate, when picking which data structure to utilise over what, space, time, and ease of implementation are all taken into account.
21. How can you find the missing number in the array if array contain 1 to n numbers?
Using the formula n=n*(n+1)/2, get the sum of n numbers.
Find the total number of elements in the provided array.
Subtract (sum of n numbers – total number of elements in the array) from the total number of elements in the array.
class Main{
public static void main(String[] args) {
int[] arr1={7,5,6,1,4,2};
System.out.println("Missing number is: "+missingNumber(arr1));
}
public static int missingNumber(int[] arr)
{
int n=arr.length+1;
int sum=n*(n+1)/2;
int sum2=0;
for (int i = 0; i < arr.length; i++) {
sum2+=arr[i];
}
int num=sum-sum2;
return num;
}
}
22. What is a doubly-linked list (DLL)? What are its applications?
This is a more complicated sort of linked list in which each node contains two references: one that connects to the next node in the sequence, and the other that connects to the previous node in the sequence.
Another node that is linked to the previous one. The data pieces can be traversed in both ways using this structure (left to right and vice versa).
DLL has the following uses:
A music playlist with navigation choices for the next and previous songs.
BACK-FORWARD viewed pages in the browser cache
On platforms like as Word, Paint, and others, the undo and redo functionality allows you to go back to the previous page by reversing the node.
23. Difference between .length and .length()
A common "gotcha" question is the difference between.length and.length().
.length returns the number of elements in an array.
.length() returns the number of characters in a string.
24. Is an array a linear data structure?
Because each element is connected to the ones before and after it, an array is a linear data structure.
25. What is the default value in boolean and integer arrays?
Boolean : false
Integer : 0
26. Merge Two Sorted Array
class Main {
public static int[] mergeArrays(int[] arr1, int[] arr2) {
int s1 = arr1.length;
int s2 = arr2.length;
int[] resultantArray = new int[s1+s2];
int i = 0, j = 0, k = 0;
while (i < s1 && j < s2) {
if (arr1[i] < arr2[j])
resultantArray[k++] = arr1[i++];
else
resultantArray[k++] = arr2[j++];
}
while (i < s1)
resultantArray[k++] = arr1[i++];
while (j < s2)
resultantArray[k++] = arr2[j++];
return resultantArray;
}
public static void main(String args[]) {
int[] arr1 = {10,12,15,17,23};
int[] arr2 = {11,18, 27};
int[] resultantArray = mergeArrays(arr1, arr2);
System.out.print("Arrays after merging: ");
for(int i = 0; i < arr1.length + arr2.length; i++) {
System.out.print(resultantArray[i] + " ");
}
}
}
The best way to tackle this problem is to sort the array first.
QuickSort is used to sort the array first.
Then utilising two variables, one starting from the array's initial index and the other starting from the array's size1 index.
If the sum of the elements on these array indexes is less than the supplied value n, increase index from the beginning; otherwise, decrement index from the end until the given value n equals the sum.
Return the result array containing the elements at these indexes.
28. How does HashMap handle collisions in Java?
The java.util package is a collection of utilities for Java.
To handle collisions, the HashMap class in Java employs a chaining technique.
If new values with the same key are attempted to be pushed, these values are stored in a linked list stored in the key's bucket as a chain along with the existing value in chaining.
In the worst-case scenario, all keys may have the same hashcode, resulting in the hash table being converted into a linked list.
Due to the nature of the linked list, searching for a value will require O(n) time rather than O(1) time in this example.
As a result, caution must be given while choosing a hashing algorithm.
29. What is the time complexity of basic operations get() and put() in HashMap class?
If the hash function employed in the hash map distributes elements uniformly among the buckets, the time complexity is O(1).
30. Which data structures are used for implementing LRU cache?
The LRU cache, or Least Recently Used cache, organises objects in order of use to make it easier to find an element that hasn't been used in a long time.
Two data structures are utilised to do this:
A doubly-linked list is used to implement the queue.
The cache size, i.e. the total number of available frames, determines the queue's maximum size.
The pages that have been used the least lately will be near the front of the queue, while the pages that have been used the most recently will be near the back.
The page number is stored as the key, while the address of the matching queue node is stored as the value, in a hashmap.
31. Rearrange Positive & Negative Values
class Main
{
public static void arrange(int[] arr)
{
int j = 0;
for (int i = 0; i < arr.length; i++) {
if (arr[i] < 0) {
if (i != j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
j++;
}
}
}
public static void main(String args[]) {
int[] arr = {2, 4, -6, 8, -5, -10};
arrange(arr);
System.out.print("Array after rearranging: ");
for(int i = 0; i < arr.length; i++)
System.out.print(arr[i] + " ");
}
}
Rather than creating a new array, this technique rearranges the components within the existing one.
Two variables, I and j, are used to accomplish this.
Initially, both are zero.
It maintains track of where the next encountered negative integer will be placed while I iterates over the array.
When a negative integer is encountered, the values at the I and j indices are swapped, and j is increased.
This process continues until the array's end is reached.
32. Right Rotate the Array by One Index in Java
class Main
{
public static void rotate(int[] arr) {
int lastElement = arr[arr.length - 1];
for (int i = arr.length - 1; i > 0; i--) {
arr[i] = arr[i - 1];
}
arr[0] = lastElement;
}
public static void main(String args[]) {
int[] arr = {3, 6, 1, 8, 4, 2};
rotate(arr);
System.out.print("Array after rotation: ");
for(int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}
To rotate the array to the right, we need to move the array elements one index to the right.
This signifies that every element at index i will be relocated to index i + 1.
If we begin moving elements from the first element of the array, the element at the end index arr[arr.length - 1] will be overwritten.
This is fixed by storing the array's last element in the variable lastElement.
Then we begin shifting elements from index i - 1 to I with arr.length - 1 as the initial value of I and we continue shifting elements until i is larger than 0.
We save the value of lastElement in arr[0] after the loop terminates.
33. What is the difference between Arrays and Linked Lists?
The size of a linked list is determined at runtime as you add or remove entries, rather than when it is first created.
Once an array is initialised, its size is fixed.
34. Write a function to Traverse a linked list in Java
This iterates through the list.
The first element of the list is stored in curr, and then the list is traversed until the end is reached.
35. What are circular Linked list?
The linked list's final entry forms a circle by pointing to the first.
The list can only be navigated in one way, but it does so again after the last piece.
36. Are elements in a linked list stored consecutively in memory?
They can be, but they don't have to be.
A linked list's elements are stored as pointers, which means they don't have to be placed next to each other to be found.
However, by coincidence, two items may be kept in the same order.
37. Search in a Singly Linked List
class Main {
public static void main(String args[]) {
SinglyLL<Integer> sll = new SinglyLL<Integer>();
for (int i = 1; i <= 10; i++) {
sll.insertAtEnd(i);
}
if(sll.searchNode(3)) {
System.out.println("Value: 5 is Found");
}
else {
System.out.println("Value: 5 is not Found");
}
}
}
We walk the list in this method and see if the curr node value of data matches the searched value data.
We'll return True if it does. Otherwise, False will be returned.
38. Return the Nth node from End in Java Language
public static<T> Object nthFromEnd(SinglyLinkedList<T> sl, int n) {
int size = sl.getSize();
n = size - n + 1;
if (size == 0 || n > size) {
return null;
}
SinglyLinkedList.Node curr = sl.getHeadNode();
int count = 1;
while (curr != null) {
if (count == n)
return curr.data;
count++;
curr = curr.nextNode;
}
return null;
}
public static void main( String args[] ) {
SinglyLinkedList<Integer> sll = new SinglyLinkedList<Integer>();
sll.printList();
for(int i=0; i<15; i+=2){
sll.insertAtHead(i);
}
sll.printList();
System.out.println("10th element from end : " + nthElementFromEnd(sll, 10));
}
}
The getter function list is used first in the above solution.
To find out how long a list is, use getSize().
Then we use the equation to locate the node that is at x position from the beginning:
Position=size−n+1
Position = size - n + 1
Position=size−n+1
39. What is one advantage of the data type’s immutable property?
Here are some possible responses:
Strings are thread-safe because they are immutable.
It conserves heap memory.
Assists in the maintenance of string-key hash structures.
Secures string-based authentication, such as ClassLoading, which takes a string as an argument.
40. Reverse a Linked List
class Reverse {
public static void main( String args[] ) {
SinglyLinkedList<Integer> list = new SinglyLinkedList<Integer>();
for(int i = 0; i < 15; i+=2)
list.insertAtEnd(i);
list.printList();
}
public static <T> void reverse(SinglyLinkedList<T> list){
SinglyLinkedList<T>.Node previous = null;
SinglyLinkedList<T>.Node curr = list.headNode;
SinglyLinkedList<T>.Node next = null;
while (curr != null) {
next = curr.nextNode;
curr.nextNode = previous;
previous = curr;
curr = next;
}
list.headNode = previous;
}
}
The key to this solution is the loop that iterates through the list.
The link between any current node and the previous node is reversed, and the variable next is used to record the next node in the list:
nextNode stores the current node's nextNode. Set the nextNode property of the current node to prior (reversal)
Make the current node the new prior in order to use it in the following iteration. Next will take you to the next node.
Finally, we simply point the head to the loop's last node.
41. Can you create a mutable string in Java? If so, how?
Either the StringBuilder or StringBuffer classes can be used.
StringBuffer is thread-safe, whereas StringBuilder is not.
42. Where are strings stored in memory?
Within heap memory, there is a string constant pool.
43. What is the difference between equals() method and == operator?
The equals() function compares the value to the string's content, whereas the == method compares the value to the string's object or reference.
44. Reverse Words in a Sentence
class Reverse {
public static void strRev(char[] str, int start, int end) {
if (str == null || str.length < 2) {
return;
}
while (start < end) {
char temp = str[start];
str[start] = str[end];
str[end] = temp;
start++;
end--;
}
}
public static void reverseWords(char[] sentence) {
if (sentence == null || sentence.length == 0) {
return;
}
int len = sentence.length;
strRev(sentence, 0, len - 2);
int start = 0;
int end;
while (true) {
while (sentence[start] == ' ') {
++start;
}
if (start >= sentence.length - 1) {
break;
}
end = start + 1;
while (end < sentence.length - 1 && sentence[end] != ' ') {
++end;
}
strRev(sentence, start, end - 1);
start = end;
}
}
static char[] getArray(String t) {
char[] s = new char[t.length() + 1];
int i = 0;
for (; i < t.length(); ++i) {
s[i] = t.charAt(i);
}
return s;
}
public static void main(String[] args) {
char[] s = getArray("Hello World!");
System.out.println(s);
reverseWords(s);
System.out.println(s);
}
}
This is accomplished in two steps.
First, we reverse all of the characters in the string, making the last character the first.
The last word will now come first, but the word will be in reverse order as well.
The reversed string is then traversed, and each word is reversed in situ.
Each word's letters will be in the correct order, but the position of each word will remain reversed from the provided string.
45. Longest Substring with K Distinct Characters
import java.util.*;class Main {
public static int findLength(String str, int k) {
if (str == null || str.length() == 0 || str.length() < k)
throw new IllegalArgumentException();
int windowStart = 0, maxLength = 0;
Map<Character, Integer> charFrequencyMap = new HashMap<>();
for ( int windowEnd = 0; windowEnd < str.length(); windowEnd++) {
char rightChar = str.charAt(windowEnd);
charFrequencyMap.put(rightChar, charFrequencyMap.getOrDefault(rightChar, 0) + 1);
while (charFrequencyMap.size() > k) {
char leftChar = str.charAt(windowStart);
charFrequencyMap.put(leftChar, charFrequencyMap.get(leftChar) - 1);
if (charFrequencyMap.get(leftChar) == 0) {
charFrequencyMap.remove(leftChar);
}
windowStart++;
}
maxLength = Math.max(maxLength, windowEnd - windowStart + 1);
}
return maxLength;
}
public static void main(String[] args) {
System.out.println("Length of the longest substring: " + LongestSubstringKDistinct.findLength("araaci", 2));
}
}
The Sliding Window pattern is used in this problem.
To remember the frequency of each character we've processed, we can use a HashMap.
First, we'll start inserting characters from the beginning of the string until the HashMap has K distinct characters.
Our sliding window will be these characters.
The goal is to discover the window with the fewest number of distinct characters.
The length of this window will be remembered as the longest so far.
Then, in the sliding window, we'll keep adding one character at a time (i.e., slide the window ahead).
If the number of different characters in the HashMap is greater than K, we shall try to decrease the window from the beginning of each iteration.
We'll keep shrinking the scope until the HashMap contains no more than K distinct characters.
We'll decrement the character's frequency as it shrinks, and if its frequency reaches 0, we'll remove it from the HashMap.
We'll check at the conclusion of each step to see if the current window length is the longest so far, and if it is, we'll remember it.
46. Print All Combinations of Balanced Braces
class Braces{
static void print(ArrayList<ArrayList> arr) {
for (int i = 0; i < arr.size(); i++) {
System.out.println(arr.get(i).toString());
}
}
static void printAllBacesRec(
int n,
int leftCount,
int rightCount, ArrayList<Character> output,
ArrayList<ArrayList<Character>> result) {
if (leftCount >= n && rightCount >=n) {
result.add((ArrayList)output.clone());
}
if (leftCount < n) {
output.add('{');
printAllBacesRec(n, leftCount + 1, rightCount, output, result);
output.remove(output.size() - 1);
}
if (rightCount < leftCount) {
output.add('}');
printAllBacesRec(n, leftCount, rightCount + 1, output, result);
output.remove(output.size() - 1);
}
}
public static void main(String[] args) {
ArrayList<ArrayList<Character>> result = new ArrayList<ArrayList<Character>>();
result = printAllBraces(3);
print (result);
}
}
A recursive strategy is the key to this solution.
We'll keep track of the left braces and right braces variables.
We'll check each iteration to see if the left braces count is less than n.
If the answer is affirmative, we add to the left braces and on to the next stage.
We'll add to right braces and recurse if right braces is smaller than left braces.
When both left braces and right braces equal n, the recursion process is terminated.
47. Can we store a duplicate key in HashMap?
No, HashMap does not allow duplicate keys.
If you try to insert a new value with an existing key, the old value will be overwritten.
The size of HashMap will not change as a result of this.
Because Java does not allow duplicates, the keySet() function returns all keys as a SET.
48. Write a recursive function to calculate the height of a binary tree in Java.
int height(Node root)
{
if (root == null)
return 0;
else
{
int lh = height(root.left);
int rh = height(root.right);
return Math.max(lh, rh) + 1;
}
}
49. Write Java code to count number of nodes in a binary tree.
int count(Node root)
{
if (root == null)
return 0;
else
{
int lh = count(root.left);
int rh = count(root.right);
return lh+rh+ 1;
}
}
50. What is an AVL Tree?
BST is height balanced by AVL trees.
The height of the left and right sub-trees is checked by the AVL tree, which ensures that the difference is less than one.
This distinction is known as the Balance Factor, and it is calculated as.
height(left subtree) + height(right subtree) + height(right subtree) + height(right subtree) + height(right subtre (right subtree)
51. What is the difference between the Breadth First Search (BFS) and Depth First Search (DFS)?
The traversing methods for a graph are BFS and DFS.
The process of visiting all of the nodes in a graph is known as graph traversal.
BFS explores level by level, whereas DFS takes a path from the beginning to the end node, then another path from the beginning to the end, and so on until all nodes are visited.
Furthermore, BFS stores nodes in a queue data structure, whereas DFS implements node traversal using a stack data structure.
DFS produces deeper, non-optimal answers, although it works well when the solution is dense, whereas BFS solutions are optimal.
Conclusion
Data structures are important for efficiently storing and arranging data.
In the preceding article, we explored some fundamental Java Data Structures such as arrays, linked lists, stacks, queues, graphs, and sets, as well as their types, implementations, and examples.
This article will undoubtedly assist you in your future Java programming endeavours.
Thank you for taking the time to read our article. If you have any questions about Data Structures in Java, please do read other articles related to this or contact us.
Data Structures in Java Frequently Asked Questions
Q: What are the key data structures available in Java ?
Java is a sophisticated and flexible programming language that provides a wide variety of data structures to meet the needs of different applications. These structures are inherently complex and versatile, making the management and manipulation of data using them a blend of intricacy and burstiness.
1. Arrays: To begin, we have arrays, the most elementary data structure, which keep together in memory a set number of objects of the same kind. Arrays, which can have one or more dimensions, are a straightforward and effective data representation format.
2. LinkedList: As a dynamic data structure, a LinkedList is a set of nodes that each have a pointer to the following node in the list. This data structure is superior to arrays in cases when data is regularly added and removed since no element shifting is required.
3. Stack: Last-In-First-Out (LIFO) is embodied by the Stack data structure, which stores items in a linear order and permits insertions and removals only from the top. Expression parsing, algorithm implementation, and function call management are all common uses for stacks.
4. Queue: In contrast to stacks, queues delete the oldest item from the sequence first (in accordance with the First-In-First-Out (FIFO) concept). Queues are commonly used for work scheduling and resource management in computer systems.
5. ArrayList: When elements are added or removed from an ArrayList, the size of the array automatically changes to accommodate the new or old data. Accessing elements in an ArrayList takes constant time, but extending the list could slow down inserts and deletes.
6. HashSet: HashSet, which stores and retrieves its elements via hashing, is defined as "a collection of unique elements." HashSets, which have no predetermined order and provide constant-time operations for adding, removing, and searching components, are great for situations where it is important to avoid storing duplicate data.
7. HashMap: HashMap is a key-value pair store that uses hashing to quickly look up values given their associated keys. When it comes to enforcing associative arrays or dictionaries, HashMaps shine.
8. TreeMap:Using either the keys' natural ordering or a user-defined comparator, a TreeMap keeps its key-value pairs in ascending or descending order. When information must be retrieved in a specified order or range, this structure is the best option.
9. PriorityQueue: A PriorityQueue sorts its contents by priority, providing quick access to the item with the highest or lowest priority. PriorityQueues are frequently used in scheduling algorithms to guarantee that the most important jobs run first.
To sum up, Java's variety of data structures serves a wide variety of uses and provides unique benefits in various situations. These structures, ranging from the static Array to the dynamic TreeMap, let programmers manage data efficiently and effectively while showing the needed complexity and dynamism.
Q: How do I choose the right data structure for my Java program?
Choosing the right data structure for your Java program depends on various factors, such as the specific use case, performance requirements, memory constraints, and readability.
Here are some general guidelines to help you make the right choice:
1. Analyze the requirements: Understand the problem you are trying to solve and identify the operations that will be performed most frequently. This will help you decide which data structure can provide the best performance for your specific use case.
2. Consider the performance characteristics: Different data structures have different performance characteristics, such as time complexity for insertion, deletion, and search operations. Choose a data structure that offers the best performance for the operations that are most critical to your application.
3. Think about memory constraints: Some data structures consume more memory than others. If memory usage is a concern, choose a data structure that is more memory-efficient.
4. Evaluate the ease of use and readability: Some data structures are easier to use and understand than others. If readability and maintainability are important factors, choose a data structure that is simple and easy to work with.
Here are some general suggestions for common use cases:
1. For a simple, fixed-size collection of elements, use an array.
2. If you need a dynamic, resizable collection that supports random access, use an ArrayList.
3. If you need a dynamic, resizable collection that supports fast insertion and deletion, use a LinkedList.
4. If you need an ordered collection without duplicate elements, use a TreeSet or a SortedSet.
5. If you need an unordered collection without duplicate elements and with fast insertion, deletion, and search operations, use a HashSet.
6. If you need a collection that maintains the insertion order without duplicate elements, use a LinkedHashSet.
7. If you need a key-value pair collection with fast insertion, deletion, and search operations, use a HashMap.
8. If you need a key-value pair collection with ordered keys, use a TreeMap or a SortedMap.
9. If you need a key-value pair collection that maintains the insertion order, use a LinkedHashMap.
10. If you need a first-in, first-out (FIFO) queue, use a LinkedList (as a Queue) or an ArrayDeque.
11. If you need a priority queue with efficient access to the smallest or highest priority element, use a PriorityQueue.
12. If you need a double-ended queue (Deque) with fast insertion and deletion operations at both ends, use a LinkedList (as a Deque) or an ArrayDeque.
Remember that these are general guidelines, and the best choice for your specific situation might differ. Always consider the unique requirements of your program when selecting a data structure. Additionally, don't hesitate to refactor your code and switch to a different data structure if you find that it better suits your needs"
rewrite like human
Q : What are the main types of data structures in Java ?
In Java, the main types of data structures can be categorized into the following categories:
Linear Data Structures:
1. Arrays: A fixed-size, contiguous block of memory that stores elements of the same data type.
2. ArrayLists: A dynamic-sized, resizable array implementation in Java, part of the Java Collections Framework.
3. LinkedLists: A data structure that stores elements as nodes, with each node containing a reference to the next node.
4. Stacks: A last-in, first-out (LIFO) data structure that supports push and pop operations.
5. Queues: A first-in, first-out (FIFO) data structure that supports enqueue and dequeue operations.
Non-Linear Data Structures:
Trees: A hierarchical data structure with a root node and child nodes branching out in a tree-like structure.
Binary Trees: A tree data structure in which each node has at most two children, typically referred to as the left and right child.
Binary Search Trees: A binary tree with the property that the value of each node is greater than or equal to all the values in its left subtree and less than or equal to all the values in its right subtree.
AVL Trees, Red-Black Trees, etc.: Self-balancing binary search trees that maintain their balance through rotation or recoloring operations.
Graphs: A data structure that consists of a finite set of vertices (nodes) and a finite set of edges connecting the vertices.
Hash-based Data Structures:
HashSet: An unordered collection of unique elements that uses hashing to store and retrieve elements efficiently.
HashMap: An unordered collection of key-value pairs that uses hashing to enable efficient retrieval of values based on their keys.
LinkedHashMap and LinkedHashSet: Similar to HashMap and HashSet, but maintain the insertion order of elements.
Set-based Data Structures:
TreeSet: A sorted, unique set of elements based on a binary search tree implementation.
EnumSet: A specialized set implementation for elements of an enumerated type.
Other Collections Framework Data Structures:
PriorityQueue: A data structure that allows efficient access to the highest or lowest priority element.
Deque: A double-ended queue that allows elements to be added or removed from both ends.